This application illustrates one common approach to time series prediction using a neural network. In this case, the output target for this network is a single time series. In general, the inputs to this network consist of lagged values of the time series together with other concomitant variables, both continuous and categorical. In this application, however, only the first three lags of the time series are used as network inputs.
The objective is to train a neural network for forecasting the series ![]() , from the first three lags of
, from the first three lags of ![]() , i.e.
, i.e.
The structure of the network consists of three input nodes and two layers, with three perceptrons in the hidden layer and one in the output layer. The following figure depicts this structure:
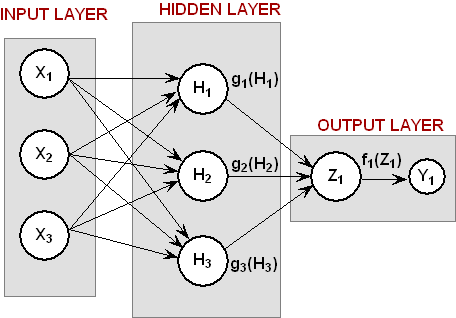
There are a total of 16 weights in this network, including the 4 bias weights. All perceptrons in the hidden layer use logistic activation, and the output perceptron uses linear activation. Because of the large number of training patterns, the Activation.LOGISTIC_TABLE
activation funtion is used instead of Activation.LOGISTIC
. Activation.LOGISTIC_TABLE
uses a table lookup for calculating the logistic activation function, which significantly reduces training time. However, these are not completely interchangable. If a network is trained using Activation.LOGISTIC_TABLE
, then it is important to use the same activation function for forecasting.
All input nodes are linked to every perceptron in the hidden layer, which are in turn linked to the output perceptron. Then all inputs and the output target are scaled using the ScaleFilter
class to ensure that all input values and outputs are in the range [0, 1]. This requires forecasts to be unscaled using the decode()
method of the ScaleFilter
class.
Training is conducted using the epoch trainer. This trainer allows users to customize training into two stages. Typically this is necessary when training using a large number of training patterns. Stage I training uses randomly selected subsets of training patterns to search for network solutions. Stage II training is optional, and uses the entire set of training patterns. For larger sets of training patterns, training could take many hours, or even days. In that case, Stage II training might be bypassed.
In this example, Stage I training is conducted using the Quasi-Newton trainer applied to 20 epochs, each consisting of 5,000 randomly selected observations. Stage II training also uses the Quasi-Newton trainer. The training results for each Stage I epoch and for the final Stage II solution are stored in a training log file NeuralNetworkEx1.log.
The training patterns are contained in two data files: continuous.txt
and output.txt
. The formats of these files are identical. The first line of the file contains the number of columns or variables in that file. The second contains a line of tab-delimited integer values. These are the column indices associated with the incoming data. The remaining lines contain tab-delimited, floating point values, one for each of the incoming variables.
For example, the first four lines of the continuous.txt
file consists of the following lines:
3
1 2 3
0 0 0
0 0 0
There are 3 continuous input variables which are numbered, or labeled, as 1, 2, and 3.
