RBCOV
Computes a robust estimate of a covariance matrix and mean vector.
Required Arguments
WGHTS — User-supplied SUBROUTINE to compute observation weights. The form is
CALL WGHTS (R, NVAR, PERCNT, UU, WW, UP), where
CALL WGHTS (R, NVAR, PERCNT, UU, WW, UP), where
R – Distance of observation from the mean vector at which weights are to be computed. (Input)
UU, WW, and UP are to be computed at distance R.
UU, WW, and UP are to be computed at distance R.
NVAR – Number of variables. (Input)
PERCNT – Percentage of outliers expected. (Input)
UU – Value of covariance matrix weighting function at distance R. (Output)
WW – Value of mean vector weighting function at distance R. (Output)
UP – Value of first derivative of UU with respect to R. (Output)
WGHTS must be declared EXTERNAL in the calling program. A standard weighting subroutine is provided as routine R5COV/DR5COV. See the Description section for further description of the subroutine WGHTS.
X — NOBS by NVAR + m matrix containing the data. (Input)
m is 0, 1, 2, or 3 depending upon whether any columns in X contain frequencies, weights or group numbers.
m is 0, 1, 2, or 3 depending upon whether any columns in X contain frequencies, weights or group numbers.
IND — Vector of length NVAR containing the column numbers in X for which covariances are desired. (Input)
XMEAN — NGROUP by NVAR matrix containing the estimates of the location parameters in each group. (Output, if INIT ≠ 2; input/output, otherwise)
Row i of XMEAN contains the location estimates for the variables in group i. The columns of XMEAN are in the order specified by IND.
Row i of XMEAN contains the location estimates for the variables in group i. The columns of XMEAN are in the order specified by IND.
COV — NVAR by NVAR matrix of estimated covariances. (Output, if INIT ≠ 2; input/output, otherwise)
Optional Arguments
NOBS — Number of observations. (Input)
Default: NOBS = size (X,1).
Default: NOBS = size (X,1).
NVAR — Number of variables in the covariance matrix. (Input)
Default: NVAR = size (IND,1).
Default: NVAR = size (IND,1).
NCOL — Number of columns in matrix X. (Input)
Default: NCOL = size (X,2).
Default: NCOL = size (X,2).
LDX — Leading dimension of X exactly as specified in the dimension statement in the calling program. (Input)
Default: LDX = size (X,1).
Default: LDX = size (X,1).
IFRQ — Frequency option. (Input)
IFRQ = 0 means that all frequencies are 1.0. Positive IFRQ indicates that column number IFRQ of X contains the frequencies. All frequencies should be positive integer values. The NINT (nearest integer) function is used to obtain integer frequencies from X.
Default: IFRQ = 0.
IFRQ = 0 means that all frequencies are 1.0. Positive IFRQ indicates that column number IFRQ of X contains the frequencies. All frequencies should be positive integer values. The NINT (nearest integer) function is used to obtain integer frequencies from X.
Default: IFRQ = 0.
IWT — Weighting option. (Input)
IWT = 0 means that all weights are 1.0. Positive IWT means that column IWT of X contains the positive weights. Negative weights are not allowed. Note that weights in column IWT are the proportionality constants used in computing a covariance matrix from observations with proportional covariance matrices. The weights used for robust estimation are computed in the estimation procedure.
Default: IWT = 0.
IWT = 0 means that all weights are 1.0. Positive IWT means that column IWT of X contains the positive weights. Negative weights are not allowed. Note that weights in column IWT are the proportionality constants used in computing a covariance matrix from observations with proportional covariance matrices. The weights used for robust estimation are computed in the estimation procedure.
Default: IWT = 0.
NGROUP — Number of groups (populations) in the data. (Input)
If the data comes from a single population, NGROUP = 1.
Default: NGROUP = 1.
If the data comes from a single population, NGROUP = 1.
Default: NGROUP = 1.
IGRP — Column of X giving the group numbers. (Input)
If IGRP = 0, one group is assumed. If IGRP > 0, then column number IGRP of X contains the group number for the observation. Group numbers must be
1, 2, …, NGROUP. The NINT intrinsic function is used to obtain integer group numbers
Default: IGRP = 0.
If IGRP = 0, one group is assumed. If IGRP > 0, then column number IGRP of X contains the group number for the observation. Group numbers must be
1, 2, …, NGROUP. The NINT intrinsic function is used to obtain integer group numbers
Default: IGRP = 0.
INIT — Estimate initialization option. (Input)
Default: INIT = 0.
Default: INIT = 0.
INIT | Method |
|---|---|
0 | Initial estimates are obtained as the usual estimate of a mean vector and of a covariance matrix. |
1 | Initial estimates based upon the median and interquartile range are used. |
2 | User input initial estimates are used. |
IMTH — Option parameter giving the algorithm to be used in computing the estimates. (Input)
Default: IMTH = 0.
