Analyzes censored survival data using a generalized linear model.
Synopsis
#include <imsls.h>
int imsls_f_survival_glm (int n_observations, int n_class, int n_continuous, int model, float x[], ..., 0)
The type double function is imsls_d_survival_glm.
Required Arguments
int
n_observations (Input)
Number of
observations.
int n_class
(Input)
Number of classification variables.
int
n_continuous (Input)
Number of continuous
variables.
int model
(Input)
Argument model specifies the
model used to analyze the data.
|
model |
PDF of the Response Variable |
|
0 |
Exponential |
|
1 |
Linear hazard |
|
2 |
Log-normal |
|
3 |
Normal |
|
4 |
Log-logistic |
|
5 |
Logistic |
|
6 |
Log least extreme value |
|
7 |
Least extreme value |
|
8 |
Log extreme value |
|
9 |
Extreme value |
|
10 |
Weibull |
See the “Description” section for more information about these models.
float x[]
(Input)
Array of size n_observations by
(n_class + n_continuous) + m
containing data for the independent variables, dependent variable, and optional
parameters.
The columns must be ordered such that the first n_class columns contain data for the class variables, the next n_continuous columns contain data for the continuous variables, and the next column contains the response variable. The final (and optional) m − 1 columns contain the optional parameters.
Return Value
An integer value indicating the number of estimated coefficients in the model.
Synopsis with Optional Arguments
#include <imsls.h>
int
imsls_f_survival_glm (int n_observations, int n_class, int n_continuous, int
model,
float x[],
IMSLS_X_COL_CENSORING, int icen, int ilt, int irt,
IMSLS_X_COL_DIM, int
x_col_dim,
IMSLS_X_COL_FREQUENCIES, int ifrq,
IMSLS_X_COL_FIXED_PARAMETER, int ifix,
IMSLS_X_COL_VARIABLES, int
iclass[],
int
icontinuous[], int iy
IMSLS_EPS, float
eps,
IMSLS_MAX_ITERATIONS, int
max_iterations,
IMSLS_INTERCEPT,
IMSLS_NO_INTERCEPT,
IMSLS_INFINITY_CHECK, int
lp_max
IMSLS_NO_INFINITY_CHECK
IMSLS_EFFECTS, int
n_effects,
int
n_var_effects[],
int indices_effects,
IMSLS_INITIAL_EST_INTERNAL,
IMSLS_INITIAL_EST_INPUT, int
n_coef_input, float estimates[],
IMSLS_MAX_CLASS, int
max_class,
IMSLS_CLASS_INFO, int
**n_class_values, float **class_values,
IMSLS_CLASS_INFO_USER, int
n_class_values[], float class_values[],
IMSLS_COEF_STAT, float
**coef_statistics,
IMSLS_COEF_STAT_USER, float
coef_statistics[],
IMSLS_CRITERION, float
*criterion,
IMSLS_COV, float
**cov,
IMSLS_COV_USER, float
cov[],
IMSLS_MEANS, float
**means,
IMSLS_MEANS_USER, float
means[],
IMSLS_CASE_ANALYSIS, float
**case_analysis,
IMSLS_CASE_ANALYSIS_USER, float
case_analysis[],
IMSLS_LAST_STEP, float
**last_step,
IMSLS_LAST_STEP_USER, float
last_step[],
IMSLS_OBS_STATUS, int
**obs_status,
IMSLS_OBS_STATUS_USER, int
obs_status[],
IMSLS_ITERATIONS, int *n, float
**iterations,
IMSLS_ITERATIONS_USER, int *n, float
iterations[],
IMSLS_SURVIVAL_INFO, Imsls_f_survival
**survival_info
IMSLS_N_ROWS_MISSING, int
*n_rows_missing,
0)
Optional Arguments
IMSLS_X_COL_DIM, int x_col_dim
(Input)
Column dimension of input array x.
Default: x_col_dim = n_class + n_continuous + 1
IMSLS_X_COL_CENSORING, int icen, int ilt, int irt
(Input)
Parameter icen is the column in
x containing the
censoring code for each observation.
|
x [i] [icen] |
Censoring type |
|
0 |
Exact failure at x [i] [irt] |
|
1 |
Right Censored. The response is greater than x [i] [irt]. |
|
2 |
Left Censored. The response is less than or equal to x [i] [irt]. |
|
3 |
Interval Censored. The response is greater than x [i] [irt], but less than or equal to x [i] [ilt]. |
Parameter ilt is the column number of x containing the upper endpoint of the failure interval for interval- and left-censored observations. If there are no left-censored or interval-censored observations, ilt should be set to −1.
Parameter irt is the column number of x containing the lower endpoint of the failure interval for interval- and right-censored observations. If there are no left-censored or interval-censored observations, irt should be set to −1.
Exact failure times are specified in column iy of x. By default, iy is column n_class + n_continuous of x. The default can be changed if keyword IMSLS_X_COL_VARIABLES is specified.
Note that it is allowable to set iy = irt, since a row with an iy value will never have an irt value, and vice versa. This use is illustrated in Example 2.
IMSLS_FREQUENCIES,
int
ifrq (Input)
Column number of
x containing the frequency of response for each
observation.
IMSLS_FIXED_PARAMETER,
int
ifix (Input)
Column number in
x containing a fixed parameter for each observation that is
added to the linear response prior to computing the model parameter. The “fixed”
parameter allows one to test hypothesis about the parameters via the
log-likelihoods.
IMSLS_X_COL_VARIABLES
int
iclass[],
int
icontinuous[],
int
iy (Input)
This keyword allows specification
of the variables to be used in the analysis, and overrides the default
ordering of variables described for input argument x. Columns are numbered from 0 to x_col_dim − 1. To avoid errors, always specify the keyword
IMSLS_X_COL_DIM when using this keyword.
Argument iclass is an index vector of length n_class containing the column numbers of x that correspond to classification variables.
Argument icontinuous is an index vector of length n_continuous containing the column numbers of x that correspond to continuous variables.
Argument iy corresponds to the column of x which contains the dependent variable.
