Calculates the False Discovery Rate (FDR) q-values corresponding to a set of p-values resulting from multiple simultaneous hypothesis tests.
Synopsis
#include <imsls.h>
float *imsls_f_false_discovery_rates (int n_tests, float pvalues[],..., 0)
The type double function is imsls_d_false_discovery_rates.
Required Arguments
int n_tests
(Input)
The number of hypothesis tests.
float pvalues[]
(Input)
An array of length n_tests containing the
p-values associated with the tests.
Return Value
Pointer to an array of length n_tests containing the calculated q-values.
Synopsis with Optional Arguments
#include <imsls.h>
float
*imsls_f_false_discovery_rates (int n_tests,
float pvalues[],
IMSLS_LAMBDAS,
int
n_lamdas,
float
lambdas[]
IMSLS_GAMMA_PARAM,
float
gamma,
IMSLS_METHOD,
int
method,
IMSLS_SMOOTHING_PAR,
float
smoothing_par,
IMSLS_N_SAMPLE,
int
n_samples,
IMSLS_RANDOM_SEED,
int
random_seed,
IMSLS_CONFIDENCE,
float
confid,
IMSLS_NULL_PROB,
float
*pi0,
IMSLS_UPPER_LIMITS,
float
**upper_limits,
IMSLS_UPPER_LIMITS_USER,
float
upper_limits[],
IMSLS_RETURN_USER,
float
qvalues[],
0)
Optional Arguments
IMSLS_LAMBDAS, int n_lamdas, float
lambdas[]
(Input)
An array of length
n_lambdas
containing the grid values on [0,1) used in the estimate of the null
probability.
Default: n_lamdas = 19, lambdas = {0.0,0.05,…,0.90}.
IMSLS_GAMMA_PARAM, float gamma (Input)
Size of the rejection
region (0 ≤ gamma ≤ 1.0)
used in the calculation of the FDR and pFDR
measures.
Default: gamma = 0.05
IMSLS_METHOD, int method (Input)
Specifies the method used
to remove the dependence of the null probability estimate on the lambda variable.
method = 1
or method = 0:
when method = 0,
a bootstrap with n_samples is used;
when method = 1,
a cubic spline smoother is used.
Default: method = 0
IMSLS_SMOOTHING_PAR, float smoothing_par (Input)
Smoothing parameter (0 ≤ smoothing_par ≤ 1.0) argument for the cubic spline smoother. Only
used if method = 1.
Default:
If method = 1
and this optional argument is not provided, the smoothing parameter is selected
by cross-validation.
IMSLS_N_SAMPLE, int n_samples
(Input)
Number of bootstrap samples to make for method = 0
or when estimating upper confidence limits when IMSLS_CONFIDENCE is
present.
Default: n_samples = 100.
IMSLS_RANDOM_SEED, int random_seed
(Input)
The seed of the random number generator used in
generating the bootstrap samples. If random_seed is 0, a
value is computed using the system clock; hence, the results may be different
between different calls with the same inputs.
Default: random_seed = 0.
IMSLS_CONFIDENCE, float confid
(Input)
Confidence level (0.0 < confid < 100.0).
See IMSLS_UPPER_LIMITS.
Default:
confid = 95.0
IMSLS_NULL_PROB, float *pi0
(Output)
The null probability estimate.
IMSLS_UPPER_LIMITS, float **upper_limits
(Output)
Address of a pointer to an array of length 2 containing
the (confid)%
upper bounds for pFDR and FDR.
IMSLS_UPPER_LIMITS_USER,
float upper_limits[]
(Output)
Storage for array upper_limits is
supplied by the user. See IMSLS_UPPER_LIMITS.
IMSLS_RETURN_USER, float qvalues[]
(Output)
Storage for the return value is supplied by the
user.
