.p>.CSCH5.DOC!CONTINGENCY_TABLE;contingency_table
Performs a chi-squared analysis of a two-way contingency table.
Synopsis
#include <imsls.h>
float imsls_f_contingency_table (int n_rows, int n_columns, float table[], ..., 0)
The type double function is imsls_d_contingency_table.
Required Arguments
int
n_rows (Input)
Number of rows in the
table.
int
n_columns (Input)
Number of columns in the
table.
float
table[] (Input)
Array of length
n_rows × n_columns containing the observed
counts in the contingency table.
Return Value
Pearson chi-squared p-value for independence of rows and columns.
Synopsis with Optional Arguments
#include <imsls.h>
float
imsls_f_contingency_table (int
n_rows,
int
n_columns,
float table[],
IMSLS_CHI_SQUARED, int *df, float
*chi_squared,
float *p_value,
IMSLS_LRT, int *df, float
*g_squared, float
*p_value,
IMSLS_EXPECTED, float
**expected,
IMSLS_EXPECTED_USER, float expected[],
IMSLS_CONTRIBUTIONS, float **chi_squared_contributions,
IMSLS_CONTRIBUTIONS_USER,
float chi_squared_contributions[],
IMSLS_CHI_SQUARED_STATS, float
**chi_squared_stats,
IMSLS_CHI_SQUARED_STATS_USER,
float
chi_squared_stats[],
IMSLS_STATISTICS, float
**statistics,
IMSLS_STATISTICS_USER, float
statistics[],
0)
Optional Arguments
IMSLS_CHI_SQUARED, int *df, float *chi_squared, float *p_value
(Output)
Argument df is the degrees of
freedom for the chi-squared tests associated with the table, chi_squared is the
Pearson chi-squared test statistic, and argument p_value is the
probability of a larger Pearson chi-squared.
IMSLS_LRT, int *df, float *g_squared, float *p_value
(Output)
Argument df is the degrees of
freedom for the chi-squared tests associated with the table, argument g_squared is the
likelihood ratio G2 (chi-squared), and argument p_value is the
probability of a larger G2.
IMSLS_EXPECTED, float
**expected (Output)
Address of a pointer to the internally
allocated array of size (n_rows + 1) × (n_columns + 1)
containing the expected values of each cell in the table, under the null
hypothesis, in the first n_rows rows and n_columns columns. The
marginal totals are in the last row and column.
IMSLS_EXPECTED_USER, float expected[]
(Output)
Storage for array expected is provided
by the user. See IMSLS_EXPECTED.
IMSLS_CONTRIBUTIONS, float **chi_squared_contributions
(Output)
Address of a pointer to an internally allocated array of size (n_rows + 1) × (n_columns + 1)
containing the contributions to chi-squared for each cell in the table in the
first n_rows
rows and n_columns columns. The
last row and column contain the total contribution to chi-squared for that row
or column.
IMSLS_CONTRIBUTIONS_USER, float chi_squared_contributions[]
(Output)
Storage for array chi_squared_contributions
is provided by the user. See IMSLS_CONTRIBUTIONS.
IMSLS_CHI_SQUARED_STATS, float
**chi_squared_stats (Output)
Address of a pointer to an
internally allocated array of length 5 containing chi-squared statistics
associated with this contingency table. The last three elements are based on
Pearson’s chi-square statistic (see IMSLS_CHI_SQUARED).
The chi-squared statistics are given as follows:
|
Element |
Chi-squared Statistics |
|
0 |
exact mean |
|
1 |
exact standard deviation |
|
2 |
Phi |
|
3 |
contingency coefficient |
|
4 |
Cramer’s V |
IMSLS_CHI_SQUARED_STATS_USER, float
chi_squared_stats[] (Output)
Storage for array chi_squared_stat is
provided by the user. See IMSLS_CHI_SQUARED_STATS.