IMSLS_EPS,
float
eps (Input)
Argument
eps is the convergence criterion. Convergence is assumed when
the maximum relative change in any coefficient estimate is less than
eps from one iteration to the next or when the relative change
in the log-likelihood, criterion, from one iteration to the next is less
than eps/100.0.
Default: eps = 0.001
IMSLS_MAX_ITERATIONS,
int
max_iterations (Input)
Maximum
number of iterations. Use max_iterations = 0 to compute the Hessian, stored in
cov, and the Newton step, stored in last_step, at the initial estimates (The initial estimates must
be input. Use keyword IMSLS_INITIAL_EST_INPUT).
Default: max_iterations = 30
IMSLS_INTERCEPT, or
IMSLS_NO_INTERCEPT,
By
default, or if IMSLS_INTERCEPT is
specified, the intercept is automatically included in the model. If IMSLS_NO_INTERCEPT is
specified, there is no intercept in the model (unless otherwise provided for by
the user).
IMSLS_INFINITY_CHECK,
int
lp_max (Input)
Remove a right-
or left-censored observation from the log-likelihood whenever the probability of
the observation exceeds 0.995. At convergence, use linear programming to check
that all removed observations actually have infinite linear response
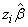
obs_status [i] is set to 2 if the linear response is infinite (See optional argument IMSLS_OBS_STATUS). If not all removed observations have infinite linear response, re-compute the estimates based upon the observations with finite
Parameter lp_max
is the maximum number of observations that can
be handled in the linear programming. Setting lp_max = n_observations is
always sufficient.
Default: No
infinity checking; lp_max = 0
IMSLS_NO_INFINITY_CHECK
Iterates without checking for infinite estimates. This
option is the default.
IMSLS_EFFECTS,
int
n_effects,
int
n_var_effects[], int indices_effects[]
(Input)
Use this keyword to specify the effects in
the model.
Variable n_effects is the number of effects (sources of variation) in the model. Variable n_var_effects is an array of length n_effects containing the number of variables associated with each effect in the model.
Argument indices_effects is an index array of length n_var_effects [0] + n_var_effects [1] + … + n_var_effects [n_effects − 1]. The first n_var_effects [0] elements give the column numbers of x for each variable in the first effect. The next n_var_effects[1] elements give the column numbers for each variable in the second effect. The last n_var_effects [n_effects − 1] elements give the column numbers for each variable in the last effect.
IMSLS_INITIAL_EST_INTERNAL, or
IMSLS_INITIAL_EST_INPUT, int n_coef_input, float estimates[] (Input)
By default, or if IMSLS_INIT_INTERNAL is specified, then unweighted linear regression is used to obtain initial estimates. If IMSLS_INITIAL_EST_INPUT is specified, then the n_coef_input elements of estimates contain initial estimates of the parameters (which requires that the user know the number of coefficients in the model prior to the call to survival_glm). See optional argument IMSLS_COEF_STAT for a description of the “nuisance” parameter, which is the first element of array estimates.
IMSLS_MAX_CLASS,
int
max_class (Input)
An upper
bound on the sum of the number of distinct values taken on by each
classification variable. Internal workspace usage can be significantly
reduced with an appropriate choice of max_class.
Default: max_class = n_observations * n_class
IMSLS_CLASS_INFO,
int
**n_class_values,
float
**class_values
(Output)
Argument n_class_values is the address of a pointer to the internally allocated
array of length n_class containing the number of values taken by each
classification variable; the i-th classification variable has
n_class_values [i] distinct values. Argument class_values is the address of a pointer to the internally allocated
array of length

containing the distinct values of the classification variables in ascending order. The first n_class_values [0] elements of class_values contain the values for the first classification variables, the next n_class_values [1] elements contain the values for the second classification variable, etc.
IMSLS_CLASS_INFO_USER,
int
n_class_values[],
float class_values[]
(Output)
Storage for arrays n_class_values and
class_values is
provided by the user. See IMSLS_CLASS_INFO.
IMSLS_COEF_STAT,
float
**coef_statistics (Output)
Address of a pointer to an internally
allocated array of size n_coefficients * 4 containing the parameter
estimates and associated statistics:
|
Column |
Statistic |
|
0 |
Coefficient estimate. |
|
1 |
Estimated standard deviation of the estimated coefficient. |
|
2 |
Asymptotic normal score for testing that the coefficient is zero. |
|
3 |
The p-value associated with the normal score in Column 2. |
When present in the model, the first coefficient in coef_statistics is the estimate of the “nuisance” parameter, and the remaining coefficients are estimates of the parameters associated with the “linear” model, beginning with the intercept, if present. Nuisance parameters are as follows:
|
model |
|
|
0 |
No nuisance parameter |
|
1 |
Coefficient of the quadratic term in time, θ |
|
2-9 |
Scale parameter, σ |
|
10 |
Shape parameter, θ |
IMSLS_COEF_STAT_USER, float
coef_statistics[] (Output)
Storage for array coef_statistics is provided by the user. See IMSLS_COEF_STAT.
IMSLS_CRITERION,
float
*criterion (Output)
Optimized
criterion. The criterion to be maximized is a constant plus the
log-likelihood.
IMSLS_COV,
float
**cov (Output)
Address of a
pointer to the internally allocated array of size n_coefficients by n_coefficients containing the estimated asymptotic covariance matrix
of the coefficients. For max_iterations = 0, this is the Hessian computed at the initial
parameter estimates.
IMSLS_COV_USER,
float
cov[] (Ouput)
Storage for array
cov is provided by the user. See IMSLS_COV.
IMSLS_MEANS,
float
**means (Output)
Address of a
pointer to the internally allocated array containing the means of the design
variables. The array is of length n_coefficients − m if IMSLS_NO_INTERCEPT is specified, and of length n_coefficients − m − 1 otherwise. Here, m is equal to 0 if
model = 0, and equal to 1 otherwise.
IMSLS_MEANS_USER,
float
means[] (Output)
Storage for
array means is provided by the user. See IMSLS_MEANS.
