support_vector_trainer
Trains a Support Vector Machines (SVM) classifier.
Synopsis
#include <imsls.h>
Imsls_f_svm_model *imsls_f_support_vector_trainer (int n_patterns, int n_classes, int n_attributes, float classification[], float x[], ..., 0)
The type double function is imsls_d_support_vector_trainer.
Required Arguments
int n_patterns (Input)
Number of training patterns.
Number of training patterns.
int n_classes (Input)
Number of unique target classification values.
Number of unique target classification values.
int n_attributes (Input)
Number of attributes.
Number of attributes.
float classification[] (Input)
Array of length n_patterns containing the target classification values for each of the training patterns.
Array of length n_patterns containing the target classification values for each of the training patterns.
float x[] (Input)
Array of length n_patterns by n_attributes containing the training data matrix.
Array of length n_patterns by n_attributes containing the training data matrix.
Return Value
A pointer to a structure of type Imsls_f_svm_model containing the trained support vector classifier model. If training is unsuccessful, NULL is returned. To release this space, use imsls_f_svm_classifier_free.
Synopsis with Optional Arguments
#include <imsls.h>
Imsls_f_svm_model *imsls_f_support_vector_trainer (int n_patterns, int n_classes, int n_attributes, float classification[], float x[],
IMSLS_SVM_C_SVC_TYPE, float C, int nr_weight, float weight_class[], float weight[], or
IMSLS_SVM_NU_SVC_TYPE, float nu, or
IMSLS_SVM_ONE_CLASS_TYPE, float nu, or
IMSLS_SVM_EPSILON_SVR_TYPE, float C, float p, or
IMSLS_SVM_NU_SVR_TYPE, float C, float nu,
IMSLS_SVM_WORK_ARRAY_SIZE, float work_size,
IMSLS_SVM_EPSILON, float epsilon,
IMSLS_SVM_NO_SHRINKING,
IMSLS_SVM_TRAIN_ESTIMATE_PROB,
IMSLS_SVM_KERNEL_LINEAR, or
IMSLS_SVM_KERNEL_POLYNOMIAL, int degree, float gamma, float coef0, or
IMSLS_SVM_KERNEL_RADIAL_BASIS, float gamma, or
IMSLS_SVM_KERNEL_SIGMOID, float gamma, float coef0, or
IMSLS_SVM_KERNEL_PRECOMPUTED, float kernel_values[],
IMSLS_SVM_CROSS_VALIDATION, int n_folds, float **target, float *result
IMSLS_SVM_CROSS_VALIDATION_USER, int n_folds, float target[], float *result,
0)
Optional Arguments
IMSLS_SVM_C_SVC_TYPE, float C, int nr_weight, float weight_class[], float weight[] (Input)
Specifies that the C-support vector classification (C-SVC) algorithm is to be used to create the classification model. This is the default type of SVM used.
Specifies that the C-support vector classification (C-SVC) algorithm is to be used to create the classification model. This is the default type of SVM used.
float C (Input)
The regularization parameter. C must be greater than 0. By default, the penalty parameters are set to the regularization parameter C. The penalty parameters can be changed by scaling C by the values specified in weight below.
The regularization parameter. C must be greater than 0. By default, the penalty parameters are set to the regularization parameter C. The penalty parameters can be changed by scaling C by the values specified in weight below.
int nr_weight (Input)
The number of elements in weight and weight_class used to change the penalty parameters.
The number of elements in weight and weight_class used to change the penalty parameters.
float weight_class[] (Input)
An array of length nr_weight containing the target classification values that are to be weighted.
An array of length nr_weight containing the target classification values that are to be weighted.
float weight[] (Input)
An array of length nr_weight containing the weights corresponding to the target classification values in weight_class to be used to change the penalty parameters.
An array of length nr_weight containing the weights corresponding to the target classification values in weight_class to be used to change the penalty parameters.
Default: C-SVC is the default SVM type used with C = 5.0, nr_weight = 0, weight_class = NULL, and weight = NULL.
or
IMSLS_SVM_NU_SVC_TYPE, float nu (Input)
Specifies that the ν-support vector classification (ν-SVC) algorithm is to be used to create the classification model.
Specifies that the ν-support vector classification (ν-SVC) algorithm is to be used to create the classification model.
float nu (Input)
The parameter nu controls the number of support vectors and nu ∈ (0,1].
The parameter nu controls the number of support vectors and nu ∈ (0,1].
or
IMSLS_SVM_ONE_CLASS_TYPE, float nu (Input)
Specifies that the distribution estimation (one-class SVM) algorithm is to be used to create the classification model.
Specifies that the distribution estimation (one-class SVM) algorithm is to be used to create the classification model.
float nu (Input)
The parameter nu controls the number of support vectors and nu ∈ (0,1].
The parameter nu controls the number of support vectors and nu ∈ (0,1].
or
IMSLS_SVM_EPSILON_SVR_TYPE, float C, float p (Input)
Specifies that the ɛ-support vector regression (ɛ-SVM) algorithm is to be used to create the classification model.