Description
Let {p1, p2, …, pm}be the p-values associated with m independent tests of a statistical hypothesis. The following table summarizes the possible outcomes of the m tests. Note that the only known quantities in the table are W, R, and, m.
|
Hypothesis |
Accept |
Reject |
Total |
|
Null is true |
U |
V |
m0 |
|
Alternative is true |
T |
S |
m1 |
|
Total |
W |
R |
m |
In the above table, V is the number of false discoveries ( and the number of type I errors). Whereas the type I error rate is the probability of rejecting at least one true null hypothesis, the false discovery rate (FDR) (Benjamini and Hochberg (1995)), is the expected proportion of falsely rejected true nulls. In other words, the FDR is the expected proportion of “false positives” among the tests that are deemed significant. Using the notations from the table,
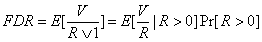
The denominator R ∨ 1 = max(R,1) avoids division by 0 in case there are no significant results (R = 0). The positive false discovery rate, or pFDR, defined in Storey (2001), is conditional on there being at least one significant test (R > 0):
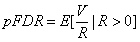
From Theorem 1 in Storey (2001),
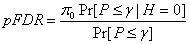
where π0 is the probability that an individual hypothesis is null, and Pr[P ≤ γ | H = 0] = γ is the probability an individual hypothesis is rejected given that it is null. The parameter γ is the pre-defined size of the rejection region. The denominator is the probability that a test is rejected, given γ. This relationship arises from Baye’s Theorem and the assumption that the p-values are independent.
An estimator for m0, the number of true null hypotheses is
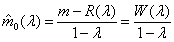
where λ is a significance level on the interval [0,1) and W(λ) is the number of tests that are accepted at level λ That is, W(λ) = #{ pi > λ}. An estimator for the probability of a null hypothesis π0 is then:
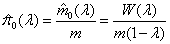
The parameter λ is a tuning parameter used to estimate the true null distribution. The rationale is that the p-values of the null hypotheses are uniformly distributed and most of the larger p-values ( >λ) will be from the null distribution. See Storey and Tibshirani ( 2003) for further details.
Now using
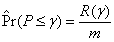
Storey (2002) gives the following estimators for pFDR and FDR: :
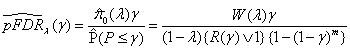
and
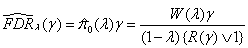
Note that 1-(1 - γ)m is a lower bound for
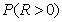 , the probability of at least one
significant test, and
, the probability of at least one
significant test, and
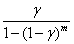
is a conservative estimate for the type I error, given that R > 0.
In imsls_f_false_discovery_rates,
the estimates above are calculated on a grid of λ values on [0,1) and the
minimizer is noted. The calculations are then repeated on B
bootstrap samples of the p-values.
The dependence on λ is removed by one of two methods. In Algorithm 3
of Storey (2002), 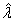 minimizes the mean squared error
between the bootstrap estimates and the original minimum of the estimates over
the grid of λ values. Then,
minimizes the mean squared error
between the bootstrap estimates and the original minimum of the estimates over
the grid of λ values. Then, 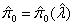 . A second method, suggested by
Storey and Tibshirani (2003), uses a cubic spline smoother
. A second method, suggested by
Storey and Tibshirani (2003), uses a cubic spline smoother 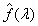 on the set of values,
on the set of values, 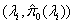 . Then the smoothed value
. Then the smoothed value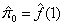 . Upper confidence bounds are
determined by taking the (1 - α)
quantile of the bootstrapped pFDR and FDR values, using
the smoothed value
. Upper confidence bounds are
determined by taking the (1 - α)
quantile of the bootstrapped pFDR and FDR values, using
the smoothed value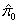 obtained by either method
above.
obtained by either method
above.
The q-value, introduced in Storey (2001), is the pFDR analogue of the p-value. For independent tests, the q-value of the observed p-value is
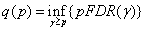
Whereas a p-value is the minimum type I error rate that can occur while rejecting a test with a given value of the test statistic, the q-value is the minimum pFDR that can occur while still rejecting the test. For more details see Storey (2001) and Storey (2002). To find the q-values, imsls_f_false_discovery_rates implements the algorithm given in Storey and Tibshirani (2003).
Examples
Example 1
The p-values are 20 independent realizations of a uniform (0,1) random variable. The null-probability estimate, q-values, and upper confidence limits are returned.