IMSLS_CASE_ANALYSIS,
float
**case_statistics (Output)
Address of a pointer to the internally
allocated array of size n_observations by 5 containing the case analysis
below:
|
Column |
Statistic |
|
0 |
Estimated predicted value. |
|
1 |
Estimated influence or leverage. |
|
2 |
Estimated residual. |
|
3 |
Estimated cumulative hazard. |
|
4 |
Non-censored observations: Estimated density at the observation failure time and covariate values. Censored observations: The corresponding estimated probability. |
If max_iterations = 0, case_statistics is an array of length n_observations containing the estimated probability (for censored observations) or the estimated density (for non-censored observations)
IMSLS_CASE_ANALYSIS_USER,
float
case_statistics[] (Output)
Storage for array case_statistics is provided by the user. See IMSLS_CASE_ANALYSIS.
IMSLS_LAST_STEP,
float
**last_step (Output)
Address of
a pointer to the internally allocated array of length n_coefficients containing the last parameter updates (excluding step
halvings). Parameter last_step is computed as the inverse of the matrix of second partial
derivatives times the vector of first partial derivatives of the log-likelihood.
When max_iterations = 0, the derivatives are computed at the
initial estimates.
IMSLS_LAST_STEP_USER,
float
last_step[] (Output)
Storage
for array last_step is provided by the user. See IMSLS_LAST_STEP.
IMSLS_OBS_STATUS,
int
**obs_status (Output)
Address
of a pointer to the internally allocated array of length n_observations indicating which observations are included in the
extended likelihood.
|
Obs_status [i] |
Status of Observation |
|
0 |
Observation i is in the likelihood |
|
1 |
Observation i cannot be in the likelihood because it contains at least one missing value in x. |
|
2 |
Observation i is not in the likelihood. Its estimated parameter is infinite. |
IMSLS_OBS_STATUS_USER, int
obs_status[] (Output)
Storage for array obs_status is provided
by the user. See IMSLS_OBS_STATUS.
IMSLS_ITERATIONS, int *n, float
**iterations (Output)
Address of a pointer to the
internally allocated array of size, n by 5
containing information about each iteration of the analysis, where n is equal to the
number of iterations.
|
column |
Statistic |
|
0 |
Method of iteration Q-N Step = 0 N-R Step = 1 |
|
1 |
Iteration number |
|
2 |
Step size |
|
3 |
Maximum scaled coefficient update |
|
4 |
Log-likelihood |
IMSLS_ITERATIONS_USER, int *n, float
iterations[] (Output)
Storage for array iterations is
provided by the user. See IMSLS_ITERATIONS.
IMSLS_SURVIVAL_INFO,
Imsls_f_survival
**survival_info (Output)
Address of the pointer to an
internally allocated structure of type Imsls_f_survival containing
information about the survival analysis. This structure is required input for
function imsls_f_survival_estimates.
IMSLS_N_ROWS_MISSING, int
*n_rows_missing (Output)
Number of rows of data that
contain missing values in one or more of the following vectors or columns of
x: iy, icen, ilt, irt, ifrq, ifix, iclass, icontinuous, or indices_effects.
Comments
1. Dummy variables are generated for the classification variables as follows: An ascending list of all distinct values of each classification variable is obtained and stored in class_values. Dummy variables are then generated for each but the last of these distinct values. Each dummy variable is zero unless the classification variable equals the list value corresponding to the dummy variable, in which case the dummy variable is one. See keyword IMSLS_LEAVE_OUT_LAST for optional argument IMSLS_DUMMY in imsls_f_regressors_for_glm (Chapter 2, “Regression”;).
2. The “product” of a classification variable with a covariate yields dummy variables equal to the product of the covariate with each of the dummy variables associated with the classification variable.
3. The “product” of two classification variables yields dummy variables in the usual manner. Each dummy variable associated with the first classification variable multiplies each dummy variable associated with the second classification variable. The resulting dummy variables are such that the index of the second classification variable varies fastest.
Description
Function imsls_f_survival_glm computes the maximum likelihood estimates of parameters and associated statistics in generalized linear models commonly found in survival (reliability) analysis. Although the terminology used will be from the survival area, the methods discussed have applications in many areas of data analysis, including reliability analysis and event history analysis. These methods can be used anywhere a random variable from one of the discussed distributions is parameterized via one of the models available in imsls_f_survival_glm. Thus, while it is not advisable to do so, standard multiple linear regression can be performed by routine imsls_f_survival_glm. Estimates for any of 10 standard models can be computed. Exact, left-censored, right-censored, or interval-censored observations are allowed (note that left censoring is the same as interval censoring with the left endpoint equal to the left endpoint of the support of the distribution).
Let η = xTβ be the linear
parameterization, where x is a design vector obtained by imsls_f_survival_glm
via function imsls_f_regressors_for_glm
from a row of x,
and β is a vector of
parameters associated with the linear model. Let
T denote the random
response variable and S(t) denote the probability that
T > t. All models considered also allow a fixed
parameter wi for observation
i (input in column ifix
of x).
Use of this parameter is discussed below. There also may be nuisance parameters
θ > 0, or
σ > 0 to be
estimated (along with β)
in the various models. Let Φ denote the cumulative normal
distribution. The survival models available in imsls_f_survival_glm
are:
|
model |
Name |
S (t) |
|
0 |
Exponential |
exp [−t exp (wi + η)] |
|
1 |
Linear hazard |
|
|
2 |
Log-normal |
|
|
3 |
Normal |
|
|
4 |
Log-logistic |
|
|
5 |
Logistic |
|
|
6 |
Log least extreme value |
|
|
7 |
Least extreme value |
|
|
8 |
Log extreme value |
|
|
9 |
Extreme value |
|
|
10 |
Weibull |
|
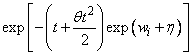
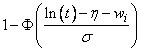
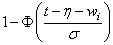
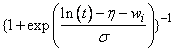
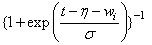
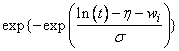
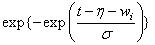
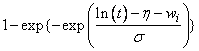
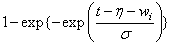

Note that the log-least-extreme-value model is a reparameterization of the Weibull model. Moreover, models 0, 1, 2, 4, 6, 8, and 10 require that T > 0, while all of the remaining models allow any value for T, −∞ < T < ∞.