import com.imsl.datamining.neural.*;
import com.imsl.math.*;
import java.io.*;
import java.util.*;
import java.util.logging.*;
//*****************************************************************************
// NeuralNetworkEx1.java *
// Two Layer Feed-Forward Network Complete Example for Simple Time Series *
//*****************************************************************************
// Synopsis: This example illustrates how to use a Feed-Forward Neural *
// Network to forecast time series data. The network target is a *
// time series and the three inputs are the 1st, 2nd, and 3rd lag *
// for the target series. *
// Activation: Logistic_Table in Hidden Layer, Linear in Output Layer *
// Trainer: Epoch Trainer: Stage I - Quasi-Newton, Stage II - Quasi-Newton *
// Inputs: Lags 1-3 of the time series *
// Output: A Time Series sorted chronologically in descending order, *
// i.e., the most recent observations occur before the earliest, *
// within each department *
//*****************************************************************************
public class NeuralNetworkEx1 implements Serializable {
private FeedForwardNetwork network;
private static String QuasiNewton = "quasi-newton";
private static String LeastSquares= "least-squares";
// *****************************************************************************
// Network Architecture *
// *****************************************************************************
private static int nObs =118519; // number of training patterns
private static int nInputs = 3; // four inputs
private static int nCategorical = 0; // three categorical attributes
private static int nContinuous = 3; // one continuous input attribute
private static int nOutputs = 1; // one continuous output
private static int nLayers = 2; // number of perceptron layers
private static int nPerceptrons = 3; // perceptrons in hidden layer
private static int perceptrons[]={3}; // number of perceptrons in each
// hidden layer
// PERCEPTRON ACTIVATION
private static Activation hiddenLayerActivation = Activation.LOGISTIC_TABLE;
private static Activation outputLayerActivation = Activation.LINEAR;
// *****************************************************************************
// Epoch Training Optimization Settings *
// *****************************************************************************
private static boolean trace = true; //trainer logging *
private static int nEpochs = 20; //number of epochs *
private static int epochSize = 5000; //samples per epoch *
// Stage I Trainer - Quasi-Newton Trainer **********************************
private static int stage1Iterations = 5000; //max. iterations *
private static double stage1MaxStepsize = 50.0; //max. stepsize *
private static double stage1StepTolerance = 1e-09;//step tolerance *
private static double stage1RelativeTolerance = 1e-11;//rel. tolerance *
// Stage II Trainer - Quasi-Newton Trainer *********************************
private static int stage2Iterations = 5000; //max. iterations *
private static double stage2MaxStepsize = 50.0; //max. stepsize *
private static double stage2StepTolerance = 1e-09;//step tolerance *
private static double stage2RelativeTolerance = 1e-11;//rel. tolerance *
// *****************************************************************************
// FILE NAMES AND FILE READER DEFINITIONS *
// *****************************************************************************
// READERS
private static BufferedReader attFileInputStream;
private static BufferedReader contFileInputStream;
private static BufferedReader outputFileInputStream;
// OUTPUT FILES
// File Name for training log produced when trace = true
private static String trainingLogFile = "NeuralNetworkEx1.log";
// File Name for Serialized Network
private static String networkFileName = "NeuralNetworkEx1.ser";
// File Name for Serialized Trainer
private static String trainerFileName = "NeuralNetworkTrainerEx1.ser";
// File Name for Serialized xData File (training input attributes)
private static String xDataFileName = "NeuralNetworkxDataEx1.ser";
// File Name for Serialized yData File (training output targets)
private static String yDataFileName = "NeuralNetworkyDataEx1.ser";
// INPUT FILES
// Continuous input attributes file. File contains Lags 1-3 of series
private static String contFileName = "continuous.txt";
// Continuous network targets file. File contains the original series
private static String outputFileName = "output.txt";
// *****************************************************************************
// Data Preprocessing Settings *
// *****************************************************************************
private static double lowerDataLimit=-105000; // lower scale limit
private static double upperDataLimit=25000000; // upper scale limit
private static double missingValue = -9999999999.0; // missing values
// indicator
// *****************************************************************************
// Time Parameters for Tracking Training Time *