Default: IMTH = 0.
IMTH | Method |
|---|---|
0 | Huber’s conjugate-gradient algorithm is used. |
1 | Stahel’s algorithm is used. |
PERCNT — Percentage of gross errors expected in the data. (Input)
PERCNT is in the range from zero to 100 and contains the percentage of outliers expected in the data. PERCNT is usually only used if IMSL supplied weighting subroutine R5COV/DR5COV is used as the subroutine WGHTS.
Default: PERCNT = 0.e0.
PERCNT is in the range from zero to 100 and contains the percentage of outliers expected in the data. PERCNT is usually only used if IMSL supplied weighting subroutine R5COV/DR5COV is used as the subroutine WGHTS.
Default: PERCNT = 0.e0.
MAXIT — Maximum number of iterations. (Input)
MAXIT = 30 is typical.
Default: MAXIT = 30.
MAXIT = 30 is typical.
Default: MAXIT = 30.
EPS — Convergence criterion. (Input)
When the maximum absolute change in a location or covariance estimate is less than EPS, convergence is assumed.
Default: EPS = 1.e-4.
When the maximum absolute change in a location or covariance estimate is less than EPS, convergence is assumed.
Default: EPS = 1.e-4.
NI — Vector of length NGROUP containing the number of observations in each group. (Output)
SWT — Vector of length NGROUP containing the sum of the weights times the frequencies for the observations in each group. (Output)
LDXMEA — Leading dimension of XMEAN exactly as specified in the dimension statement in the calling program. (Input)
Default: LDXMEA = size (XMEAN,1).
Default: LDXMEA = size (XMEAN,1).
LDCOV — Leading dimension of COV exactly as specified in the dimension statement of the calling program. (Input)
Default: LDCOV = size (COV,1).
Default: LDCOV = size (COV,1).
CNST — Vector of length 4 containing some constants computed by RBCOV. (Output)
CNST(1) contains the constant beta (see the Description section) used to ensure that the estimated covariance matrix has unbiased expectation (for given mean vector) for a multivariate normal density. CNST(2), CNST(3), and CNST(4) are the parameters a, b, and c, respectively, in IMSL-supplied subroutine R5COV/DR5COV. They are set to NaN (not a number) if R5COV is not used.
CNST(1) contains the constant beta (see the Description section) used to ensure that the estimated covariance matrix has unbiased expectation (for given mean vector) for a multivariate normal density. CNST(2), CNST(3), and CNST(4) are the parameters a, b, and c, respectively, in IMSL-supplied subroutine R5COV/DR5COV. They are set to NaN (not a number) if R5COV is not used.
NRMISS — Number of rows of data in X containing any missing values (NaN, not a number) in the columns IND, IWT, IFRQ, or IGRP. (Output)
Rows of X contributing to NRMISS are ignored in all other computations.
Rows of X contributing to NRMISS are ignored in all other computations.
FORTRAN 90 Interface
Generic: CALL RBCOV (WGHTS, X, IND, XMEAN, COV [, …])
Specific: The specific interface names are S_RBCOV and D_RBCOV.
FORTRAN 77 Interface
Single: CALL RBCOV (WGHTS, NOBS, NVAR, NCOL, X, LDX, IND, IFRQ, IWT, NGROUP, IGRP, INIT, IMTH, PERCNT, MAXIT, EPS, NI, SWT, XMEAN, LDXMEA, COV, LDCOV, CNST, NRMISS)
Double: The double precision name is DRBCOV.
Description
Routine RBCOV computes robust M-estimates of the mean and covariance matrix from a matrix of observations. A pooled estimate of the covariance matrix is computed when multiple groups are present in the input data. M-estimate weights are obtained from a user specified weighting subroutine. In addition, user specified observation weights and frequencies may be given for each row in X. Listwise deletion of missing values is assumed so that all observations used are “complete.” In any row of X, if any column in the list determined by IND, IFRQ, IWT, or IGRP is missing, the row is not used.
Let f(x; μi, Σ) denote the density of an observation p-vector x in population (group) i with mean vector μi, for groups i = 1, …, . Let the covariance matrix Σ be such that Σ = RTR. If
then
It is assumed that g(y) is a spherically symmetric density in p-dimensions.
In RBCOV, Σ and μi are estimated as the solutions
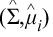
of the estimation equations
and
where i indexes the groups, ni is the number of observations in group i, fij is the frequency for the j-th observation in group i, ωij is the observation weight specified in column IWT of X, Ip is a
p × p identity matrix,
p × p identity matrix,
w(r) and u(r) are weighting functions specified by the user through subroutine WGHTS, and where β is a constant computed by the program to make the expected weighted Mahalanobis distance (yTy) equal the expected Mahalanobis distance from a multivariate normal distribution (see Marazzi 1985). The constant β is described more fully below.