#include <imsls.h>
#include <stdio.h>
int main()
{
int i,n_tests=20,iseed=123457;
float p1[20]={
0.7897864, 0.5600287, 0.04625103, 0.4892959, 0.598915,
0.2149330, 0.9683629, 0.1449932, 0.4999971, 0.2820091,
0.3489318, 0.479333, 0.9786092, 0.02232179, 0.2329003,
0.3600357, 0.1341173, 0.5148499, 0.5693829, 0.9914673,
};
float *qvals=NULL,sort_p1[20],pi0,*upper_limits=NULL;
qvals = imsls_f_false_discovery_rates(n_tests,p1,
IMSLS_NULL_PROB, &pi0,
IMSLS_RANDOM_SEED, iseed,
IMSLS_UPPER_LIMITS,&upper_limits,
0);
for(i=0;i<n_tests;i++){
sort_p1[i]=p1[i];
}
imsls_f_sort_data(n_tests,1,sort_p1,1,0);
printf("\nNull Probability Estimate: %4.3f\n",pi0);
imsls_f_write_matrix("Upper Limits for pFDR and FDR:",
2, 1, upper_limits, 0);
printf("\n\tP-Value\t Q-Value\n");
for(i=0;i<n_tests;i++){
printf("\t %4.3f \t %4.3f\n", sort_p1[i], qvals[i]);
}
}
Output
Null Probability Estimate: 0.500
Upper Limits for pFDR and FDR:
1 1.000
2 0.869
P-Value Q-Value
0.022 0.223
0.046 0.231
0.134 0.362
0.145 0.362
0.215 0.374
0.233 0.374
0.282 0.374
0.349 0.374
0.360 0.374
0.479 0.374
0.489 0.374
0.500 0.374
0.515 0.374
0.560 0.374
0.569 0.374
0.599 0.374
0.790 0.465
0.968 0.496
0.979 0.496
0.991 0.496
Example 2
This example applies the cubic spline smoothing method to get an estimate of the null probability. Note that the p-values are the same as in Example 1, but the null probability estimate is larger in this case.
#include <imsls.h>
#include <stdio.h>
int main()
{
int i,n_tests=20,iseed=123457;
float p1[20]={
0.7897864, 0.5600287, 0.04625103, 0.4892959, 0.598915,
0.2149330, 0.9683629, 0.1449932, 0.4999971, 0.2820091,
0.3489318, 0.479333, 0.9786092, 0.02232179, 0.2329003,
0.3600357, 0.1341173, 0.5148499, 0.5693829, 0.9914673,
};
float *qvals=NULL,sorted_p1[20],pi0,upper_limits[2];
qvals = imsls_f_false_discovery_rates(n_tests,p1,
IMSLS_NULL_PROB, &pi0,
IMSLS_METHOD,1,
IMSLS_RANDOM_SEED,iseed,
IMSLS_UPPER_LIMITS_USER,upper_limits,
0);
for(i=0;i<n_tests;i++){
sorted_p1[i]=p1[i];
}
imsls_f_sort_data(n_tests,1,sorted_p1,1,0);
printf("\nNull Probability Estimate: %4.3f\n",pi0);
imsls_f_write_matrix("Upper Limits for pFDR and FDR:",
2, 1, upper_limits, 0);
printf("\n\tP-Value\t Q-Value\n");
for(i=0;i<n_tests;i++){
printf("\t %4.3f \t %4.3f\n",sorted_p1[i],qvals[i]);
}
}
Output
Null Probability Estimate: 0.870
Upper Limits for pFDR and FDR:
1 1
2 1
P-Value Q-Value
0.022 0.388
0.046 0.402
0.134 0.631
0.145 0.631
0.215 0.651
0.233 0.651
0.282 0.651
0.349 0.651
0.360 0.651
0.479 0.651
0.489 0.651
0.500 0.651
0.515 0.651
0.560 0.651
0.569 0.651
0.599 0.651
0.790 0.808
0.968 0.863
0.979 0.863
0.991 0.863
Warning Errors
IMSLS_NULL_PROBABILITY_0 The null probability estimate is < = 0. Check that the p-values are correct or try lowering the maximum “lambda” value, which is currently = #.