Each row vector in the data matrix can represent a single observation; or, through the use of vector frequencies, each row can represent several observations. Also note that classification variables and their products are easily incorporated into the models via the usual regression-type specifications.
The constant parameter Wi is input in x and may be used for a number of purposes. For example, if the parameter in an exponential model is known to depend upon the size of the area tested, volume of a radioactive mass, or population density, etc., then a multiplicative factor of the exponential parameter λ = exp (xβ) may be known apriori. This factor can be input in Wi (Wi is the log of the factor).
An alternate use of Wi is as follows: It may
be that λ = exp (x1β1 + x2β2), where
β2 is known. Letting
Wi = x2β2, estimates for β1 can be obtained via
imsls_f_survival_glm
with the known fixed values for β2. Standard methods can
then be used to test hypothesis about β1 via computed
log-likelihoods.
Computational Details
The computations proceed as follows:
1. The input parameters are checked for consistency and validity.
∙ Estimates of the means of the “independent” or design variables are computed. Means are computed as
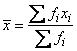
2. If initial estimates are not provided by the user (see optional argument IMSLS_INITIAL_EST_INPUT), the initial estimates are calculated as follows:
∙ Models 2-10
A. Kaplan-Meier estimates of the survival probability,
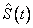
at the upper limit of each failure interval are obtained. (Because upper limits are used, interval- and left-censored data are assumed to be exact failures at the upper endpoint of the failure interval.) The Kaplan-Meier estimate is computed under the assumption that all failure distributions are identical (i.e., all β’s but the intercept, if present, are assumed to be zero).
B. If there is an intercept in the model, a simple linear regression is performed predicting
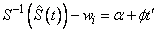
where
tʹ is computed at
the upper endpoint of each failure interval,
tʹ = t in
models 3, 5, 7, and 9, and tʹ = ln (t)
in models 2, 4, 6, 8, and 10, and wi is the fixed constant, if present.
If there is no intercept in the model, then α is fixed at zero, and the model
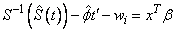
is fit instead. In this model, the coefficients β are used in place of the location estimate α above. Here
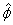
is estimated from the simple linear regression with α = 0.
C. If the intercept is in the model, then in log-location-scale models (models 1-8),
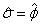
and the
initial estimate of the intercept is assumed to be 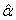 .
.
In the Weibull model
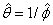
and the
intercept is assumed to be . Initial estimates of all parameters β, other than the intercept,
are assumed to be zero. If there is no intercept in the model, the scale
parameter is estimated as above, and the estimates
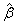
from Step 2 are used as initial estimates for the β’s.
∙ Models 0 and 1
For the exponential models (model = 0 or 1), the “average total time on” test statistic is used to obtain an estimate for the intercept. Specifically, let Tt denote the total number of failures divided by the total time on test. The initial estimates for the intercept is then ln(Tt). Initial estimates for the remaining parameters β are assumed to be zero, and if model = 1, the initial estimate for the linear hazard parameter θ is assumed to be a small positive number. When the intercept is not in the model, the initial estimate for the parameter θ is assumed to be a small positive number, and initial estimates of the parameters β are computed via multiple linear regression as in Part A.
3. A quasi-Newton algorithm is used in the initial iterations based on a Hessian estimate
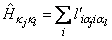
where lʹiαj is the partial derivative of the i-th term in the log-likelihood with respect to the parameter αj, and aj denotes one of the parameter to be estimated.
When the relative change in the log-likelihood from one iteration to the next is 0.1 or less, exact second partial derivatives are used for the Hessian so the Newton-Rapheson iteration is used.
If the initial step size results in an increase in the log-likelihood, the full step is used. If the log-likelihood decreases for the initial step size, the step size is halved, and a check for an increase in the log-likelihood performed. Step-halving is performed (as a simple line search) until an increase in the log-likelihood is detected, or until the step size becomes very small (the initial step size is 1.0).
4. Convergence is assumed when the maximum relative change in any coefficient update from one iteration to the next is less than eps or when the relative change in the log-likelihood from one iteration to the next is less than eps/100. Convergence is also assumed after maxit iterations or when step halving leads to a very small step size with no increase in the log-likelihood.
5. If requested (see optional argument IMSLS_INFINITY_CHECK), then the methods of Clarkson and Jennrich (1988) are used to check for the existence of infinite estimates in
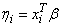
As an example of a situation in which infinite estimates can occur, suppose that observation j is right-censored with tj > 15 in a normal distribution model in which the mean is
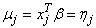
where xj is the observation design vector. If the design vector xj for parameter βm is such that xjm = 1 and xim = 0 for all i ≠ j, then the optimal estimate of βm occurs at
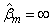
leading to an infinite estimate of both βm and ηj. In imsls_f_survival_glm, such estimates can be “computed”.
In all models fit by imsls_f_survival_glm, infinite estimates can only occur when the optimal estimated probability associated with the left- or right-censored observation is 1. If infinity checking is on, left- or right-censored observations that have estimated probability greater than 0.995 at some point during the iterations are excluded from the log-likelihood, and the iterations proceed with a log-likelihood based on the remaining observations. This allows convergence of the algorithm when the maximum relative change in the estimated coefficients is small and also allows for a more precise determination of observations with infinite
At convergence, linear programming is used to ensure that the eliminated observations have infinite ηi. If some (or all) of the removed observations should not have been removed (because their estimated ηi’s must be finite), then the iterations are restarted with a log-likelihood based upon the finite ηi observations. See Clarkson and Jennrich (1988) for more details.
When infinity checking is turned off (see optional argument IMSLS_NO_INFINITY_CHECK), no observations are eliminated during the iterations. In this case, the infinite estimates occur, some (or all) of the coefficient estimates
will become large, and it is likely that the Hessian will become (numerically) singular prior to convergence.