Routine RBCOV uses one of two algorithms for solving the estimation equations. The first algorithm is discussed in detail in Huber (1981) and is a variant of the conjugate gradient method. The second algorithm is due to Stahel (1981) and is discussed in detail by Marazzi (1985). In both algorithms, correction vectors Tki for the group i means and correction matrix Wk = Ip + Uk for the Cholesky factorization of Σ are found such that the updated mean vectors are given by
and the updated matrix R is given
where k is the iteration number and
When all elements of Uk and Tki are less that ɛ = EPS, convergence is assumed.
Three methods for obtaining initial estimates are allowed. In the first method, the sample weighted estimate of Σ is computed (using routine COVPL). In the second method, estimates based upon the median and the interquartile range are used. Finally, in the last method, the user inputs initial estimates.
Routine RBCOV computes estimates for any weighting functions u and w. The constant β is chosen such that E(u(r)r2) = pβ where the expectation is with respect to a standard p-variate multivariate normal distribution. This yields estimates with the correct expectation for the multivariate normal distribution (for given mean vector). The expectation is computed via integration of estimated spline functions. 200 knots are used on an equally spaced grid from 0.0 to the 99.999 percentile of a
distribution. An error estimate is computed based upon 100 of these knots. If the estimated relative error is greater than 0.001, a warning message is issued. If β is not computed accurately (i.e., if the warning message is issued), the computed estimates are still optimal, but the scale of the estimated covariance matrix may need to be multiplied by a constant in order for
to have the correct multivariate normal covariance expectation.
The Weighting Subroutine
The name of the weighting subroutine (WGHTS) is input into RBCOV. User-supplied weights may be used. Alternatively, the user may input the name of the IMSL-supplied subroutine, S_R5COV in single precision, or D_R5COV in double precision. The weights computed by this subroutine are the “minimax” weights of Huber (1981, pages 231 ‑ 235), with PERCNT expected gross errors. Huber’s (1981) weighting equations are given by:
The constants a, b, and c depend upon the number of variables p and upon the expected percentage of gross errors. They are computed by R5COV as the zeroes of equations given by Huber and are returned in the array CNST from RBCOV.
Comments
1. Workspace may be explicitly provided, if desired, by use of R2COV/DR2COV. The reference is:
CALL R2COV (WGHTS, NOBS, NVAR, NCOL, X, LDX, IND, IFRQ, IWT, NGROUP, IGRP, INIT, IMTH, PERCNT, MAXIT, EPS, NI, SWT, XMEAN, LDXMEA, COV, LDCOV, CNST, NRMISS, D, U, GXB, OB, OB1, OB2, SWW, WK, IRN, ISF)
The additional arguments are as follows:
D — Work vector of length NVAR.
U — Work vector of length max(m * NVAR, NGROUP) * NVAR; where m = 2 if IMTH = 0, and m = 1 otherwise.
GXB — Work vector of length NVAR * NGROUP.
OB — Work vector of length NVAR.
OB1 — Work vector of length NVAR.
OB2 — Work vector of length NVAR.
SWW — Work vector of length NGROUP.
WK — Work vector of length NOBS.
IRN — Work vector of length NOBS.
ISF — Work vector of length NGROUP.
2. Informational errors
Type | Code | Description |
|---|---|---|
4 | 1 | The derivative of UU with respect R is not correctly specified. |
Example
The following example computes estimates of the mean vectors and the pooled covariance matrix for the Fisher iris data (routine GDATA provides these data with the group indicator in the first column.). For comparison, these estimates are first computed via routine COVPL. Routine RBCOV with PERCNT = 0.02 is then used to compute the robust estimates. As can be seen from the output, the resulting estimates are quite similar.
To study the behavior of RBCOV, three observations are made into outliers, and, again, both COVPL and RBCOV are used to compute estimates. When outliers are present, COVPL gives estimates that have clearly been adversely affected, while the estimates produced by RBCOV are close to the estimates produced when no outliers are present.
In both calls to RBCOV, the usual pooled estimates were used for the initial estimates, and IMSL supplied routine R5COV with argument PERCNT = 0.02 was used. Because neither NOBS or PERCNT changed in the two calls, the values returned in CNST are identical. If the percentage of gross errors expected in the data, PERCNT, is not known, a reasonable strategy is to use a value of PERCNT that is such that larger values do not result in significant changes in the estimates.
