
For a detailed description of MPI Requirements see “Dense Matrix Parallelism Using MPI” in Chapter 10 of this manual.
Solves a linear, non-negative constrained least-squares system.
Usage Notes
CALL PARALLEL_NONNEGATIVE_LSQ&
(A, B, X, RNORM, W, INDEX, IPART, IOPT = IOPT)
Required Arguments
A(1:M,:)— (Input/Output) Columns of the
matrix with limits given by entries in the array IPART(1:2,1:max(1,MP_NPROCS)).
On output 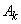 is
replaced by the product
is
replaced by the product 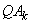 , where
, where 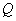 is an orthogonal matrix. The value SIZE(A,1) defines the
value of M. Each
processor starts and exits with its piece of the partitioned matrix.
is an orthogonal matrix. The value SIZE(A,1) defines the
value of M. Each
processor starts and exits with its piece of the partitioned matrix.
B(1:M) — (Input/Output) Assumed-size
array of length M containing the
right-hand side vector, 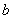 . On output is replaced by the product
. On output is replaced by the product 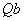 , where is the orthogonal matrix applied
to
, where is the orthogonal matrix applied
to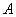 . All
processors in the communicator start and exit with the same vector.
. All
processors in the communicator start and exit with the same vector.
X(1:N) — (Output) Assumed-size array of
length N containing the
solution, 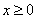 . The
value SIZE(X) defines the
value of N. All
processors exit with the same vector.
. The
value SIZE(X) defines the
value of N. All
processors exit with the same vector.
RNORM — (Output) Scalar that contains the
Euclidean or least-squares length of the residual vector, 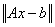 . All processors exit with
the same value.
. All processors exit with
the same value.
W(1:N) — (Output) Assumed-size array of
length N containing the dual
vector, 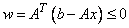 . All
processors exit with the same vector.
. All
processors exit with the same vector.
INDEX(1:N) — (Output) Assumed-size array
of length N containing the NSETP indices of
columns in the positive solution, and the remainder that are at their
constraint. The number of positive components in the
solution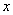 is give by the
Fortran intrinsic function value,
is give by the
Fortran intrinsic function value,
NSETP=COUNT(X >
0). All processors exit with the same array.
IPART(1:2,1:max(1,MP_NPROCS)) — (Input)
Assumed-size array containing the partitioning describing the matrix. The value MP_NPROCS is the
number of processors in the communicator,
except when MPI has been finalized
with a call to the routine MP_SETUP(‘Final').
This causes MP_NPROCS to be
assigned 0. Normally users will give the partitioning to processor of rank
= MP_RANK by setting IPART(1,MP_RANK+1)=
first column index, and IPART(2,MP_RANK+1)=
last column index. The number of columns per node is
typically based on their relative computing power. To avoid a node with
rank MP_RANK doing any work
except communication, set IPART(1,MP_RANK+1) = 0
and IPART(2,MP_RANK+1)=
-1. In this exceptional case there is no reference to the array
A(:,:) at that node.
Optional Argument
IOPT(:)— (Input) Assumed-size array of derived type S_OPTIONS or D_OPTIONS. This argument is used to change internal parameters of the algorithm. Normally users will not be concerned about this argument, so they would not include it in the argument list for the routine.
IOPT(IO)=?_OPTIONS(PNLSQ_SET_TOLERANCE, TOLERANCE) Replaces the default rank tolerance for using a column, from EPSILON(TOLERANCE) to TOLERANCE. Increasing the value of TOLERANCE will cause fewer columns to be moved from their constraints, and may cause the minimum residual RNORM to increase.
IOPT(IO)=?_OPTIONS(PNLSQ_SET_MIN_RESIDUAL, RESID) Replaces the default target for the minimum residual vector length from 0 to RESID. Increasing the value of RESID can result in fewer iterations and thus increased efficiency. The descent in the optimization will stop at the first point where the minimum residual RNORM is smaller than RESID. Using this option may result in the dual vector not satisfying its optimality conditions, as noted above.
IOPT(IO)= PNLSQ_SET_MAX_ITERATIONS
IOPT(IO+1)= NEW_MAX_ITERATIONS Replaces the default maximum number of iterations from 3*N to NEW_MAX_ITERATIONS. Note that this option requires two entries in the derived type array.
FORTRAN 90 Interface
Generic:
CALL
PARALLEL_NONNEGATIVE_LSQ (A, B, X, RNORM, W, INDEX,
IPART [,…])
Specific: The specific interface names are S_PARALLEL_NONNEGATIVE_LSQ and D_PARALLEL_NONNEGATIVE_LSQ.
Description
Subroutine PARALLEL_NONNEGATIVE_LSQ
solves the linear least-squares system 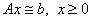 , using the algorithm NNLS
found in Lawson and Hanson, (1995), pages 160-161. The code now updates
the dual vector
, using the algorithm NNLS
found in Lawson and Hanson, (1995), pages 160-161. The code now updates
the dual vector 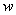 of Step 2, page 161. The remaining new steps
involve exchange of required data, using MPI.
of Step 2, page 161. The remaining new steps
involve exchange of required data, using MPI.