// *****************************************************************************
private static Calendar startTime;
private static Calendar endTime;
// *****************************************************************************
// Error Message Encoding for Stage II Trainer - Quasi-Newton Trainer *
// *****************************************************************************
// Note: For the Epoch Trainer, the error status returned is the status for *
// the Stage II trainer, unless Stage II training is not used. *
// *****************************************************************************
private static String errorMsg = "";
// Error Status Messages for the Quasi-Newton Trainer
private static String errorMsg0 =
"--> Network Training";
private static String errorMsg1 =
"--> The last global step failed to locate a lower point than the\n"+
"current error value. The current solution may be an approximate\n"+
"solution and no more accuracy is possible, or the step tolerance\n"+
"may be too large.";
private static String errorMsg2 =
"--> Relative function convergence; both both the actual and \n"+
"predicted relative reductions in the error function are less than\n"+
"or equal to the relative fu nction convergence tolerance.";
private static String errorMsg3 =
"--> Scaled step tolerance satisfied; the current solution may be\n"+
"an approximate local solution, or the algorithm is making very slow\n"+
"progress and is not near a solution, or the step tolerance is too big.";
private static String errorMsg4 =
"--> Quasi-Newton Trainer threw a \n"+
"MinUnconMultiVar.FalseConvergenceException.";
private static String errorMsg5 =
"--> Quasi-Newton Trainer threw a \n"+
"MinUnconMultiVar.MaxIterationsException.";
private static String errorMsg6 =
"--> Quasi-Newton Trainer threw a \n"+
"MinUnconMultiVar.UnboundedBelowException.";
// *****************************************************************************
// MAIN *
// *****************************************************************************
public static void main(String[] args) throws Exception {
double weight[]; // Network weights
double gradient[]; // Network gradient after training
double x[]; // Temporary x space for generating forecasts
double y[]; // Temporary y space for generating forecasts
double xData[][]; // Training Patterns Input Attributes
double yData[][]; // Training Targets Output Attributes
double contAtt[][];// A 2D matrix for the continuous training attributes
double outs[][]; // A matrix containing the training output tragets
int i, j, k, m=0; // Array indicies
int nWeights = 0; // Number of network weights
int nCol = 0; // Number of data columns in input file
int ignore[]; // Array of 0's and 1's (0=missing value)
int cont_col[], outs_col[], isMissing[]={0};
String inputLine="", temp;
String dataElement[];
// *************************************************************************
// Initialize timers *
// *************************************************************************
startTime = Calendar.getInstance();
System.out.println("--> Starting Data Preprocessing at: "+
startTime.getTime());
// *************************************************************************
// Read continuous attribute data *
// *************************************************************************
// Initialize ignore[] for identifying missing observations
ignore = new int[nObs];
isMissing = new int[1];
openInputFiles();
nCol = readFirstLine(contFileInputStream);
nContinuous = nCol;
System.out.println("--> Number of continuous variables: "+nContinuous);
// If the number of continuous variables is greater than zero then read
// the remainder of this file (contFile)
if(nContinuous > 0){
// contFile contains continuous attribute data
contAtt = new double[nObs][nContinuous];
cont_col = readColumnLabels(contFileInputStream, nContinuous);
for (i=0; i < nObs; i++){
isMissing[0] = -1;
contAtt[i] = readDataLine(contFileInputStream,
nContinuous, isMissing);
ignore[i] = isMissing[0];
if (isMissing[0] >= 0) m++;
}
}else{
nContinuous = 0;
contAtt = new double[1][1];
contAtt[0][0]= 0;
}
closeFile(contFileInputStream);
// *************************************************************************
// Read continuous output targets *
// *************************************************************************
nCol = readFirstLine(outputFileInputStream);
nOutputs = nCol;
System.out.println("--> Number of output variables: "+nOutputs);
outs = new double[nObs][nOutputs];
// Read numeric labels for continuous input attributes
outs_col = readColumnLabels(outputFileInputStream, nOutputs);
m = 0;
for (i=0; i < nObs; i++){
isMissing[0] = ignore[i];
outs[i] = readDataLine(outputFileInputStream, nOutputs, isMissing);
ignore[i] = isMissing[0];
if (isMissing[0] >= 0) m++;
}
System.out.println("--> Number of Missing Observations: " + m);
closeFile(outputFileInputStream);
// Remove missing observations using the ignore[] array
m = removeMissingData(nObs, nContinuous, ignore, contAtt);
