Performs Kalman filtering and evaluates the likelihood function for the state-space model.
For a list of all members of this type, see KalmanFilter Members.
System.Object
Imsl.Stat.KalmanFilter
Thread Safety
Public static (Shared in Visual Basic) members of this type are safe for multithreaded operations. Instance members are not guaranteed to be thread-safe.
Remarks
Class KalmanFilter is based on a recursive algorithm given by Kalman (1960), which has come to be known as the KalmanFilter. The underlying model is known as the state-space model. The model is specified stage by stage where the stages generally correspond to time points at which the observations become available. KalmanFilter avoids many of the computations and storage requirements that would be necessary if one were to process all the data at the end of each stage in order to estimate the state vector. This is accomplished by using previous computations and retaining in storage only those items essential for processing of future observations.
The notation used here follows that of Sallas and Harville (1981). Let ![]() (input in
(input in y using method Update) be the ![]() vector of observations that become available at time k. The subscript k is used here rather than t, which is more customary in time series, to emphasize that the model is expressed in stages
vector of observations that become available at time k. The subscript k is used here rather than t, which is more customary in time series, to emphasize that the model is expressed in stages ![]() and that these stages need not correspond to equally spaced time points. In fact, they need not correspond to time points of any kind. The observation equation for the state-space model is
and that these stages need not correspond to equally spaced time points. In fact, they need not correspond to time points of any kind. The observation equation for the state-space model is
Here, ![]() (input in
(input in z using method update) is an ![]() known matrix and
known matrix and ![]() is the
is the ![]() state vector. The state vector
state vector. The state vector ![]() is allowed to change with time in accordance with the state equation
is allowed to change with time in accordance with the state equation
starting with ![]() .
.
The change in the state vector from time k to k + 1 is explained in part by the transition matrix
![]() (the identity matrix by default, or optionally using method
(the identity matrix by default, or optionally using method SetTransitionMatrix), which is assumed known. It is assumed that the q-dimensional ![]() are independently distributed multivariate normal with mean vector 0 and variance-covariance matrix
are independently distributed multivariate normal with mean vector 0 and variance-covariance matrix ![]() , that the
, that the ![]() -dimensional
-dimensional ![]() are independently distributed multivariate normal with mean vector 0 and variance-covariance matrix
are independently distributed multivariate normal with mean vector 0 and variance-covariance matrix ![]() , and that the
, and that the ![]() and
and ![]() are independent of each other. Here,
are independent of each other. Here, ![]() is the mean of
is the mean of ![]() and is assumed known,
and is assumed known, ![]() is an unknown positive scalar.
is an unknown positive scalar. ![]() (input in
(input in Q) and ![]() (input in
(input in R) are assumed known.
Denote the estimator of the realization of the state vector ![]() given the observations
given the observations ![]() by
by
By definition, the mean squared error matrix for
is
At the time of the k-th invocation, we have
and
![]() , which were computed from the k-1-st invocation, input in
, which were computed from the k-1-st invocation, input in b and covb, respectively. During the k-th invocation, KalmanFilter computes the filtered estimate
along with ![]() . These quantities are given by the update equations:
. These quantities are given by the update equations:
where
and where
Here, ![]() (stored in v) is the one-step-ahead prediction error, and
(stored in v) is the one-step-ahead prediction error, and ![]() is the variance-covariance matrix for
is the variance-covariance matrix for ![]() .
. ![]() is stored in
is stored in covv. The "start-up values" needed on the first invocation of KalmanFilter are
and ![]() input via
input via b and covb, respectively. Computations for the k-th invocation are completed by KalmanFilter computing the one-step-ahead estimate
along with ![]() given by the prediction equations:
given by the prediction equations:
If both the filtered estimates and one-step-ahead estimates are needed by the user at each time point, KalmanFilter can be used twice for each time point-first without methods SetTransitionMatrix and SetQ to produce
and ![]() , and second without method
, and second without method Update to produce
and ![]() (Without methods
(Without methods SetTransitionMatrix and SetQ, the prediction equations are skipped. Without method update, the update equations are skipped.).
Often, one desires the estimate of the state vector more than one-step-ahead, i.e., an estimate of
is needed where ![]() . At time j,
. At time j, KalmanFilter is invoked with method Update to compute
Subsequent invocations of KalmanFilter without method Update can compute
Computations for
and ![]() assume the variance-covariance matrices of the errors in the observation equation and state equation are known up to an unknown positive scalar multiplier,
assume the variance-covariance matrices of the errors in the observation equation and state equation are known up to an unknown positive scalar multiplier, ![]() . The maximum likelihood estimate of
. The maximum likelihood estimate of ![]() based on the observations
based on the observations ![]() , is given by
, is given by
where
N and SS are the input/output arguments n and sumOfSquares.
If ![]() is known, the
is known, the ![]() and
and ![]() can be input as the variance-covariance matrices exactly. The earlier discussion is then simplified by letting
can be input as the variance-covariance matrices exactly. The earlier discussion is then simplified by letting ![]() .
.
In practice, the matrices ![]() ,
, ![]() , and
, and ![]() are generally not completely known. They may be known functions of an unknown parameter vector
are generally not completely known. They may be known functions of an unknown parameter vector ![]() . In this case,
. In this case, KalmanFilter can be used in conjunction with an optimization class (see class MinUnconMultiVar, IMSL C# Library Math namespace), to obtain a maximum likelihood estimate of ![]() . The natural logarithm of the likelihood function for
. The natural logarithm of the likelihood function for ![]() differs by no more than an additive constant from
differs by no more than an additive constant from
(Harvey 1981, page 14, equation 2.21).
Here,
(stored in logDeterminant) is the natural logarithm of the determinant of V where ![]() is the variance-covariance matrix of the observations.
is the variance-covariance matrix of the observations.
Minimization of ![]() over all
over all ![]() and
and ![]() produces maximum likelihood estimates. Equivalently, minimization of
produces maximum likelihood estimates. Equivalently, minimization of ![]() where
where
produces maximum likelihood estimates
Minimization of ![]() instead of
instead of ![]() , reduces the dimension of the minimization problem by one. The two optimization problems are equivalent since
, reduces the dimension of the minimization problem by one. The two optimization problems are equivalent since
minimizes ![]() for all
for all ![]() , consequently,
, consequently,
can be substituted for ![]() in
in ![]() to give a function that differs by no more than an additive constant from
to give a function that differs by no more than an additive constant from ![]() .
.
The earlier discussion assumed ![]() to be nonsingular. If
to be nonsingular. If ![]() is singular, a modification for singular distributions described by Rao (1973, pages 527-528) is used. The necessary changes in the preceding discussion are as follows:
is singular, a modification for singular distributions described by Rao (1973, pages 527-528) is used. The necessary changes in the preceding discussion are as follows:
- Replace
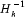 by a generalized inverse.
by a generalized inverse. - Replace
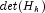 by the product of the nonzero eigenvalues of
by the product of the nonzero eigenvalues of 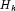 .
. - Replace N by
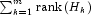
Maximum likelihood estimation of parameters in the Kalman filter is discussed by Sallas and Harville (1988) and Harvey (1981, pages 111-113).
Requirements
Namespace: Imsl.Stat
Assembly: ImslCS (in ImslCS.dll)
See Also
KalmanFilter Members | Imsl.Stat Namespace | Example