6. The case
statistics are computed as follows: Let Ii (θi)denote
the log-likelihood
of the i-th observation evaluated at θi,
let Iʹi
denote the vector of derivatives of
Ii
with respect to all parameters, Iʹh,i
denote the derivative of Ii
with respect to η = xTβ,
H denote the Hessian, and E denote expectation. Then the columns of
case_statistics are:
A. Predicted values are computed as E (T/x) according to standard formulas. If model is 4 or 8, and if s ≥ 1, then the expected values cannot be computed because they are infinite.
B. Following Cook and Weisberg (1982), the influence (or leverage) of the i-th observation is assumed to be

This quantity is a one-step approximation of the change in the estimates when the i-th observation is deleted (ignoring the nuisance parameters).
C. The “residual” is computed as Iʹh,i.
D. The cumulative hazard is computed at the observation covariate values and, for interval observations, the upper endpoint of the failure interval. The cumulative hazard also can be used as a “residual” estimate. If the model is correct, the cumulative hazards should follow a standard exponential distribution. See Cox and Oakes (1984).
Programming Notes
Indicator (dummy) variables are created for the classification variables using function imsls_f_regressors_for_glm (Chapter 2, “Regression”;) using keyword IMSLS_LEAVE_OUT_LAST as the argument to the IMSLS_DUMMY optional argument.
Examples
Example 1
This example is taken from Lawless (1982, p. 287) and involves the mortality of patients suffering from lung cancer. An exponential distribution is fit for the model
η = μ + αi + γk + β6x3 + β7x4 + β8x5
where αi is associated with a classification variable with four levels, and γk is associated with a classification variable with two levels. Note that because the computations are performed in single precision, there will be some small variation in the estimated coefficients across different machine environments.
#include <imsls.h>
main() {
static float x[40][7] = {
1.0, 0.0, 7.0, 64.0, 5.0, 411.0, 0.0,
1.0, 0.0, 6.0, 63.0, 9.0, 126.0, 0.0,
1.0, 0.0, 7.0, 65.0, 11.0, 118.0, 0.0,
1.0, 0.0, 4.0, 69.0, 10.0, 92.0, 0.0,
1.0, 0.0, 4.0, 63.0, 58.0, 8.0, 0.0,
1.0, 0.0, 7.0, 48.0, 9.0, 25.0, 1.0,
1.0, 0.0, 7.0, 48.0, 11.0, 11.0, 0.0,
2.0, 0.0, 8.0, 63.0, 4.0, 54.0, 0.0,
2.0, 0.0, 6.0, 63.0, 14.0, 153.0, 0.0,
2.0, 0.0, 3.0, 53.0, 4.0, 16.0, 0.0,
2.0, 0.0, 8.0, 43.0, 12.0, 56.0, 0.0,
2.0, 0.0, 4.0, 55.0, 2.0, 21.0, 0.0,
2.0, 0.0, 6.0, 66.0, 25.0, 287.0, 0.0,
2.0, 0.0, 4.0, 67.0, 23.0, 10.0, 0.0,
3.0, 0.0, 2.0, 61.0, 19.0, 8.0, 0.0,
3.0, 0.0, 5.0, 63.0, 4.0, 12.0, 0.0,
4.0, 0.0, 5.0, 66.0, 16.0, 177.0, 0.0,
4.0, 0.0, 4.0, 68.0, 12.0, 12.0, 0.0,
4.0, 0.0, 8.0, 41.0, 12.0, 200.0, 0.0,
4.0, 0.0, 7.0, 53.0, 8.0, 250.0, 0.0,
4.0, 0.0, 6.0, 37.0, 13.0, 100.0, 0.0,
1.0, 1.0, 9.0, 54.0, 12.0, 999.0, 0.0,
1.0, 1.0, 5.0, 52.0, 8.0, 231.0, 1.0,
1.0, 1.0, 7.0, 50.0, 7.0, 991.0, 0.0,
1.0, 1.0, 2.0, 65.0, 21.0, 1.0, 0.0,
1.0, 1.0, 8.0, 52.0, 28.0, 201.0, 0.0,
1.0, 1.0, 6.0, 70.0, 13.0, 44.0, 0.0,
1.0, 1.0, 5.0, 40.0, 13.0, 15.0, 0.0,
2.0, 1.0, 7.0, 36.0, 22.0, 103.0, 1.0,
2.0, 1.0, 4.0, 44.0, 36.0, 2.0, 0.0,
2.0, 1.0, 3.0, 54.0, 9.0, 20.0, 0.0,
2.0, 1.0, 3.0, 59.0, 87.0, 51.0, 0.0,
3.0, 1.0, 4.0, 69.0, 5.0, 18.0, 0.0,
3.0, 1.0, 6.0, 50.0, 22.0, 90.0, 0.0,
3.0, 1.0, 8.0, 62.0, 4.0, 84.0, 0.0,
4.0, 1.0, 7.0, 68.0, 15.0, 164.0, 0.0,
4.0, 1.0, 3.0, 39.0, 4.0, 19.0, 0.0,
4.0, 1.0, 6.0, 49.0, 11.0, 43.0, 0.0,
4.0, 1.0, 8.0, 64.0, 10.0, 340.0, 0.0,
4.0, 1.0, 7.0, 67.0, 18.0, 231.0, 0.0};
int n_observations = 40;
int n_class = 2;
int n_continuous = 3;
int model = 0;
int n_coef;
int icen = 6, ilt = -1, irt = 5;
int lp_max = 40;
float *coef_stat;
char *fmt = "%12.4f";
static char *clabels[] = {"", "coefficient", "s.e.", "z", "p"};
n_coef =
imsls_f_survival_glm(n_observations, n_class,
n_continuous, model, &x[0][0],
IMSLS_X_COL_CENSORING, icen, ilt, irt,
IMSLS_INFINITY_CHECK, lp_max,
IMSLS_COEF_STAT, &coef_stat,
0);
imsls_f_write_matrix("Coefficient
Statistics", n_coef, 4,
coef_stat,
IMSLS_WRITE_FORMAT, fmt,
IMSLS_NO_ROW_LABELS,
IMSLS_COL_LABELS, clabels,
0);
}
Output
Coefficient Statistics
coefficient s.e. z p
-1.1027 1.3140 -0.8392 0.4016
-0.3626 0.4446 -0.8156 0.4149
0.1271 0.4863 0.2613 0.7939
0.8690 0.5861 1.4825 0.1385
0.2697 0.3882 0.6948 0.4873
-0.5400 0.1081 -4.9946 0.0000
-0.0090 0.0197 -0.4594 0.6460
-0.0034 0.0117 -0.2912 0.7710
Example 2
This example is the same as Example 1, but more optional arguments are demonstrated.
