Computes Kaplan-Meier estimates of survival probabilities in stratified samples.
Synopsis
#include <imsls.h>
float *imsls_f_kaplan_meier_estimates (int n_observations, int ncol, float x[], ..., 0)
The type double function is imsls_d_kaplan_meier_estimates.
Required Arguments
int n_observations
(Input)
Number of observations.
int ncol
(Input)
Number of columns in x.
float x[]
(Input)
Two-dimensional data array of size n_observations*ncol.
Return Value
Pointer to an array of length n_observations*2. The first column contains the estimated survival probabilities, and the second column contains Greenwood’s estimate of the standard deviation of these probabilities. If the i-th observation contains censor codes out of range or if a variable is missing, then the corresponding elements of the return value are set to missing (NaN, not a number). Similarly, if an element in the return value is not defined, then it is set to missing.
Synopsis with Optional Arguments
#include <imsls.h>
float *
imsls_f_kaplan_meier_estimates (int
n_observations, int ncol, float
x[],
IMSLS_RETURN_USER,
float table[],
IMSLS_PRINT,
IMSLS_X_RESPONSE_COL, int
irt,
IMSLS_CENSOR_CODES_COL, int
icen,
IMSLS_FREQ_RESPONSE_COL_COL, int
ifrq,
IMSLS_STRATUM_NUMBER_COL, int
igrp,
IMSLS_SORTED,
IMSLS_N_MISSING, int
*nrmiss,
0)
Optional Arguments
IMSLS_RETURN_USER,
float table[]
(Output)
User supplied storage of an array of length n_observations*2
containing the estimated survival probabilities and their associated standard
deviations. See Return Value section.
IMSLS_PRINT, (Input)
Print Kaplan-Meier estimates of
survival probabilities in stratified samples.
IMSLS_X_RESPONSE_COL,
int irt
(Input)
Column index for the response times in the data array, x. The interpretation
of these times as either right-censored or exact failure times depends on IMSLS_CENSOR_CODES_COL.
Default:
irt = 0.
IMSLS_CENSOR_CODES_COL,
int icen (Input)
Column index for the optional
censoring codes in the data array, x. If x[i, icen]= 0, the failure
time x[i, irt] is treated as an
exact time of failure. Otherwise it is treated as a right-censored time.
Default: It is assumed that there is no censor code column in x. All observations
are assumed to be exact failure times.
IMSLS_FREQ_RESPONSE_COL_COL,
int ifrq
(Input)
Column index for the number of responses associated with each row in
the data array, x.
Default:
It is assumed that there is no frequency response column in x. Each
observation in the data array is assumed to be for a single failure.
IMSLS_STRATUM_NUMBER_COL,
int igrp
(Input)
Column index for the stratum number for each observation in the data
array, x.
Column igrp of
x contains a
unique value for each stratum in the data. Kaplan-Meier estimates are computed
within each stratum.
Default: It is assumed that there is no stratum number
column in x. The
data is assumed to come from one stratum.
IMSLS_SORTED,
(Input)
If this option is used, column irt of x is assumed to be
sorted in ascending order within each stratum. Otherwise, a detached sort is
conducted prior to analysis. If sorting is performed, all censored individuals
are assumed to follow tied failures.
Default: Column irt of x is not sorted.
IMSLS_N_MISSING, int *nrmiss
(Output)
Number of rows of data in x containing missing
values.
Description
Function imsls_f_kaplan_meier_estimates
computes Kaplan-Meier (or product-limit) estimates of survival probabilities for
a sample of failure times that can be right censored or exact times. A survival
probability S(t) is defined as
1 - F(t), where
F(t) is the cumulative distribution function of the failure times
(t). Greenwood’s estimate of the standard errors of the survival
probability estimates are also computed. (See Kalbfleisch and Prentice, 1980,
pages 13 and 14.)
Let (ti, di), for i = 1,…, n denote the failure censoring times and the censoring codes for the n observations in a single sample. Here, ti = xi-1, irt is a failure time if di is 0, where di = xi-1, icen. Also, ti is a right censoring time if di is 1. Rows in x containing values other than 0 or 1 for di are ignored. Let the number of observations in the sample that have not failed by time s(t) be denoted by n(t), where s(t) is an ordered (from smallest to largest) listing of the distinct failure times (censoring times are omitted). Then the Kaplan-Meier estimate of the survival probabilities is a step function, which in the interval from s(t) to s(i+1) (including the lower endpoint) is given by

where d(j) denotes the number of failures occurring at time s(j), and n(φ) is the number of observation that have not failed prior to s(j).
Note that one row of X may correspond to more than one failed (or censored) observation when the frequency option is in effect (ifrq is specified). The Kaplan-Meier estimate of the survival probability prior to time s(1) is 1.0, while the Kaplan-Meier estimate of the survival probability after the last failure time is not defined.
Greenwood’s estimate of the variance of
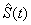
in the interval from s(i) to s(i+1) is given as
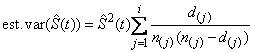
Function imsls_f_kaplan_meier_estimates computes the single sample estimates of the survival probabilities for all samples of data included in x during a single call. This is accomplished through the igrp column of x, which if present, must contain a distinct code for each sample of observations. If igrp is not specified, there is no grouping column, and all observations are assumed to come from the same sample.