Example 1: Distributed Linear Inequality Constraint Solver
The program PNLSQ_EX1 illustrates the computation of the minimum
Euclidean length solution of an 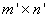 system of linear inequality constraints ,
system of linear inequality constraints , 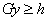 . The solution algorithm is
based on Algorithm LDP, page 165-166, loc. cit. The rows of
. The solution algorithm is
based on Algorithm LDP, page 165-166, loc. cit. The rows of
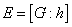 are partitioned and
assigned random values. When the minimum Euclidean length solution to the
inequalities has been calculated, the residuals
are partitioned and
assigned random values. When the minimum Euclidean length solution to the
inequalities has been calculated, the residuals 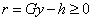 are computed, with the dual
variables to the NNLS problem indicating the entries of
are computed, with the dual
variables to the NNLS problem indicating the entries of
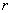 that are
precisely zero.
that are
precisely zero.
The fact that matrix products involving both 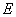 and
and 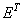 are needed to compute the
constrained solution
are needed to compute the
constrained solution 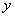 and the residuals , implies that message passing is required. This occurs
after the NNLS solution is computed.
and the residuals , implies that message passing is required. This occurs
after the NNLS solution is computed.
! Use Parallel_nonnegative_LSQ to solve an inequality
! constraint problem, Gy >= h. This algorithm uses
! Algorithm LDP of Solving Least Squares Problems,
! page 165. The constraints are allocated to the
! processors, by rows, in columns of the array A(:,:).
INTEGER, PARAMETER :: MP=500, NP=400, M=NP+1, N=MP
REAL(KIND(1D0)), PARAMETER :: ZERO=0D0, ONE=1D0
REAL(KIND(1D0)), ALLOCATABLE :: &
A(:,:), B(:), X(:), Y(:), W(:), ASAVE(:,:)
INTEGER, ALLOCATABLE :: INDEX(:), IPART(:,:)
INTEGER K, L, DN, J, JSHIFT, IERROR
DN=N/max(1,max(1,MP_NPROCS))-1
ALLOCATE(IPART(2,max(1,MP_NPROCS)))
! Spread constraint rows evenly to the processors.
! Define the constraint data using random values.
K=max(0,IPART(2,MP_RANK+1)-IPART(1,MP_RANK+1)+1)
ALLOCATE(A(M,K), ASAVE(M,K), X(N), W(N), &
! The use of ASAVE can be removed by regenerating
! the data for A(:,:) after the return from
IF(MP_RANK == 0 .and. PRINT) &
"Partition of the constraints to be solved")
! Set the right-hand side to be one in the last component, zero elsewhere.
CALL Parallel_nonnegative_LSQ &
(A, B, X, RNORM, W, INDEX, IPART)
! Each processor multiplies its block times the part of
! the dual corresponding to that part of the partition.
DO J=IPART(1,MP_RANK+1),IPART(2,MP_RANK+1)
! Accumulate the pieces from all the processors. Put sum into B(:)
CALL MPI_REDUCE(Y, B, M, MPI_DOUBLE_PRECISION,&
MPI_SUM, 0, MP_LIBRARY_WORLD, IERROR)
! Compute constrained solution at the root.
! The constraints will have no solution if B(M) = ONE.
! All of these example problems have solutions.
! Send the inequality constraint solution to all nodes.
CALL MPI_BCAST(B, M, MPI_DOUBLE_PRECISION, &
! For large problems this printing needs to be removed.
IF(MP_RANK == 0 .and. PRINT) &
"Minimal length solution of the constraints")
! Compute residuals of the individual constraints.
! If only the solution is desired, the program ends here.
DO J=IPART(1,MP_RANK+1),IPART(2,MP_RANK+1)
X(J)=dot_product(B,ASAVE(:,JSHIFT))
! This cleans up residuals that are about rounding
! error unit (times) the size of the constraint
! equation and right-hand side. They are replaced
! Each group of residuals is disjoint, per processor.
! We add all the pieces together for the total set of
CALL MPI_REDUCE(X, W, N, MPI_DOUBLE_PRECISION,&
MPI_SUM, 0, MP_LIBRARY_WORLD, IERROR)
IF(MP_RANK == 0 .and. PRINT) &
CALL SHOW(W, "Residuals for the constraints")
! See to any errors and shut down MPI.
IF(COUNT(W < ZERO) == 0) WRITE(*,*)&
" Example 1 for PARALLEL_NONNEGATIVE_LSQ is correct."
Output
Example 1 for PARALLEL_NONNEGATIVE_LSQ is correct.