#include <imsls.h>
main() {
static float x[40][7] = {
1.0, 0.0, 7.0, 64.0, 5.0, 411.0, 0.0,
1.0, 0.0, 6.0, 63.0, 9.0, 126.0, 0.0,
1.0, 0.0, 7.0, 65.0, 11.0, 118.0, 0.0,
1.0, 0.0, 4.0, 69.0, 10.0, 92.0, 0.0,
1.0, 0.0, 4.0, 63.0, 58.0, 8.0, 0.0,
1.0, 0.0, 7.0, 48.0, 9.0, 25.0, 1.0,
1.0, 0.0, 7.0, 48.0, 11.0, 11.0, 0.0,
2.0, 0.0, 8.0, 63.0, 4.0, 54.0, 0.0,
2.0, 0.0, 6.0, 63.0, 14.0, 153.0, 0.0,
2.0, 0.0, 3.0, 53.0, 4.0, 16.0, 0.0,
2.0, 0.0, 8.0, 43.0, 12.0, 56.0, 0.0,
2.0, 0.0, 4.0, 55.0, 2.0, 21.0, 0.0,
2.0, 0.0, 6.0, 66.0, 25.0, 287.0, 0.0,
2.0, 0.0, 4.0, 67.0, 23.0, 10.0, 0.0,
3.0, 0.0, 2.0, 61.0, 19.0, 8.0, 0.0,
3.0, 0.0, 5.0, 63.0, 4.0, 12.0, 0.0,
4.0, 0.0, 5.0, 66.0, 16.0, 177.0, 0.0,
4.0, 0.0, 4.0, 68.0, 12.0, 12.0, 0.0,
4.0, 0.0, 8.0, 41.0, 12.0, 200.0, 0.0,
4.0, 0.0, 7.0, 53.0, 8.0, 250.0, 0.0,
4.0, 0.0, 6.0, 37.0, 13.0, 100.0, 0.0,
1.0, 1.0, 9.0, 54.0, 12.0, 999.0, 0.0,
1.0, 1.0, 5.0, 52.0, 8.0, 231.0, 1.0,
1.0, 1.0, 7.0, 50.0, 7.0, 991.0, 0.0,
1.0, 1.0, 2.0, 65.0, 21.0, 1.0, 0.0,
1.0, 1.0, 8.0, 52.0, 28.0, 201.0, 0.0,
1.0, 1.0, 6.0, 70.0, 13.0, 44.0, 0.0,
1.0, 1.0, 5.0, 40.0, 13.0, 15.0, 0.0,
2.0, 1.0, 7.0, 36.0, 22.0, 103.0, 1.0,
2.0, 1.0, 4.0, 44.0, 36.0, 2.0, 0.0,
2.0, 1.0, 3.0, 54.0, 9.0, 20.0, 0.0,
2.0, 1.0, 3.0, 59.0, 87.0, 51.0, 0.0,
3.0, 1.0, 4.0, 69.0, 5.0, 18.0, 0.0,
3.0, 1.0, 6.0, 50.0, 22.0, 90.0, 0.0,
3.0, 1.0, 8.0, 62.0, 4.0, 84.0, 0.0,
4.0, 1.0, 7.0, 68.0, 15.0, 164.0, 0.0,
4.0, 1.0, 3.0, 39.0, 4.0, 19.0, 0.0,
4.0, 1.0, 6.0, 49.0, 11.0, 43.0, 0.0,
4.0, 1.0, 8.0, 64.0, 10.0, 340.0, 0.0,
4.0, 1.0, 7.0, 67.0, 18.0, 231.0, 0.0};
int n_observations = 40;
int n_class = 2;
int n_continuous = 3;
int model = 0;
int n_coef;
int icen = 6, ilt = -1, irt = 5;
int lp_max = 40;
int n, *ncv, nrmiss, *obs;
float *iterations, *cv, criterion;
float *coef_stat, *casex;
char *fmt = "%12.4f";
char *fmt2 = "%4d%4d%6.4f%8.4f%8.1f";
static char *clabels[] = {"", "coefficient", "s.e.", "z", "p"};
static char *clabels2[] = {"", "Method", "Iteration", "Step Size",
"Coef Update", "Log-Likelihood"};
n_coef =
imsls_f_survival_glm(n_observations, n_class,
n_continuous, model, &x[0][0],
IMSLS_X_COL_CENSORING, icen, ilt, irt,
IMSLS_INFINITY_CHECK, lp_max,
IMSLS_COEF_STAT, &coef_stat,
IMSLS_ITERATIONS, &n, &iterations,
IMSLS_CASE_ANALYSIS, &casex,
IMSLS_CLASS_INFO, &ncv, &cv,
IMSLS_OBS_STATUS, &obs,
IMSLS_CRITERION, &criterion,
IMSLS_N_ROWS_MISSING, &nrmiss,
0);
imsls_f_write_matrix("Coefficient
Statistics", n_coef, 4,
coef_stat,
IMSLS_WRITE_FORMAT, fmt,
IMSLS_NO_ROW_LABELS,
IMSLS_COL_LABELS, clabels,
0);
imsls_f_write_matrix("Iteration
Information", n, 5, iterations,
IMSLS_WRITE_FORMAT, fmt2,
IMSLS_NO_ROW_LABELS,
IMSLS_COL_LABELS, clabels2, 0);
printf("\nLog-Likelihood = %12.5f\n",
criterion);
imsls_f_write_matrix("Case Analysis",
1, n_observations, casex,
IMSLS_WRITE_FORMAT, fmt,
0);
imsls_f_write_matrix(
"Distinct Values for Classification Variable 1",
1, ncv[0], &cv[0], IMSLS_NO_COL_LABELS, 0);
imsls_f_write_matrix(
"Distinct Values for Classification Variable 2",
1, ncv[1], &cv[ncv[0]], IMSLS_NO_COL_LABELS, 0);
imsls_i_write_matrix("Observation
Status", 1, n_observations,
obs, 0);
printf("\nNumber of Missing Values =
%2d\n", nrmiss);
}
Output
Coefficient Statistics
coefficient s.e. z p
-1.1027 1.3140 -0.8392 0.4016
-0.3626 0.4446 -0.8156 0.4149
0.1271 0.4863 0.2613 0.7939
0.8690 0.5861 1.4825 0.1385
0.2697 0.3882 0.6948 0.4873
-0.5400 0.1081 -4.9946 0.0000
-0.0090 0.0197 -0.4594 0.6460
-0.0034 0.0117 -0.2912 0.7710
Iteration Information
Method Iteration Step Size Coef Update Log-Likelihood