IMSLS_STATISTICS, float
**statistics (Output)
Address of a pointer to an
internally allocated array of size 23 × 5 containing statistics
associated with this table. Each row corresponds to a statistic.
|
Row |
Statistic |
|
0 |
Gamma |
|
1 |
Kendall’s τb |
|
2 |
Stuart’s τc |
|
3 |
Somers’ D for rows (given columns) |
|
4 |
Somers’ D for columns (given rows) |
|
5 |
product moment correlation |
|
6 |
Spearman rank correlation |
|
7 |
Goodman and Kruskal τ for rows (given columns) |
|
8 |
Goodman and Kruskal τ for columns (given rows) |
|
9 |
uncertainty coefficient U (symmetric) |
|
10 |
uncertainty Ur | c (rows) |
|
11 |
uncertainty Uc |r (columns) |
|
12 |
optimal prediction λ (symmetric) |
|
13 |
optimal prediction λr|c (rows) |
|
14 |
optimal prediction λc|r (columns) |
|
15 |
optimal prediction λr|c (rows) |
|
16 |
optimal prediction λc|r (columns) |
|
17 |
test for linear trend in row probabilities if n_rows = 2 |
|
18 |
Kruskal-Wallis test for no row effect |
|
19 |
Kruskal-Wallis test for no column effect |
|
20 |
kappa (square tables only) |
|
21 |
McNemar test of symmetry (square tables only) |
|
22 |
McNemar one degree of freedom test of symmetry (square tables only) |
If a statistic cannot be computed, or if some value is not relevant for the computed statistic, the entry is NaN (Not a Number). The columns are as follows:
|
Column |
Value |
|
0 |
estimated statistic |
|
1 |
standard error for any parameter value |
|
2 |
standard error under the null hypothesis |
|
3 |
t value for testing the null hypothesis |
|
4 |
p-value of the test in column 3 |
In the McNemar tests, column 0 contains the statistic, column 1 contains the chi-squared degrees of freedom, column 3 contains the exact p-value (1 degree of freedom only), and column 4 contains the chi-squared asymptotic p-value. The Kruskal-Wallis test is the same except no exact p-value is computed.
IMSLS_STATISTICS_USER, float
statistics[] (Output)
Storage for array statistics provided by
the user. See IMSLS_STATISTICS.
Description
Function imsls_f_contingency_table computes statistics associated with an r × c (n_rows × n_columns) contingency table. The function computes the chi-squared test of independence, expected values, contributions to chi-squared, row and column marginal totals, some measures of association, correlation, prediction, uncertainty, the McNemar test for symmetry, a test for linear trend, the odds and the log odds ratio, and the kappa statistic (if the appropriate optional arguments are selected).
Notation
Let xij denote the observed cell frequency in the ij cell of the table and n denote the total count in the table. Let pij = pi∙•pj∙• denote the predicted cell probabilities under the null hypothesis of independence, where pi∙ and pj∙ are the row and column marginal relative frequencies. Next, compute the expected cell counts as eij = npij.
Also required in the following are auv and buv for u, v = 1, …, n. Let (rs, cs) denote the row and column response of observation s. Then, auv = 1, 0, or −1, depending on whether ru < rv, ru = rv, or ru > rv, respectively. The buv are similarly defined in terms of the cs variables.
Chi-squared Statistic
For each cell in the table, the contribution to Χ2 is given as (xij − eij)2/eij. The Pearson chi-squared statistic (denoted Χ2) is computed as the sum of the cell contributions to chi-squared. It has (r − 1) (c − 1) degrees of freedom and tests the null hypothesis of independence, i.e., H0:pij = pi∙pj∙. The null hypothesis is rejected if the computed value of Χ2 is too large.
The maximum likelihood equivalent of Χ2, G2 is computed as follows:
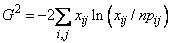
G2 is asymptotically equivalent to Χ2 and tests the same hypothesis with the same degrees of freedom.
Measures Related to Chi-squared (Phi, Contingency Coefficient, and Cramer’s V)
There are three measures related to chi-squared that do not depend on sample size:

Since these statistics do not depend on sample size and are large when the hypothesis of independence is rejected, they can be thought of as measures of association and can be compared across tables with different sized samples. While both P and V have a range between 0.0 and 1.0, the upper bound of P is actually somewhat less than 1.0 for any given table (see Kendall and Stuart 1979, p. 587). The significance of all three statistics is the same as that of the Χ2 statistic, chi_squared.