m = removeMissingData(nObs, nOutputs, ignore, outs);
System.out.println("--> Total Number of Training Patterns: "+ nObs);
nObs = nObs - m;
System.out.println("--> Number of Usable Training Patterns: "+ nObs);
// *************************************************************************
// Setup Method and Bounds for Scale Filter *
// *************************************************************************
ScaleFilter scaleFilter = new ScaleFilter(ScaleFilter.BOUNDED_SCALING);
scaleFilter.setBounds(lowerDataLimit,upperDataLimit,0,1);
// *************************************************************************
// PREPROCESS TRAINING PATTERNS *
// *************************************************************************
System.out.println("--> Starting Preprocessing of Training Patterns");
xData = new double[nObs][nContinuous];
yData = new double[nObs][nOutputs];
for(i=0; i < nObs; i++) {
for(j=0; j < nContinuous; j++){
xData[i][j] = contAtt[i][j];
}
yData[i][0] = outs[i][0];
}
scaleFilter.encode(0, xData);
scaleFilter.encode(1, xData);
scaleFilter.encode(2, xData);
scaleFilter.encode(0, yData) ;
// *************************************************************************
// CREATE FEEDFORWARD NETWORK *
// *************************************************************************
System.out.println("--> Creating Feed Forward Network Object");
FeedForwardNetwork network = new FeedForwardNetwork();
// setup input layer with number of inputs = nInputs = 3
network.getInputLayer().createInputs(nInputs);
// create a hidden layer with nPerceptrons=3 perceptrons
network.createHiddenLayer().createPerceptrons(nPerceptrons);
// create output layer with nOutputs=1 output perceptron
network.getOutputLayer().createPerceptrons(nOutputs);
// link all inputs and perceptrons to all perceptrons in the next layer
network.linkAll();
// Get Network Perceptrons for Setting Their Activation Functions
Perceptron perceptrons[] = network.getPerceptrons();
// Set all hidden layer perceptrons to logistic_table activation
for (i=0; i < perceptrons.length-1; i++) {
perceptrons[i].setActivation(hiddenLayerActivation);
}
perceptrons[perceptrons.length-1].setActivation(outputLayerActivation);
System.out.println("--> Feed Forward Network Created with 2 Layers");
// ****************************************************************************
// TRAIN NETWORK USING EPOCH TRAINER *
// ****************************************************************************
System.out.println("--> Training Network using Epoch Trainer");
Trainer trainer = createTrainer(QuasiNewton,QuasiNewton);
Calendar startTime = Calendar.getInstance();
// Train Network
trainer.train(network, xData, yData);
// Check Training Error Status
switch(trainer.getErrorStatus()){
case 0: errorMsg = errorMsg0;
break;
case 1: errorMsg = errorMsg1;
break;
case 2: errorMsg = errorMsg2;
break;
case 3: errorMsg = errorMsg3;
break;
case 4: errorMsg = errorMsg4;
break;
case 5: errorMsg = errorMsg5;
break;
case 6: errorMsg = errorMsg6;
break;
default:errorMsg = "--> Unknown Error Status Returned from Trainer";
}
System.out.println(errorMsg);
Calendar currentTimeNow = Calendar.getInstance();
System.out.println("--> Network Training Completed at: "+currentTimeNow.getTime());
double duration = (double)(currentTimeNow.getTimeInMillis() -
startTime.getTimeInMillis())/1000.0;
System.out.println("--> Training Time: "+duration+" seconds");
// *************************************************************************
// DISPLAY TRAINING STATISTICS *
// *************************************************************************
double stats[] = network.computeStatistics(xData, yData);
// Display Network Errors
System.out.println("***********************************************");
System.out.println("--> SSE: "+(float)stats[0]);
System.out.println("--> RMS: "+(float)stats[1]);
System.out.println("--> Laplacian Error: "+(float)stats[2]);
System.out.println("--> Scaled Laplacian Error: "+(float)stats[3]);
System.out.println("--> Largest Absolute Residual: "+(float)stats[4]);
System.out.println("***********************************************");
System.out.println("");
// *************************************************************************
// OBTAIN AND DISPLAY NETWORK WEIGHTS AND GRADIENTS *
// *************************************************************************
System.out.println("--> Getting Network Weights and Gradients");
// Get weights
weight = network.getWeights();
// Get number of weights = number of gradients
nWeights = network.getNumberOfWeights();
// Obtain Gradient Vector
gradient = trainer.getErrorGradient();
// Print Network Weights and Gradients
System.out.println(" ");
System.out.println("--> Network Weights and Gradients:");
System.out.println("***********************************************");
double[][] printMatrix = new double[nWeights][2];
for(i=0; i < nWeights; i++){
printMatrix[i][0] = weight[i];
printMatrix[i][1] = gradient[i];
}
// Print result without row/column labels.
