Usage Notes
Overview of Random Number Generation
This chapter describes functions for the generation of random numbers that are useful for applications in Monte Carlo or simulation studies. Before using any of the random number generators, the generator must be initialized by selecting a seed or starting value. The user can do this by calling the function imsls_random_seed_set. If the user does not select a seed, one is generated using the system clock. A seed needs to be selected only once in a program, unless two or more separate streams of random numbers are maintained. Other utility functions in this chapter can be used to select the form of the basic generator to restart simulations and to maintain separate simulation streams.
In the following discussions, the phrases “random numbers,” “random deviates”, “deviates”, and “variates” are used interchangeably. The phrase “pseudorandom” is sometimes used to emphasize that the numbers generated are really not “random” since they result from a deterministic process. The usefulness of pseudorandom numbers is derived from the similarity, in a statistical sense, of samples of the pseudorandom numbers to samples of observations from the specified distributions. In short, while the pseudorandom numbers are completely deterministic and repeatable, they simulate the realizations of independent and identically distributed random variables.
Basic Uniform Generators
The random number generators in this chapter use either a multiplicative congruential method or a generalized feedback shift register. The selection of the type of generator is made by calling the function imsls_random_option. If no selection is made explicitly, a multiplicative generator (with multiplier 16807) is used. Whatever distribution is being simulated, uniform (0, 1) numbers are first generated and then transformed if necessary. These functions are portable in the sense that, given the same seed and for a given type of generator, they produce the same sequence in all computer/compiler environments. There are many other issues that must be considered in developing programs for the methods described below (see Gentle 1981 and 1990).
The Multiplicative Congruential Generators
The form of the multiplicative congruential generators is
xi ≡ cxi−1mod (231 − 1)
Each xi is then scaled into the unit interval (0,1). If the multiplier, c, is a primitive root modulo 231 − 1 (which is a prime), then the generator will have a maximal period of 231 − 2. There are several other considerations, however. See Knuth (1981) for a good general discussion. The possible values for c in the generators are 16807, 397204094, and 950706376. The selection is made by the function imsls_random_option. The choice of 16807 will result in the fastest execution time, but other evidence suggests that the performance of 950706376 is best among these three choices (Fishman and Moore 1982). If no selection is made explicitly, the functions use the multiplier 16807, which has been in use for some time (Lewis et al. 1969).
The generation of uniform (0,1) numbers is done by the function imsls_f_random_uniform. This function is portable in the sense that, given the same seed, it produces the same sequence in all computer/compiler environments.
Shuffled Generators
The user also can select a shuffled version of these generators using imsls_random_option. The shuffled generators use a scheme due to Learmonth and Lewis (1973). In this scheme, a table is filled with the first 128 uniform (0,1) numbers resulting from the simple multiplicative congruential generator. Then, for each xi from the simple generator, the low-order bits of xi are used to select a random integer, j, from 1 to 128. The j-th entry in the table is then delivered as the random number; and xi, after being scaled into the unit interval, is inserted into the j-th position in the table. This scheme is similar to that of Bays and Durham (1976), and their analysis is applicable to this scheme as well.
The Generalized Feedback Shift Register Generator
The GFSR generator uses the recursion Xt = Xt−1563 ⊕ Xt−96. This generator, which is different from earlier GFSR generators, was proposed by Fushimi (1990), who discusses the theory behind the generator and reports on several empirical tests of it. Background discussions on this type of generator can be found in Kennedy and Gentle (1980), pages 150−162.
Setting the Seed
The seed of the generator can be set in imsls_random_seed_set and can be retrieved by imsls_random_seed_get. Prior to invoking any generator in this section, the user can call imsls_random_seed_set to initialize the seed, which is an integer variable with a value between 1 and 2147483647. If it is not initialized by imsls_random_seed_set, a random seed is obtained from the system clock. Once it is initialized, the seed need not be set again.
If the user wants to restart a simulation, imsls_random_seed_get can be used to obtain the final seed value of one run to be used as the starting value in a subsequent run. Also, if two simultaneous random number streams are desired in one run, imsls_random_seed_set and imsls_random_seed_get can be used before and after the invocations of the generators in each stream.
If a shuffled generator or the GFSR generator is used, in addition to resetting the seed, the user must also reset some values in a table. For the shuffled generators, this is done using the functions imsls_f_random_table_get and imsls_f_random_table_set; and for the GFSR generator; the table is retrieved and set by the functions imsls_random_GFSR_table_get and imsls_random_GFSR_table_set. The tables for the shuffled generators are separate for single and double precision; so, if precisions are mixed in a program, it is necessary to manage each precision separately for the shuffled generators.
Timing Considerations
The generation of the uniform (0,1) numbers is done by the function imsls_f_random_uniform. The particular generator selected in imsls_random_option, that is, the value of the multiplier and whether shuffling is done or whether the GFSR generator is used, affects the speed of imsls_f_random_uniform. The smaller multiplier (16807, selected by iopt = 1) is faster than the other multipliers. The multiplicative congruential generators that do not shuffle are faster than the ones that do. The GFSR generator is roughly as fast as the fastest multiplicative congruential generator, but the initialization for it (required only on the first invocation) takes longer than the generation of thousands of uniform random numbers. Precise statements of relative speeds depend on the computing system.