The distribution of the Χ2 statistic in finite samples approximates a chi-squared distribution. To compute the exact mean and standard deviation of the Χ2 statistic, Haldane (1939) uses the multinomial distribution with fixed table marginals. The exact mean and standard deviation generally differ little from the mean and standard deviation of the associated chi-squared distribution.
Standard Errors and p-values for Some Measures of Association
In Columns 1 through 4 of statistics, estimated standard
errors and asymptotic
p-values are reported. Estimates of the standard
errors are computed in two ways. The first estimate, in Column 1 of the
array statistics,
is asymptotically valid for any value of the statistic. The second estimate, in
Column 2 of the array, is only correct under the null hypothesis of no
association. The z-scores in Column 3 of statistics are computed using
this second estimate of the standard errors. The p-values in Column 4 are
computed from this z-score. See Brown and Benedetti (1977) for
a discussion and formulas for the standard errors in Column 2.
Measures of Association for Ranked Rows and Columns
The measures of association, ɸ, P, and V, do not require any ordering of the row and column categories. Function imsls_f_contingency_table also computes several measures of association for tables in which the rows and column categories correspond to ranked observations. Two of these tests, the product-moment correlation and the Spearman correlation, are correlation coefficients computed using assigned scores for the row and column categories. The cell indices are used for the product-moment correlation, while the average of the tied ranks of the row and column marginals is used for the Spearman rank correlation. Other scores are possible.
Gamma, Kendall’s τb, Stuart’s τc, and Somers’ D
are measures of association that are computed like a correlation coefficient in
the numerator. In all these measures, the numerator is computed as the
“covariance” between the
auv variables and
buv variables defined
above, i.e., as follows:
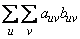
Recall that auv and buv can take values −1, 0, or 1. Since the product auvbuv = 1 only if auv and buv are both 1 or are both −1, it is easy to show that this ‘‘covariance’’ is twice the total number of agreements minus the number of disagreements, where a disagreement occurs when auvbuv = −1.
Kendall’s τb is computed as the
correlation between the auv variables and the
buv variables (see
Kendall and Stuart 1979, p. 593). In a rectangular table
(r c), Kendall’s τb cannot be 1.0 (if all
marginal totals are positive). For this reason, Stuart suggested a modification
to the denominator of τ in which the denominator
becomes the largest possible value of the “covariance.” This maximizing value is
approximately n2m/(m − 1), where
m = min (r, c). Stuart’s τc uses this approximate
value in its denominator. For large n, τc mτb/(m − 1).
Gamma can be motivated in a slightly different manner. Because the “covariance” of the auv variables and the buv variables can be thought of as twice the number of agreements minus the disagreements, 2(A − D), where A is the number of agreements and D is the number of disagreements, Gamma is motivated as the probability of agreement minus the probability of disagreement, given that either agreement or disagreement occurred. This is shown as γ = (A − D)/(A + D).
Two definitions of Somers’ D are possible, one for rows and a second for columns. Somers’ D for rows can be thought of as the regression coefficient for predicting auv from buv. Moreover, Somer’s D for rows is the probability of agreement minus the probability of disagreement, given that the column variable, buv, is not 0. Somers’ D for columns is defined in a similar manner.
A discussion of all of the measures of association in this section can be found in Kendall and Stuart (1979, p. 592).
Measures of Prediction and Uncertainty
Optimal Prediction Coefficients: The measures in this section do not require any ordering of the row or column variables. They are based entirely upon probabilities. Most are discussed in Bishop et al. (1975, p. 385).
Consider predicting (or classifying) the column for a given row in the table. Under the null hypothesis of independence, choose the column with the highest column marginal probability for all rows. In this case, the probability of misclassification for any row is 1 minus this marginal probability. If independence is not assumed within each row, choose the column with the highest row conditional probability. The probability of misclassification for the row becomes 1 minus this conditional probability.