String[] colLabels = {"Weight", "Gradient"};
PrintMatrix pm = new PrintMatrix();
PrintMatrixFormat mf;
mf = new PrintMatrixFormat();
mf.setNoRowLabels();
mf.setColumnLabels(colLabels);
pm.setTitle("Weights and Gradients");
pm.print(mf, printMatrix);
System.out.println("***********************************************");
// *************************************************************************
// SAVE THE TRAINED NETWORK BY SAVING THE SERIALIZED NETWORK OBJECT *
// *************************************************************************
System.out.println("\n--> Saving Trained Network into "+
networkFileName);
write(network, networkFileName);
System.out.println("--> Saving Network Trainer into "+
trainerFileName);
write(trainer, trainerFileName);
System.out.println("--> Saving xData into "+
xDataFileName);
write(xData, xDataFileName);
System.out.println("--> Saving yData into "+
yDataFileName);
write(yData, yDataFileName);
}
// *****************************************************************************
// OPEN DATA FILES *
// *****************************************************************************
static public void openInputFiles(){
try{
// Continuous Input Attributes
InputStream contInputStream = new FileInputStream(contFileName);
contFileInputStream =
new BufferedReader(new InputStreamReader(contInputStream));
// Continuous Output Targets
InputStream outputInputStream = new FileInputStream(outputFileName);
outputFileInputStream =
new BufferedReader(new InputStreamReader(outputInputStream));
}catch(Exception e){
System.out.println("-->ERROR: "+e);
System.exit(0);
}
}
// *****************************************************************************
// READ FIRST LINE OF DATA FILE AND RETURN NUMBER OF COLUMNS IN FILE *
// *****************************************************************************
static public int readFirstLine(BufferedReader inputFile){
String inputLine="", temp;
int nCol=0;
try{
temp = inputFile.readLine();
inputLine = temp.trim();
nCol = Integer.parseInt(inputLine);
}catch(Exception e){
System.out.println("--> ERROR READING 1st LINE OF File" + e);
System.exit(0);
}
return nCol;
}
// *****************************************************************************
// READ COLUMN LABELS (2ND LINE IN FILE) *
// *****************************************************************************
static public int[] readColumnLabels(BufferedReader inputFile, int nCol){
int contCol[] = new int[nCol];
String inputLine="", temp;
String dataElement[];
// Read numeric labels for continuous input attributes
try{
temp = inputFile.readLine();
inputLine = temp.trim();
}catch(Exception e){
System.out.println("--> ERROR READING 2nd LINE OF FILE: "+ e);
System.exit(0);
}
dataElement = inputLine.split(" ");
for (int i=0; i < nCol; i++){
contCol[i] = Integer.parseInt(dataElement[i]);
}
return contCol;
}
// *****************************************************************************
// READ DATA ROW *
// *****************************************************************************
static public double[] readDataLine(BufferedReader inputFile,
int nCol, int[] isMissing){
double missingValueIndicator = -9999999999.0;
double dataLine[] = new double[nCol];
double contCol[] = new double[nCol];
String inputLine="", temp;
String dataElement[];
try{
temp = inputFile.readLine();
inputLine = temp.trim();
}catch(Exception e){
System.out.println("-->ERROR READING LINE: " + e);
System.exit(0);
}
dataElement = inputLine.split(" ");
for (int j=0; j < nCol; j++){
dataLine[j] = Double.parseDouble(dataElement[j]);
if (dataLine[j] == missingValueIndicator)isMissing[0] = 1;
}
return dataLine;
}
// *****************************************************************************
// CLOSE FILE *
// *****************************************************************************
static public void closeFile(BufferedReader inputFile){
try{
inputFile.close();
}catch(Exception e){
System.out.println("ERROR: Unable to close file: " + e);
System.exit(0);
}
}
// *****************************************************************************
// REMOVE MISSING DATA *
// *****************************************************************************
// Now remove all missing data using the ignore[] array
// and recalculate the number of usable observations, nObs
// This method is inefficient, but it works. It removes one case at a
// time, starting from the bottom. As a case (row) is removed, the cases
// below are pushed up to take it's place.
