Computes the transpose of a matrix, a matrix-vector product, or a matrix-matrix product for all matrices stored in sparse coordinate form.
Synopsis
#include <imsl.h>
void *imsl_f_mat_mul_rect_coordinate (char *string, ..., 0)
The equivalent double function is imsl_d_mat_mul_rect_coordinate.
Required Arguments
char *string
(Input)
String indicating matrix multiplication to be performed.
Return Value
The returned value is the result of the multiplication. If the result is a vector, the return type is pointer to float. If the result of the multiplication is a sparse matrix, the return type is pointer to Imsl_f_sparse_elem. To release this space, use free.
Synopsis with Optional Arguments
#include <imsl.h>
void
*imsl_f_mat_mul_rect_coordinate (char *string,
IMSL_A_MATRIX,
int nrowa, int ncola, int nza,
Imsl_f_sparse_elem *a,
IMSL_B_MATRIX, int nrowb, int
ncolb, int nzb, Imsl_f_sparse_elem
*b,
IMSL_X_VECTOR, int nx, float
*x,
IMSL_RETURN_MATRIX_SIZE, int *size,
IMSL_RETURN_USER_VECTOR,
float vector_user[],
0)
Optional Arguments
IMSL_A_MATRIX, int nrowa, int ncola, int nza,
Imsl_f_sparse_elem *a
(Input)
The sparse matrix
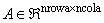
with nza nonzero elements.
IMSL_B_MATRIX, int nrowb, int ncolb, int nzb,
Imsl_f_sparse_elem *b
(Input)
The sparse matrix
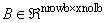
with nzb nonzero elements.
IMSL_X_VECTOR, int nx, float *x,
(Input)
The vector x of length nx.
IMSL_RETURN_MATRIX_SIZE, int *size,
(Output)
If the function imsl_f_mat_mul_rect_coordinate
returns a vector of type Imsl_f_sparse_elem, use this option to retrieve
the length of the return vector, i.e. the number of nonzero elements in the
sparse matrix generated by the requested computations.
IMSL_RETURN_USER_VECTOR, float
vector_user[], (Output)
If the result of the computation
in a vector, return the answer in the user supplied sparse vector_user. It’s size
depends on the computation.
Description
The function imsl_f_mat_mul_rect_coordinate computes a matrix-matrix product or a matrix-vector product, where the matrices are specified in coordinate representation. The operation performed is specified by string. For example, if “A*x” is given, Ax is computed. In string, the matrices A and B and the vector x can be used. Any of these names can be used with trans, indicating transpose. The vector x is treated as a dense n ´ 1 matrix.
If string contains only one item, such as “x” or “trans(A)”, then a copy of the array, or its transpose is returned. Some multiplications, such as “A*trans(A)” or “trans(x)*B”, will produce a sparse matrix in coordinate format as a result. Other products such as “B*x” will produce a pointer to a floating type, containing the resulting vector.
The matrices and/or vector referred to in string must be given as optional arguments. Therefore, if string is “A*x”, then IMSL_A_MATRIX and IMSL_X_VECTOR must be given.
Examples
Example 1
In this example, a sparse matrix in coordinate form is multipled by a vector.
#include <imsl.h>
main()
{
Imsl_f_sparse_elem a[] = {0, 0, 10.0,
1, 1, 10.0,
1, 2, -3.0,
1, 3, -1.0,
2, 2, 15.0,
3, 0, -2.0,
3, 3, 10.0,
3, 4, -1.0,
4, 0, -1.0,
4, 3, -5.0,
4, 4, 1.0,
4, 5, -3.0,
5, 0, -1.0,
5, 1, -2.0,
5, 5, 6.0};
float b[] = {10.0, 7.0, 45.0,
33.0, -34.0, 31.0};
int n = 6;
int nz = 15;
float *x;
/* Set x = A*b */
x =
imsl_f_mat_mul_rect_coordinate ("A*x",
IMSL_A_MATRIX, n, n, nz, a,
IMSL_X_VECTOR, n, b,
0);
imsl_f_write_matrix ("Product Ab", 1, n, x, 0);
}
Output
Product Ab
1 2 3 4 5 6
100 -98 675 344 -302 162
Example 2
This example uses the power method to determine the dominant eigenvector of E(100, 10). The same computation is performed by using imsl_f_eig_sym. The iteration stops when the component-wise absolute difference between the dominant eigenvector found by imsl_f_eig_sym and the eigenvector at the current iteration is less than the square root of machine unit roundoff.
#include <imsl.h>
#include <math.h>
void main()
{
int i;
int n;
int c;
int nz;
int index;
Imsl_f_sparse_elem *a;
float *z;
float *q;
float *dense_a;
float *dense_evec;
float *dense_eval;
float norm;
float *evec;
float error;
float tolerance;
n = 100;
c = 10;
tolerance = sqrt(imsl_f_machine(4));
error = 1.0;
evec = (float*) malloc (n*sizeof(*evec));
z = (float*) malloc (n*sizeof(*z));
q = (float*) malloc (n*sizeof(*q));
dense_a = (float*) calloc (n*n, sizeof(*dense_a));
a = imsl_f_generate_test_coordinate (n, c, &nz, 0);
/* Convert to dense format */
for (i=0;
i<nz; i++)
dense_a[a[i].col + n*a[i].row] = a[i].val;
/* Determine dominant eigenvector by a dense method */
dense_eval =
imsl_f_eig_sym (n, dense_a,
IMSL_VECTORS, &dense_evec,
0);
for (i=0; i<n; i++) evec[i] = dense_evec[n*i];
/* Normalize */
norm =
imsl_f_vector_norm (n, evec, 0);
for (i=0; i<n; i++) evec[i] /= norm;
for (i=0;
i<n; i++) q[i] = 1.0/sqrt((float) n);
/* Do power method */
while (error
> tolerance) {
imsl_f_mat_mul_rect_coordinate ("A*x",
IMSL_A_MATRIX, n, n, nz, a,
IMSL_X_VECTOR, n, q,
IMSL_RETURN_USER_VECTOR, z,
0);
/* Normalize */
norm = imsl_f_vector_norm (n, z, 0);
for (i=0; i<n; i++) q[i] = z[i]/norm;
/* Compute maximum absolute error between any
two elements */
error = imsl_f_vector_norm (n, q,
IMSL_SECOND_VECTOR, evec,
IMSL_INF_NORM, &index,
0);
}
printf ("Maximum absolute error = %e\n", error);
}
Output
Maximum absolute error = 3.368035e-04
|
Visual Numerics, Inc. PHONE: 713.784.3131 FAX:713.781.9260 |