USE IMSL_LIBRARIES
IMPLICIT NONE
INTEGER IGRP, LDCOV, LDX, LDXMEA, MAXIT, NCOL, NGROUP, NOBS, &
NV, NVAR
REAL PERCNT
PARAMETER (IGRP=1, NCOL=5, NGROUP=3, NOBS=150, NV=5, NVAR=4, &
PERCNT=2.0, LDCOV=NVAR, LDX=NOBS, LDXMEA=NGROUP)
!
INTEGER IND(NVAR), NI(NGROUP), NOB1, NOUT, NRMISS, NV1
REAL CNST(4), COV(LDCOV,NVAR), SWT(NGROUP), X(LDX,NCOL), &
XMEAN(NGROUP,NVAR)
EXTERNAL S_R5COV
!
DATA IND/2, 3, 4, 5/
!
CALL GDATA (3, X, NOB1, NV1)
!
CALL COVPL (NOBS, NVAR, X, NGROUP, COV, IND=IND, IGRP=IGRP, &
XMEAN=XMEAN)
!
CALL UMACH (2, NOUT)
WRITE (NOUT,*) 'COVPL estimates with no outliers'
CALL WRRRN ('XMEAN', XMEAN)
CALL WRRRN ('COV', COV, ITRING=1)
!
CALL RBCOV (S_R5COV, X, IND, XMEAN, COV, NGROUP=NGROUP, &
IGRP=IGRP, PERCNT=PERCNT, NI=NI, SWT=SWT, CNST=CNST)
!
WRITE (NOUT,*) 'RBCOV estimates with no outliers'
CALL WRRRN ('XMEAN', XMEAN)
CALL WRRRN ('COV', COV, ITRING=1)
CALL WRRRN ('SWT', SWT, 1, NGROUP, 1)
CALL WRIRN ('NI', NI, 1, NGROUP, 1)
CALL WRRRN ('CNST', CNST, 1, 4, 1)
!
X(1,2) = 100.0
X(5,5) = 100.0
X(100,3) = -100.0
!
CALL COVPL (NOBS, NVAR, X, NGROUP, COV, IND=IND, IGRP=IGRP, &
XMEAN=XMEAN)
!
CALL UMACH (2, NOUT)
WRITE (NOUT,*) 'COVPL estimates with three outliers'
CALL WRRRN ('XMEAN', XMEAN)
CALL WRRRN ('COV', COV, ITRING=1)
!
CALL RBCOV (S_R5COV, X, IND, XMEAN, COV, NGROUP=NGROUP, IGRP=IGRP, &
PERCNT=PERCNT, NI=NI, SWT=SWT, CNST=CNST)
!
WRITE (NOUT,*) 'RBCOV estimates with three outliers'
CALL WRRRN ('XMEAN', XMEAN)
CALL WRRRN ('COV', COV, ITRING=1)
CALL WRRRN ('SWT', SWT, 1, NGROUP, 1)
CALL WRIRN ('NI', NI, 1, NGROUP, 1)
CALL WRRRN ('CNST', CNST, 1, 4,1)
!
END
Output
COVPL estimates with no outliers
XMEAN
1 2 3 4
1 5.006 3.428 1.462 0.246
2 5.936 2.770 4.260 1.326
3 6.588 2.974 5.552 2.026
COV
1 2 3 4
1 0.2650 0.0927 0.1675 0.0384
2 0.1154 0.0552 0.0327
3 0.1852 0.0427
4 0.0419
RBCOV estimates with no outliers
XMEAN
1 2 3 4
1 4.989 3.411 1.465 0.244
2 5.951 2.784 4.265 1.324
3 6.529 2.970 5.489 2.026
COV
1 2 3 4
1 0.2474 0.0872 0.1535 0.0360
2 0.1073 0.0538 0.0322
3 0.1705 0.0412
4 0.0401
SWT
1 2 3
50.00 50.00 50.00
NI
1 2 3
50 50 50
CNST
1 2 3 4
0.972 0.000 3.093 1.717
COVPL estimates with three outliers
XMEAN
1 2 3 4
1 6.904 3.428 1.462 2.242
2 5.936 0.714 4.260 1.326
3 6.588 2.974 5.552 2.026
COV
1 2 3 4
1 60.43 0.30 0.13 -1.28
2 70.53 0.17 0.17
3 0.19 0.00
4 66.38
RBCOV estimates with three outliers
XMEAN
1 2 3 4
1 4.999 3.405 1.468 0.253
2 5.959 2.772 4.271 1.324
3 6.528 2.970 5.489 2.026
COV
1 2 3 4
1 0.2567 0.0885 0.1553 0.0361
2 0.1133 0.0546 0.0324
3 0.1723 0.0412
4 0.0424
SWT
1 2 3
50.00 50.00 50.00
NI
1 2 3
50 50 50
CNST
1 2 3 4
0.972 0.000 3.093 1.717
Published date: 03/19/2020
Last modified date: 03/19/2020