Distributions Other than the Uniform
The nonuniform generators use a variety of transformation procedures. All of the transformations used are exact (mathematically). The most straightforward transformation is the inverse CDF technique, but it is often less efficient than others involving acceptance/rejection and mixtures. See Kennedy and Gentle (1980) for discussion of these and other techniques.
Many of the nonuniform generators in this chapter use different algorithms depending on the values of the parameters of the distributions. This is particularly true of the generators for discrete distributions. Schmeiser (1983) gives an overview of techniques for generating deviates from discrete distributions.
Although, as noted above, the uniform generators yield the same sequences on different computers, because of rounding, the nonuniform generators that use acceptance/rejection may occasionally produce different sequences on different computer/compiler environments.
Although the generators for nonuniform distributions use fast algorithms, if a very large number of deviates from a fixed distribution are to be generated, it might be worthwhile to consider a table-sampling method, as implemented in the functions imsls_f_random_general_discrete, imsls_f_discrete_table_setup, imsls_f_random_general_continuous, and imsls_f_continuous_table_setup. After an initialization stage, which may take some time, the actual generation may proceed very fast.
Tests
Extensive empirical tests of some of the uniform random number generators available in imsls_f_random_uniform are reported by Fishman and Moore (1982 and 1986). Results of tests on the generator using the multiplier 16807 with and without shuffling are reported by Learmonth and Lewis (1973b). If the user wishes to perform additional tests, the functions in Chapter 7, “Tests of Goodness of Fit and Randomness”, may be of use. Often in Monte Carlo applications, it is appropriate to construct an ad hoc test that is sensitive to departures that are important in the given application. For example, in using Monte Carlo methods to evaluate a one-dimensional integral, autocorrselations of order one may not be harmful, but they may be disastrous in evaluating a two-dimensional integral. Although generally the functions in this chapter for generating random deviates from nonuniform distributions use exact methods, and, hence, their quality depends almost solely on the quality of the underlying uniform generator, it is often advisable to employ an ad hoc test of goodness of fit for the transformations that are to be applied to the deviates from the nonuniform generator.
Copula Generators and Canonical Correlation
A copula is a multivariate cumulative probability distribution (CDF) whose arguments are random variables uniformly distributed on the interval [0, 1] corresponding to the probabilities (variates) associated with arbitrarily distributed marginal deviates. The copula structure allows the multivariate CDF to be partitioned into the copula, which has associated with it information characterizing the dependence among the marginal variables, and the set of separate marginal deviates, each of which has its own distribution structure.
Two functions, imsls_f_random_mvar_gaussian_copula and imsls_f_random_mvar_t_copula, allow the user to specify a correlation structure (in the form of a Cholesky matrix) which can be used to imprint correlation information on a sequence of multivariate random vectors. Each call to one of these functions returns a random vector whose elements (variates) are each uniformly distributed on the interval [0, 1] and correlated according to a user-specified Cholesky matrix. These variate vector sequences may then be inverted to marginal deviate sequences whose distributions and imprinted correlations are user-specified.
Function imsls_f_random_mvar_gaussian_copula generates a random Gaussian copula vector by inverting a vector of uniform [0, 1] random numbers to an N(0, 1) deviate vector, imprinting the N(0,1) vector with the correlation information by multiplying it with the Cholesky matrix, and then using the N(0,1) CDF to map the Cholesky-imprinted deviate vector back to a vector of imprinted uniform [0, 1] variates.
Function imsls_f_random_mvar_t_copula inverts a vector of uniform [0, 1]
random numbers to an N(0, 1) deviate vector, imprints the vector with
correlation information by multiplying it with the Cholesky matrix, transforms
the imprinted N(0, 1) vector to an imprinted Student’s t vector
(where each element is Student’s t distributed with 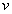 degrees of freedom) by dividing
each element of the imprinted N(0, 1) vector by
degrees of freedom) by dividing
each element of the imprinted N(0, 1) vector by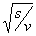 , where s is a random deviate
taken from a chi-squared distribution with degrees of freedom, and finally
maps the each element of the resulting imprinted Student’s t vector back
to a uniform [0, 1] distributed variate using the Student’s t
CDF.
, where s is a random deviate
taken from a chi-squared distribution with degrees of freedom, and finally
maps the each element of the resulting imprinted Student’s t vector back
to a uniform [0, 1] distributed variate using the Student’s t
CDF.
The third copula function, imsls_f_canonical_correlation, extracts a “canonical correlation” matrix from a sequence of multivariate deviate vectors whose component marginals are arbitrarily distributed. This is accomplished by first extracting the empirical CDF from each of the marginal deviate sequences and then using this empirical CDF to map the deviates to uniform [0, 1] variates which are then inverted to N(0, 1) deviates. Each element Ci j of the canonical correlation matrix can then be extracted by averaging the products zit zjt of N(0, 1) deviates i and j over the t-indexed sequence. The utility of function imsls_f_canonical_correlation is that because the canonical correlation matrix is derived from N(0, 1) deviates, the correlation is unbiased, i.e. undistorted by the arbitrary marginal distribution structures of the original deviate vector sequences. This is important in such financial applications as portfolio optimization, where correlation is used to estimate and minimize risk.
Additional Notes on Usage
The generators for continuous distributions are available in both single and double-precision versions. This is merely for the convenience of the user; the double-precision versions should not be considered more “accurate,” except possibly for the multivariate distributions.