// *************************************************************************
static public int removeMissingData(int nObs,int nCol,int ignore[],
double[][] inputArray){
int m=0;
for(int i=nObs-1; i >=0; i--){
if(ignore[i]>=0){
// the ith row contains a missing value
// remove the ith row by shifting all rows below the
// ith row up by one position, e.g. row i+1 -> row i
m++;
if (nCol > 0){
for(int j=i; j < nObs-m; j++){
for (int k=0; k < nCol; k++){
inputArray[j][k]=inputArray[j+1][k];
}
}
}
}
}
return m;
}
// ********************************************************************************
// Create Stage I/Stage II Trainer *
// ********************************************************************************
static public Trainer createTrainer(String s1, String s2) {
EpochTrainer epoch = null; // Epoch Trainer (returned by this method)
QuasiNewtonTrainer stage1Trainer; // Stage I Quasi-Newton Trainer
QuasiNewtonTrainer stage2Trainer; // Stage II Quasi-Newton Trainer
LeastSquaresTrainer stage1LS; // Stage I Least Squares Trainer
LeastSquaresTrainer stage2LS; // Stage II Least Squares Trainer
Calendar currentTimeNow ; // Calendar time tracker
// Create Epoch (Stage I/Stage II) trainer from above trainers.
System.out.println(" --> Creating Epoch Trainer");
if (s1.equals(QuasiNewton)){
// Setup stage I quasi-newton trainer
stage1Trainer = new QuasiNewtonTrainer();
//stage1Trainer.setMaximumStepsize(maxStepSize);
stage1Trainer.setMaximumTrainingIterations(stage1Iterations);
stage1Trainer.setStepTolerance(stage1StepTolerance);
if (s2.equals(QuasiNewton)){
stage2Trainer = new QuasiNewtonTrainer();
//stage2Trainer.setMaximumStepsize(maxStepSize);
stage2Trainer.setMaximumTrainingIterations(stage2Iterations);
epoch = new EpochTrainer(stage1Trainer, stage2Trainer);
}else{
if (s2.equals(LeastSquares)){
stage2LS = new LeastSquaresTrainer();
stage2LS.setInitialTrustRegion(1.0e-3);
//stage2LS.setMaximumStepsize(maxStepSize);
stage2LS.setMaximumTrainingIterations(stage2Iterations);
epoch = new EpochTrainer(stage1Trainer, stage2LS);
}else{
epoch = new EpochTrainer(stage1Trainer);
}
}
}else{
// Setup stage I least squares trainer
stage1LS = new LeastSquaresTrainer();
stage1LS.setInitialTrustRegion(1.0e-3);
stage1LS.setMaximumTrainingIterations(stage1Iterations);
//stage1LS.setMaximumStepsize(maxStepSize);
if (s2.equals(QuasiNewton)){
stage2Trainer = new QuasiNewtonTrainer();
//stage2Trainer.setMaximumStepsize(maxStepSize);
stage2Trainer.setMaximumTrainingIterations(stage2Iterations);
epoch = new EpochTrainer(stage1LS, stage2Trainer);
}else{
if (s2.equals(LeastSquares)){
stage2LS = new LeastSquaresTrainer();
stage2LS.setInitialTrustRegion(1.0e-3);
//stage2LS.setMaximumStepsize(maxStepSize);
stage2LS.setMaximumTrainingIterations(stage2Iterations);
epoch = new EpochTrainer(stage1LS, stage2LS);
}else{
epoch = new EpochTrainer(stage1LS);
}
}
}
epoch.setNumberOfEpochs(nEpochs);
epoch.setEpochSize(epochSize);
epoch.setRandom(new com.imsl.stat.Random(1234567));
epoch.setRandomSamples(new com.imsl.stat.Random(12345),
new com.imsl.stat.Random(67891));
System.out.println(" --> Trainer: Stage I - "+s1+" Stage II "+s2);
System.out.println(" --> Number of Epochs: " + nEpochs);
System.out.println(" --> Epoch Size: " + epochSize);