0 0 ...... ........ -224.0
0 1 1.0000 0.9839 -213.4
1 2 1.0000 3.6033 -207.3
1 3 1.0000 10.1236 -204.3
1 4 1.0000 0.1430 -204.1
1 5 1.0000 0.0117 -204.1
Log-Likelihood = -204.13916
Case Analysis
1 2 3 4 5
262.6884 0.0450 -0.5646 1.5646 0.0008
6 7 8 9 10
153.7777 0.0042 0.1806 0.8194 0.0029
11 12 13 14 15
270.5347 0.0482 0.5638 0.4362 0.0024
16 17 18 19 20
55.3168 0.0844 -0.6631 1.6631 0.0034
21 22 23 24 25
61.6845 0.3765 0.8703 0.1297 0.0142
26 27 28 29 30
230.4414 0.0025 -0.1085 0.1085 0.8972
31 32 33 34 35
232.0135 0.1960 0.9526 0.0474 0.0041
36 37 38 39 40
272.8432 0.1677 0.8021 0.1979 0.0030
Distinct Values for Classification Variable 1
1 2 3 4
Distinct Values for Classification Variable 2
0 1
Observation Status
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
Number of Missing Values = 0
Example 3
In this example, the same data and model as Example 1 are used, but max_iterations is set to zero iterations with model coefficients restricted such that μ = −1.25, β6 = −0.6, and the remaining six coefficients are equal to zero. A chi-squared statistic, with 8 degrees of freedom for testing the coefficients is specified as above (versus the alternative that it is not as specified), can be computed, based on the output, as
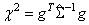
where
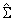
is output in cov. The resulting test statistic, Χ2 = 6.107, based upon no iterations is comparable to likelihood ratio test that can be computed from the log-likelihood output in this example (−206.6835) and the log-likelihood output in Example 2 (−204.1392).
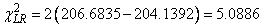
Neither statistic is significant at the α = 0.05 level.
#include <imsls.h>
main() {
static float x[40][7] = {
1.0, 0.0, 7.0, 64.0, 5.0, 411.0, 0.0,
1.0, 0.0, 6.0, 63.0, 9.0, 126.0, 0.0,
1.0, 0.0, 7.0, 65.0, 11.0, 118.0, 0.0,
1.0, 0.0, 4.0, 69.0, 10.0, 92.0, 0.0,
1.0, 0.0, 4.0, 63.0, 58.0, 8.0, 0.0,
1.0, 0.0, 7.0, 48.0, 9.0, 25.0, 1.0,
1.0, 0.0, 7.0, 48.0, 11.0, 11.0, 0.0,
2.0, 0.0, 8.0, 63.0, 4.0, 54.0, 0.0,
2.0, 0.0, 6.0, 63.0, 14.0, 153.0, 0.0,
2.0, 0.0, 3.0, 53.0, 4.0, 16.0, 0.0,
2.0, 0.0, 8.0, 43.0, 12.0, 56.0, 0.0,
2.0, 0.0, 4.0, 55.0, 2.0, 21.0, 0.0,
2.0, 0.0, 6.0, 66.0, 25.0, 287.0, 0.0,
2.0, 0.0, 4.0, 67.0, 23.0, 10.0, 0.0,
3.0, 0.0, 2.0, 61.0, 19.0, 8.0, 0.0,
3.0, 0.0, 5.0, 63.0, 4.0, 12.0, 0.0,
4.0, 0.0, 5.0, 66.0, 16.0, 177.0, 0.0,
4.0, 0.0, 4.0, 68.0, 12.0, 12.0, 0.0,
4.0, 0.0, 8.0, 41.0, 12.0, 200.0, 0.0,
4.0, 0.0, 7.0, 53.0, 8.0, 250.0, 0.0,
4.0, 0.0, 6.0, 37.0, 13.0, 100.0, 0.0,
1.0, 1.0, 9.0, 54.0, 12.0, 999.0, 0.0,
1.0, 1.0, 5.0, 52.0, 8.0, 231.0, 1.0,
1.0, 1.0, 7.0, 50.0, 7.0, 991.0, 0.0,
1.0, 1.0, 2.0, 65.0, 21.0, 1.0, 0.0,
1.0, 1.0, 8.0, 52.0, 28.0, 201.0, 0.0,
1.0, 1.0, 6.0, 70.0, 13.0, 44.0, 0.0,
1.0, 1.0, 5.0, 40.0, 13.0, 15.0, 0.0,
2.0, 1.0, 7.0, 36.0, 22.0, 103.0, 1.0,
2.0, 1.0, 4.0, 44.0, 36.0, 2.0, 0.0,
2.0, 1.0, 3.0, 54.0, 9.0, 20.0, 0.0,
2.0, 1.0, 3.0, 59.0, 87.0, 51.0, 0.0,
3.0, 1.0, 4.0, 69.0, 5.0, 18.0, 0.0,
3.0, 1.0, 6.0, 50.0, 22.0, 90.0, 0.0,
3.0, 1.0, 8.0, 62.0, 4.0, 84.0, 0.0,
4.0, 1.0, 7.0, 68.0, 15.0, 164.0, 0.0,
4.0, 1.0, 3.0, 39.0, 4.0, 19.0, 0.0,
4.0, 1.0, 6.0, 49.0, 11.0, 43.0, 0.0,
4.0, 1.0, 8.0, 64.0, 10.0, 340.0, 0.0,
4.0, 1.0, 7.0, 67.0, 18.0, 231.0, 0.0};
int n_observations = 40;
int n_class = 2;
int n_continuous = 3;
int model = 0;
int icen = 6, ilt = -1, irt = 5;
int lp_max = 40;
int n_coef_input = 8;
static float estimates[8] = {-1.25, 0.0, 0.0, 0.0,
0.0, -0.6, 0.0, 0.0};
int n_coef;
float *coef_stat, *means, *cov;