Define the optimal prediction coefficient λc|r for predicting columns from rows as the proportion of the probability of misclassification that is eliminated because the random variables are not independent. It is estimated by
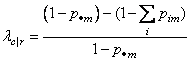
where m is the index of the maximum estimated probability in the row (pim) or row margin (pm). A similar coefficient is defined for predicting the rows from the columns. The symmetric version of the optimal prediction λ is obtained by summing the numerators and denominators of λr|c and λc|r, then dividing. Standard errors for these coefficients are given in Bishop et al. (1975, p. 388).
A problem with the optimal prediction coefficients λ is that they vary with the marginal probabilities. One way to correct this is to use row conditional probabilities. The optimal prediction λ* coefficients are defined as the corresponding λ coefficients in which first the row (or column) marginals are adjusted to the same number of observations. This yields

where i indexes the rows, j indexes the columns, and pj|i is the (estimated) probability of column j given row i.
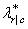
is similarly defined.
Goodman and Kruskal τ: A second kind of prediction measure attempts to explain the proportion of the explained variation of the row (column) measure given the column (row) measure. Define the total variation in the rows as follows:
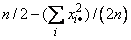
Note that this is 1/(2n) times the sums of squares of the auv variables.
With this definition of variation, the Goodman and Kruskal τ coefficient for rows is computed as the reduction of the total variation for rows accounted for by the columns, divided by the total variation for the rows. To compute the reduction in the total variation of the rows accounted for by the columns, note that the total variation for the rows within column j is defined as follows:
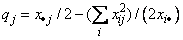
The total variation for rows within columns is the sum of the qj variables. Consistent with the usual methods in the analysis of variance, the reduction in the total variation is given as the difference between the total variation for rows and the total variation for rows within the columns.
Goodman and Kruskal’s τ for columns is similarly defined. See Bishop et al. (1975, p. 391) for the standard errors.
Uncertainty Coefficients: The uncertainty coefficient for rows is the increase in the log-likelihood that is achieved by the most general model over the independence model, divided by the marginal log-likelihood for the rows. This is given by the following equation:
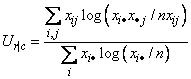
The uncertainty coefficient for columns is similarly defined. The symmetric uncertainty coefficient contains the same numerator as Ur|c and Uc|r but averages the denominators of these two statistics. Standard errors for U are given in Brown (1983).
Kruskal-Wallis: The Kruskal-Wallis statistic for rows is a one-way analysis-of-variance-type test that assumes the column variable is monotonically ordered. It tests the null hypothesis that no row populations are identical, using average ranks for the column variable. The Kruskal-Wallis statistic for columns is similarly defined. Conover (1980) discusses the Kruskal-Wallis test.
Test for Linear Trend: When there are two rows, it is possible to test for a linear trend in the row probabilities if it is assumed that the column variable is monotonically ordered. In this test, the probabilities for row 1 are predicted by the column index using weighted simple linear regression. This slope is given by
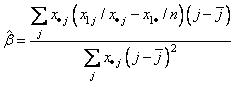
where
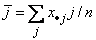
is the average column index. An asymptotic test that the slope is 0 may then be obtained (in large samples) as the usual regression test of zero slope.
In two-column data, a similar test for a linear trend in the column probabilities is computed. This test assumes that the rows are monotonically ordered.
Kappa: Kappa is a measure of agreement computed on square tables only. In the kappa statistic, the rows and columns correspond to the responses of two judges. The judges agree along the diagonal and disagree off the diagonal. Let
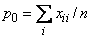
denote the probability that the two judges agree, and let
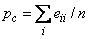
denote the expected probability of agreement under the independence model. Kappa is then given by (p0 − pc)/(1 − pc).
McNemar Tests: The McNemar test is a test of symmetry in a square contingency table. In other words, it is a test of the null hypothesis H0:θij = θji. The multiple degrees-of-freedom version of the McNemar test with r (r − 1)/2 degrees of freedom is computed as follows:
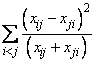
The single degree-of-freedom test assumes that the differences, xij − xji, are all in one direction. The single degree-of-freedom test will be more powerful than the multiple degrees-of-freedom test when this is the case. The test statistic is given as follows:
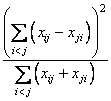
The exact probability can be computed by the binomial distribution.