// Describe optimization setup for Stage I training
System.out.println(" --> Creating Stage I Trainer");
System.out.println(" --> Stage I Iterations: " + stage1Iterations);
System.out.println(" --> Stage I Step Tolerance: " + stage1StepTolerance);
System.out.println(" --> Stage I Relative Tolerance: " + stage1RelativeTolerance);
System.out.println(" --> Stage I Step Size: " + "DEFAULT");
System.out.println(" --> Stage I Trace: " + trace);
if(s2.equals(QuasiNewton) || s2.equals(LeastSquares)){
// Describe optimization setup for Stage II training
System.out.println(" --> Creating Stage II Trainer");
System.out.println(" --> Stage II Iterations: " + stage2Iterations);
System.out.println(" --> Stage II Step Tolerance: " + stage2StepTolerance);
System.out.println(" --> Stage II Relative Tolerance: " + stage2RelativeTolerance);
System.out.println(" --> Stage II Step Size: " + "DEFAULT");
System.out.println(" --> Stage II Trace: " + trace);
}
if (trace) {
try {
Handler handler = new FileHandler(trainingLogFile);
Logger logger = Logger.getLogger("com.imsl.datamining.neural");
logger.setLevel(Level.FINEST);
logger.addHandler(handler);
handler.setFormatter(EpochTrainer.getFormatter());
System.out.println(" --> Training Log Stored in "+trainingLogFile);
} catch (Exception e) {
e.printStackTrace();
}
}
currentTimeNow = Calendar.getInstance();
System.out.println("--> Starting Network Training at "+currentTimeNow.getTime());
// Return Stage I/Stage II trainer
return epoch;
}
// *****************************************************************************
// WRITE SERIALIZED OBJECT TO A FILE *
// *****************************************************************************
static public void write(Object obj, String filename)
throws IOException {
FileOutputStream fos = new FileOutputStream(filename);
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(obj);
oos.close();
fos.close();
}
}
// *****************************************************************************
--> Starting Data Preprocessing at: Thu Oct 14 17:27:04 CDT 2004
--> Number of continuous variables: 3
--> Number of output variables: 1
--> Number of Missing Observations: 16507
--> Total Number of Training Patterns: 118519
--> Number of Usable Training Patterns: 102012
--> Starting Preprocessing of Training Patterns
--> Creating Feed Forward Network Object
--> Feed Forward Network Created with 2 Layers
--> Training Network using Epoch Trainer
--> Creating Epoch Trainer
--> Trainer: Stage I - quasi-newton Stage II quasi-newton
--> Number of Epochs: 20
--> Epoch Size: 5000
--> Creating Stage I Trainer
--> Stage I Iterations: 5000
--> Stage I Step Tolerance: 1.0E-9
--> Stage I Relative Tolerance: 1.0E-11
--> Stage I Step Size: DEFAULT
--> Stage I Trace: true
--> Creating Stage II Trainer
--> Stage II Iterations: 5000
--> Stage II Step Tolerance: 1.0E-9
--> Stage II Relative Tolerance: 1.0E-11
--> Stage II Step Size: DEFAULT
--> Stage II Trace: true
--> Training Log Stored in NeuralNetworkEx1.log
--> Starting Network Training at Thu Oct 14 17:32:33 CDT 2004
--> The last global step failed to locate a lower point than the
current error value. The current solution may be an approximate
solution and no more accuracy is possible, or the step tolerance
may be too larger.