float criterion, *last_step;
char *fmt = "%12.4f";
static char *clabels[] = {"", "coefficient", "s.e.", "z", "p"};
n_coef =
imsls_f_survival_glm(n_observations, n_class,
n_continuous, model, &x[0][0],
IMSLS_X_COL_CENSORING, icen, ilt, irt,
IMSLS_INFINITY_CHECK, lp_max,
IMSLS_INITIAL_EST_INPUT, n_coef_input, estimates,
IMSLS_MAX_ITERATIONS, 0,
IMSLS_COEF_STAT, &coef_stat,
IMSLS_MEANS, &means,
IMSLS_COV, &cov,
IMSLS_CRITERION, &criterion,
IMSLS_LAST_STEP, &last_step,
0);
imsls_f_write_matrix("Coefficient
Statistics", n_coef, 4,
coef_stat,
IMSLS_WRITE_FORMAT, fmt,
IMSLS_NO_ROW_LABELS,
IMSLS_COL_LABELS, clabels,
0);
imsls_f_write_matrix("Covariate Means",
1, n_coef-1, means, 0);
imsls_f_write_matrix("Hessian", n_coef,
n_coef, cov,
IMSLS_WRITE_FORMAT, fmt,
IMSLS_PRINT_UPPER,
0);
printf("\nLog-Likelihood = %12.5f\n",
criterion);
imsls_f_write_matrix("Newton-Raphson
Step", 1, n_coef, last_step,
IMSLS_WRITE_FORMAT, fmt, 0);
}
Output
Coefficient Statistics
coefficient s.e. z p
-1.2500 1.3833 -0.9036 0.3664
0.0000 0.4288 0.0000 1.0000
0.0000 0.5299 0.0000 1.0000
0.0000 0.7748 0.0000 1.0000
0.0000 0.4051 0.0000 1.0000
-0.6000 0.1118 -5.3652 0.0000
0.0000 0.0215 0.0000 1.0000
0.0000 0.0109 0.0000 1.0000
Covariate Means
1 2 3 4 5 6
0.35 0.28 0.12 0.53 5.65 56.58
7
15.65
Hessian
1 2 3 4 5
1 1.9136 -0.0906 -0.1641 -0.1681 0.0778
2 0.1839 0.0996 0.1191 0.0358
3 0.2808 0.1264 -0.0226
4 0.6003 0.0460
5 0.1641
6 7 8
1 -0.0818 -0.0235 -0.0012
2 -0.0005 -0.0008 0.0006
3 0.0104 0.0005 -0.0021
4 0.0193 -0.0016 0.0007
5 0.0060 -0.0040 0.0017
6 0.0125 0.0000 0.0003
7 0.0005 -0.0001
8 0.0001
Log-Likelihood = -206.68349
Newton-Raphson Step
1 2 3 4 5
0.1706 -0.3365 0.1333 1.2967 0.2985
6 7 8
0.0625 -0.0112 -0.0026
Warning Errors
IMSLS_CONVERGENCE_ASSUMED_1 Too many step halvings. Convergence is assumed.
IMSLS_CONVERGENCE_ASSUMED_2 Too many step iterations. Convergence is assumed.
IMSLS_NO_PREDICTED_1 “estimates[0]” > 1.0. The expected value for the log logistic distribution (“model” = 4) does not exist. Predicted values will not be calculated.
IMSLS_NO_PREDICTED_2 “estimates[0]” > 1.0. The expected value for the log extreme value distribution(“model” = 8) does not exist. Predicted values will not be calculated.
IMSLS_NEG_EIGENVALUE The Hessian has at least one negative eigenvalue. An upper bound on the absolute value of the minimum eigenvalue is # corresponding to variable index #.
IMSLS_INVALID_FAILURE_TIME_4 “x[#][“ilt”= #]” = # and “x[#][“irt”= #]” = #. The censoring interval has length 0.0. The censoring code for this observation is being set to 0.0.
Fatal Error
IMSLS_MAX_CLASS_TOO_SMALL The number of distinct values of the classification variables exceeds “max_class” = #.
IMSLS_TOO_FEW_COEF IMSLS_INITIAL_EST_INPUT is specified, and “n_coef_input” = #. The model specified requires # coefficients.
IMSLS_TOO_FEW_VALID_OBS “n_observations” = # and “n_rows_missing” = #. “n_observations”−”n_rows_missing” must be greater than or equal to 2 in order to estimate the coefficients.
IMSLS_SVGLM_1 For the exponential model (“model” = 0) with “n_effects” = # and no intercept, “n_coef” has been determined to equal 0. With no coefficients in the model, processing cannot continue.
IMSLS_INCREASE_LP_MAX Too many observations are to be deleted from the model. Either use a different model or increase the workspace.
IMSLS_INVALID_DATA_8 “n_class_values[#]” = #. The number of distinct values for each classification variable must be greater than one.
|
Visual Numerics, Inc. PHONE: 713.784.3131 FAX:713.781.9260 |