Examples
Example 1
The following example is taken from Kendall and Stuart (1979) and involves the distance vision in the right and left eyes. Output contains only the p-value.
#include <imsls.h>
void
main()
{
int n_rows =
4;
int n_columns = 4;
float
table[4][4] = {821, 112, 85,
35,
116, 494, 145,
27,
72, 151, 583,
87,
43, 34, 106, 331};
float
p_value;
p_value = imsls_f_contingency_table(n_rows,
n_columns,
&table[0][0], 0);
printf ("P-value = %10.6f.\n",
p_value);
}
Output
P-value = 0.000000.
Example 2
The following example, which illustrates the use of Kappa and McNemar tests, uses the same distance vision data as the previous example. The available statistics are output using optional arguments.
#include <imsls.h>
void
main()
{
int n_rows =
4;
int n_columns =
4;
int df1,
df2;
float table[16] =
{821.0, 112.0, 85.0, 35.0,
116.0, 494.0, 145.0, 27.0,
72.0, 151.0, 583.0, 87.0,
43.0, 34.0, 106.0, 331.0};
float
p_value1, p_value2, chi_squared, g_squared;
float *expected,
*chi_squared_contributions;
float
*chi_squared_stats, *statistics;
char *labels[] =
{
"Exact
mean",
"Exact standard
deviation",
"Phi",
"P",
"Cramer’s V"};
char
*stat_row_labels[] = {"Gamma", "Tau B", "Tau C",
"D-Row", "D-Column", "Correlation",
"Spearman",
"GK tau rows", "GK tau cols.", "U - sym.", "U -
rows",
"U - cols.", "Lambda-sym.", "Lambda-row",
"Lambda-col.",
"l-star-rows", "l-star-col.", "Lin. trend",
"Kruskal row", "Kruskal col.", "Kappa",
"McNemar",
"McNemar df=1"};
char
*stat_col_labels[] = {"","statistic", "standard
error",
"std. error under Ho", "t-value testing Ho",
"p-value"};
imsls_f_contingency_table (n_rows,
n_columns,
table,
IMSLS_CHI_SQUARED, &df1, &chi_squared,
&p_value1,
IMSLS_LRT, &df2, &g_squared,
&p_value2,
IMSLS_EXPECTED, &expected,
IMSLS_CONTRIBUTIONS,
&chi_squared_contributions,
IMSLS_CHI_SQUARED_STATS,
&chi_squared_stats,
IMSLS_STATISTICS,
&statistics,
0);
printf("Pearson chi-squared
statistic %11.4f\n", chi_squared);
printf("p-value for Pearson chi-squared %11.4f\n",
p_value1);
printf("degrees of
freedom
%11d\n", df1);
printf("G-squared
statistic
%11.4f\n", g_squared);
printf("p-value for
G-squared
%11.4f\n", p_value2);
printf("degrees of
freedom
%11d\n", df2);
imsls_f_write_matrix("* * * Table
Values * * *\n", 4,
4,
table,
IMSLS_WRITE_FORMAT,
"%11.1f",
0);
imsls_f_write_matrix("* * * Expected Values * *
*\n", 5,
5,
expected,
IMSLS_WRITE_FORMAT,
"%11.2f",
0);
imsls_f_write_matrix("* * * Contributions to
Chi-squared* *
*\n",
5,
5,
chi_squared_contributions,
IMSLS_WRITE_FORMAT,
"%11.2f",
0);
imsls_f_write_matrix("* * * Chi-square Statistics * *
*\n",
5,
1,
chi_squared_stats,
IMSLS_ROW_LABELS,
labels,
IMSLS_WRITE_FORMAT,
"%11.4f",
0);
imsls_f_write_matrix("* * * Table Statistics * *
*\n",
23, 5,
statistics,
IMSLS_ROW_LABELS,
stat_row_labels,
IMSLS_COL_LABELS,
stat_col_labels,
IMSLS_WRITE_FORMAT,
"%9.4f",
0);
}