--> Network Training Completed at: Thu Oct 14 18:18:08 CDT 2004
--> Training Time: 2735.341 seconds
***********************************************
--> SSE: 3.88076
--> RMS: 0.12284768
--> Laplacian Error: 125.36781
--> Scaled Laplacian Error: 0.20686063
--> Largest Absolute Residual: 0.500993
***********************************************
--> Getting Network Weights and Gradients
--> Network Weights and Gradients:
***********************************************
Weights and Gradients
Weight Gradient
1.921 -0
1.569 0
-199.709 0
0.065 -0
-0.003 0
106.62 0
1.221 -0
0.787 0
119.169 0
-129.8 0
146.822 0
-0.076 0
-6.022 -0
-5.257 0.001
2.19 0
-0.377 0
***********************************************
--> Saving Trained Network into NeuralNetworkEx1.ser
--> Saving Network Trainer into NeuralNetworkTrainerEx1.ser
--> Saving xData into NeuralNetworkxDataEx1.ser
--> Saving yData into NeuralNetworkyDataEx1.ser
The above output indicates that the network successfully completed its training. The final sum of squared errors was 3.88, and the RMS (the scaled version of the sum of squared errors) was 0.12. All of the gradients at this solution are nearly zero, which is expected if network training found a local or global optima. Non-zero gradients usually indicate there was a problem with network training.
Examining the training log for this application, NeuralNetworkEx1.log , illustrates the importance of Stage II training.
.
.
.
End EpochTrainer Stage 1
Best Epoch 15
Error Status 17
Best Error 0.03979299031789641
Best Residual 0.03979299031789641
SSE 1072.1281419136983
RMS 33.93882798404427
Laplacian 429.30253410528974
Scaled Laplacian 0.7083620086220087
Max Residual 11.837166167929052
Exiting com.imsl.datamining.neural.EpochTrainer.train Stage 1
Beginning com.imsl.datamining.neural.EpochTrainer.train Stage 2
.
.
.
Exiting com.imsl.datamining.neural.EpochTrainer.train Stage 2
Summary
Error Status 1
Best Error 3.88076005209094
SSE 3.88076005209094
RMS 0.12284767343218107
Laplacian 125.3678136373788
Scaled Laplacian 0.20686063843020083
Max Residual 0.5009930332151435
The training log indicates that the best Stage I epoch occurred at iteration 15, and that 17 of the 20 Stage I epochs detected a problem with training optimization. Other parts of the log indicate that these problems included: possible local minima, and maximum number of iterations exceeded. Although these problems are warning messages and not true errors, they do indicate that convergence to a global optima is uncertain for 17 of the 20 epochs. Possibly increasing the epoch size might have provided more stable Stage I training.
More disturbing is the fact that for the best epoch=15, the sum of squared errors totaled over all training patterns is 1072.13. Epoch 15 was used as the starting point for the Stage II training which was able to reduce this sum of squared errors to 3.88. This suggests that although the epoch size, epochSize=5000, was too small for effective Stage I training, the Stage II trainer was able to locate a better solution.
However, even the Stage II trainer returned a non-zero error status, errorStatus=1. This was a warning that the Stage II trainer may have found a local optima. Further attempts were made to determine whether a better network could be found, but these alternate solutions only marginally lowered the sum of squared errors.
The trained network was serialized and stored into four files:
the network file - NeuralNetworkEx1.ser,
the trainer file - NeuralNetworkTrainerEx1.ser,
the xData file - NeuralNetworkxDataEx1.ser, and
the yData file - NeuralNetworkyDataEx1.ser.