When failures and right-censored observations are tied and the data are to be sorted by imsls_f_kaplan_meier_estimates (IMSLS_SORTED optional argument is not used), imsls_f_kaplan_meier_estimates assumes that the time of censoring for the tied-censored observations is immediately after the tied failure (within the same sample). When the IMSLS_SORTED optional argument is used, the data are assumed to be sorted from smallest to largest according to column irt of x within each stratum. Furthermore, a small increment of time is assumed (theoretically) to elapse between the failed and censored observations that are tied (in the same sample). Thus, when the IMSLS_SORTED optional argument is used, the user must sort all of the data in x from smallest to largest according to column irt (and column igrp, if present). By appropriate sorting of the observations, the user can handle censored and failed observations that are tied in any manner desired.
The IMSLS_PRINT option prints life tables. One table for each stratum is printed. In addition to the survival probabilities at each failure point, the following is also printed: the number of individuals remaining at risk, Greenwood’s estimate of the standard errors for the survival probabilities, and the Kaplan-Meier log-likelihood. The Kaplan-Meier log-likelihood is computed as:
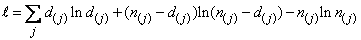
where the sum is with respect to the distinct failure times s(j), d(j).
Example
The following example is taken from Kalbfleisch and Prentice (1980, page 1). The first column in x contains the death/censoring times for rats suffering from vaginal cancer. The second column contains information as to which of two forms of treatment were provided, while the third column contains the censoring code. Finally, the fourth column contains the frequency of each observation. The product-limit estimates of the survival probabilities are computed for both groups with one call to imsls_f_kaplan_meier_estimates.
Function imsls_f_kaplan_meier_estimates could have been called with the IMSLS_SORTED optional argument if the censored observations had been sorted with respect to the failure time variable. IMSLS_PRINT option is used to print the life tables.
#include "imsls.h"
void main ()
{
int icen = 2, ifrq = 3, igrp = 1, ncol = 4, n_observations = 33;
float x[] = {
143, 5, 0, 1,
164, 5, 0, 1,
188, 5, 0, 2,
190, 5, 0, 1,
192, 5, 0, 1,
206, 5, 0, 1,
209, 5, 0, 1,
213, 5, 0, 1,
216, 5, 0, 1,
220, 5, 0, 1,
227, 5, 0, 1,
230, 5, 0, 1,
234, 5, 0, 1,
246, 5, 0, 1,
265, 5, 0, 1,
304, 5, 0, 1,
216, 5, 1, 1,
244, 5, 1, 1,
142, 7, 0, 1,
156, 7, 0, 1,
163, 7, 0, 1,
198, 7, 0, 1,
205, 7, 0, 1,
232, 7, 0, 2,
233, 7, 0, 4,
239, 7, 0, 1,
240, 7, 0, 1,
261, 7, 0, 1,
280, 7, 0, 2,
296, 7, 0, 2,
323, 7, 0, 1,
204, 7, 1, 1,
344, 7, 1, 1
};
imsls_f_kaplan_meier_estimates (n_observations, ncol, x,
IMSLS_PRINT,
IMSLS_FREQ_RESPONSE_COL_COL, ifrq,
IMSLS_CENSOR_CODES_COL, icen,
IMSLS_STRATUM_NUMBER_COL, igrp,
0);
}
Output
Kaplan Meier Survival Probabilities
For Group Value = 5
Number Number Survival Estimated
at risk Failing Time Probability Std. Error
19 1 143 0.94737 0.051228
18 1 164 0.89474 0.070406
17 2 188 0.78947 0.093529
15 1 190 0.73684 0.10102
14 1 192 0.68421 0.10664
13 1 206 0.63158 0.11066
12 1 209 0.57895 0.11327
11 1 213 0.52632 0.11455
10 1 216 0.47368 0.11455
8 1 220 0.41447 0.11452
7 1 227 0.35526 0.11243
6 1 230 0.29605 0.10816
5 1 234 0.23684 0.10145
3 1 246 0.15789 0.093431
2 1 265 0.078947 0.072792
1 1 304 0 ............
Total number in group = 19
Total number failing = 17
Product Limit Likelihood = -49.1692
Kaplan Meier Survival Probabilities
For Group Value = 7
Number Number Survival Estimated
at risk Failing Time Probability Std. Error
21 1 142 0.95238 0.046471
20 1 156 0.90476 0.064056
19 1 163 0.85714 0.07636
18 1 198 0.80952 0.085689
16 1 205 0.75893 0.094092
15 2 232 0.65774 0.10529
13 4 233 0.45536 0.11137
9 1 239 0.40476 0.10989
8 1 240 0.35417 0.10717
7 1 261 0.30357 0.10311
6 2 280 0.20238 0.090214
4 2 296 0.10119 0.067783
2 1 323 0.050595 0.049281
Total number in group = 21
Total number failing = 19
Product Limit Likelihood = -50.4277
|
Visual Numerics, Inc. PHONE: 713.784.3131 FAX:713.781.9260 |