Additional Examples
Example 2: Distributed Non-negative Least-Squares
The program PNLSQ_EX2 illustrates the computation of the solution to a
system of linear least-squares equations with simple constraints: 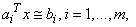 subject to . In this example we write
the row vectors
subject to . In this example we write
the row vectors 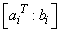 on a file. This illustrates reading the data by rows
and arranging the data by columns, as required by PARALLEL_NONNEGATIVE_LSQ.
After reading the data, the right-hand side vector is broadcast to the group
before computing a solution,. The block-size is chosen so that each participating
processor receives the same number of columns, except any remaining columns sent
to the processor with largest rank. This processor contains the right-hand
side before the broadcast.
on a file. This illustrates reading the data by rows
and arranging the data by columns, as required by PARALLEL_NONNEGATIVE_LSQ.
After reading the data, the right-hand side vector is broadcast to the group
before computing a solution,. The block-size is chosen so that each participating
processor receives the same number of columns, except any remaining columns sent
to the processor with largest rank. This processor contains the right-hand
side before the broadcast.
This example illustrates connecting a BLACS ‘context' handle and the Fortran Library MPI communicator, MP_LIBRARY_WORLD, described in Chapter 10.
! Use Parallel_Nonnegative_LSQ to solve a least-squares
! problem, A x = b, with x >= 0. This algorithm uses a
! distributed version of NNLS, found in the book
! Solving Least Squares Problems, page 165. The data is
! read from a file, by rows, and sent to the processors,
INTEGER, PARAMETER :: M=128, N=32, NP=N+1, NIN=10
real(kind(1d0)), ALLOCATABLE, DIMENSION(:) :: &
d_A(:,:), A(:,:), B, C, W, X, Y
INTEGER, ALLOCATABLE :: INDEX(:), IPART(:,:)
INTEGER I, J, K, L, DN, JSHIFT, IERROR, &
CONTXT, NPROW, MYROW, MYCOL, DESC_A(9)
! Routines with the "BLACS_" prefix are from the
CALL BLACS_PINFO(MP_RANK, MP_NPROCS)
! Make initialization for BLACS.
! Define processor grid to be 1 by MP_NPROCS.
CALL BLACS_GRIDINIT(CONTXT, 'N/A', NPROW, MP_NPROCS)
! Get this processor's role in the process grid.
CALL BLACS_GRIDINFO(CONTXT, NPROW, MP_NPROCS, &
! Connect BLACS context with communicator MP_LIBRARY_WORLD.
CALL BLACS_GET(CONTXT, 10, MP_LIBRARY_WORLD)
! Spread columns evenly to the processors. Any odd
! number of columns are in the processor with highest
! Note which processor (L-1) receives the right-hand side.
IF(IPART(1,L) <= NP .and. NP <= IPART(2,L)) EXIT
K=max(0,IPART(2,MP_RANK+1)-IPART(1,MP_RANK+1)+1)
ALLOCATE(d_A(M,K), W(N), X(N), Y(N),&
! Define the matrix data using random values.
! Write the rows of data to an external file.
OPEN(UNIT=NIN, FILE='Atest.dat', STATUS='UNKNOWN')
WRITE(NIN,*) (A(I,J),J=1,N), B(I)
! No resources are used where this array is not saved.
! Define the matrix descriptor. This includes the
! right-hand side as an additional column. The row
! block size, on each processor, is arbitrary, but is
! chosen here to match the column block size.
DESC_A=(/1, CONTXT, M, NP, DN+1, DN+1, 0, 0, M/)
IOPT(1)=ScaLAPACK_READ_BY_ROWS
CALL ScaLAPACK_READ ("Atest.dat", DESC_A, &
! Broadcast the right-hand side to all processors.
CALL MPI_BCAST(B, M, MPI_DOUBLE_PRECISION , L-1, &
! Adjust the partition of columns to ignore the
! last column, which is the right-hand side. It is
! Solve the constrained distributed problem.
CALL Parallel_Nonnegative_LSQ &
(d_A, B, X, RNORM, W, INDEX, IPART)
! Solve the problem on one processor, with data saved
IPART(2,:)=0; IPART(2,1)=N; MP_NPROCS=1
! Since all processors execute this code, all arrays
! must be allocated in the main program.
CALL Parallel_Nonnegative_LSQ &
(A, C, Y, RNORM, W, INDEX, IPART)
! Check the differences in the two solutions. Unique solutions
! may differ in the last bits, due to rounding.
IF(ERROR <= sqrt(EPSILON(ERROR))) write(*,*) &
' Example 2 for PARALLEL_NONNEGATIVE_LSQ is correct.'
OPEN(UNIT=NIN, FILE='Atest.dat', STATUS='OLD')
! Exit from using this process grid.
Output
Example 2 for PARALLEL_NONNEGATIVE_LSQ is correct.'
|
Visual Numerics, Inc. PHONE: 713.784.3131 FAX:713.781.9260 |