Output
Pearson chi-squared
statistic 3304.3682
p-value for Pearson
chi-squared 0.0000
degrees of
freedom
9
G-squared
statistic
2781.0188
p-value for
G-squared
0.0000
degrees of
freedom
9
* * * Table Values * * *
1
2
3
4
1
821.0
112.0
85.0
35.0
2
116.0
494.0
145.0
27.0
3
72.0
151.0
583.0
87.0
4
43.0
34.0
106.0
331.0
* * * Expected Values * *
*
1
2
3
4
5
1
341.69
256.92
298.49 155.90
1053.00
2
253.75
190.80
221.67
115.78
782.00
3
289.77
217.88
253.14
132.21
893.00
4
166.79
125.41
145.70
76.10
514.00
5
1052.00
791.00
919.00 480.00
3242.00
* * * Contributions to Chi-squared* *
*
1
2
3
4
5
1
672.36
81.74
152.70
93.76
1000.56
2
74.78
481.84
26.52
68.08
651.21
3
163.66
20.53
429.85
15.46
629.50
4
91.87
66.63
10.82 853.78
1023.10
5
1002.68
650.73 619.88
1031.08 3304.37
* * *
Chi-square Statistics * * *
Exact
mean
9.0028
Exact standard deviation
4.2402
Phi
1.0096
P
0.7105
Cramer’s
V
0.5829
* * * Table Statistics * *
*
statistic standard error std. error t-value
testing
under
Ho
Ho
Gamma
0.7757
0.0123
0.0149 52.1897
Tau
B
0.6429
0.0122
0.0123 52.1897
Tau
C
0.6293 0.0121
.........
52.1897
D-Row
0.6418
0.0122
0.0123
52.1897
D-Column
0.6439
0.0122
0.0123
52.1897
Correlation
0.6926
0.0128
0.0172
40.2669
Spearman
0.6939
0.0127
0.0127
54.6614
GK tau rows
0.3420 0.0123
......... .........
GK tau
cols.
0.3430 0.0122
......... .........
U -
sym.
0.3171 0.0110
......... .........
U -
rows
0.3178 0.0110
......... .........
U -
cols.
0.3164 0.0110
.........
.........
Lambda-sym.
0.5373 0.0124
.........
.........
Lambda-row
0.5374 0.0126
.........
.........
Lambda-col.
0.5372 0.0126
.........
.........
l-star-rows
0.5506 0.0136
.........
.........
l-star-col.
0.5636 0.0127
......... .........
Lin.
trend .........
......... .........
.........
Kruskal row
1561.4861
3.0000 .........
.........
Kruskal col.
1563.0300
3.0000 .........
.........
Kappa
0.5744
0.0111
0.0106
54.3583
McNemar
4.7625 6.0000
......... .........
McNemar
df=1
0.9487 1.0000
.........
0.3459
p-value
Gamma
0.0000
Tau
B
0.0000
Tau
C
0.0000
D-Row
0.0000
D-Column
0.0000
Correlation
0.0000
Spearman 0.0000
GK
tau rows .........
GK tau cols. .........
U -
sym. .........
U -
rows .........
U -
cols. .........
Lambda-sym.
.........
Lambda-row .........
Lambda-col.
.........
l-star-rows .........
l-star-col.
.........
Lin. trend .........
Kruskal
row 0.0000
Kruskal col.
0.0000
Kappa
0.0000
McNemar
0.5746
McNemar df=1 0.3301
Warning Errors
IMSLS_DF_GT_30 The degrees of freedom for “IMSLS_CHI_SQUARED” are greater than 30. The exact mean, standard deviation, and the normal distribution function should be used.
IMSLS_EXP_VALUES_TOO_SMALL Some expected values are less than #. Some asymptotic p-values may not be good.
IMSLS_PERCENT_EXP_VALUES_LT_5 Twenty percent of the expected values are calculated less than 5.
|
Visual Numerics, Inc. PHONE: 713.784.3131 FAX:713.781.9260 |