Specifies that the ɛ-support vector regression (ɛ-SVM) algorithm is to be used to create the classification model.
float C (Input)
The regularization parameter. C must be greater than 0.
The regularization parameter. C must be greater than 0.
float p (Input)
The insensitivity band parameter p must be positive.
The insensitivity band parameter p must be positive.
or
IMSLS_SVM_NU_SVR_TYPE, float C, float nu (Input)
Specifies that the ν-support vector regression (ν-SVR) algorithm is to be used to create the classification model.
Specifies that the ν-support vector regression (ν-SVR) algorithm is to be used to create the classification model.
float C (Input)
The regularization parameter. C must be greater than 0.
The regularization parameter. C must be greater than 0.
float nu (Input)
The parameter nu controls the number of support vectors and nu ∈ (0,1].
The parameter nu controls the number of support vectors and nu ∈ (0,1].
IMSLS_SVM_WORK_ARRAY_SIZE, float work_size (Input)
This work array size argument sets the number of megabytes allocated for the work array used during the decomposition method. A larger work array size can reduce the computational time of the decomposition method.
Default: work_size = 1.0.
This work array size argument sets the number of megabytes allocated for the work array used during the decomposition method. A larger work array size can reduce the computational time of the decomposition method.
Default: work_size = 1.0.
IMSLS_SVM_EPSILON, float epsilon (Input)
The absolute accuracy tolerance for termination criterion. The algorithm uses the SMO algorithm in solving the optimization problem. When the Lagrange multipliers used in the SMO algorithm satisfy the Karush-Kuhn-Tucker (KKT) conditions within epsilon, convergence is assumed.
Default: epsilon = 0.001.
The absolute accuracy tolerance for termination criterion. The algorithm uses the SMO algorithm in solving the optimization problem. When the Lagrange multipliers used in the SMO algorithm satisfy the Karush-Kuhn-Tucker (KKT) conditions within epsilon, convergence is assumed.
Default: epsilon = 0.001.
IMSLS_SVM_NO_SHRINKING, (Input)
Use of this argument specifies that the shrinking technique is not to be used in the SMO algorithm. The shrinking technique tries to identify and remove some bounded elements during the application of the SMO algorithm, so a smaller optimization problem is solved.
Default: Shrinking is performed.
Use of this argument specifies that the shrinking technique is not to be used in the SMO algorithm. The shrinking technique tries to identify and remove some bounded elements during the application of the SMO algorithm, so a smaller optimization problem is solved.
Default: Shrinking is performed.
IMSLS_SVM_TRAIN_ESTIMATE_PROB, (Input)
Instructs the trainer to include information in the resultant classifier model to enable you to obtain probability estimates when invoking imsls_f_support_vector_classification.
Default: Information necessary to obtain probability estimates is not included in the model.
Instructs the trainer to include information in the resultant classifier model to enable you to obtain probability estimates when invoking imsls_f_support_vector_classification.
Default: Information necessary to obtain probability estimates is not included in the model.
IMSLS_SVM_KERNEL_LINEAR, (Input)
This argument specifies that the inner-product kernel type
This argument specifies that the inner-product kernel type
K(xi , xj) = xiTxj
is to be used. This kernel type is best used when the relation between the target classification values and attributes is linear or when the number of attributes is large (for example, 1000 attributes).
or
IMSLS_SVM_KERNEL_POLYNOMIAL, int degree, float gamma, float coef0 (Input)
This argument specifies that the polynomial kernel type
This argument specifies that the polynomial kernel type
K(xi , xj) = (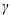 xiTxj + r)d
xiTxj + r)d
xiTxj + r)dis to be used. Use this argument when the data are not linearly separable.
int degree (Input)
Parameter degree specifies the order of the polynomial kernel. degree = d in the equation above.
Parameter degree specifies the order of the polynomial kernel. degree = d in the equation above.
float gamma (Input)
Parameter gamma must be greater than 0. gamma =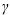 in the equation above.
in the equation above.
Parameter gamma must be greater than 0. gamma =
in the equation above.float coef0 (Input)
Parameter coef0 corresponds to r in the equation above.
Parameter coef0 corresponds to r in the equation above.
or
IMSLS_SVM_KERNEL_RADIAL_BASIS, float gamma (Input)
This argument specifies that the radial basis function kernel type
This argument specifies that the radial basis function kernel type
K(xi , xj) = exp (-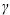 ∥xi - xj∥2)
∥xi - xj∥2)
∥xi - xj∥2)is to be used. Use this kernel type when the relation between the class labels and attributes is nonlinear, although it can also be used when the relation between the target classification values and attributes is linear. This kernel type exhibits fewer numerical difficulties. If no kernel type is specified, this is the kernel type used.
float gamma (Input)
Parameter gamma must be greater than 0. gamma =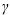 in the equation above.
in the equation above.
Parameter gamma must be greater than 0. gamma =
in the equation above.or
IMSLS_SVM_KERNEL_SIGMOID, float gamma, float coef0 (Input)
This argument specifies that the sigmoid kernel type
This argument specifies that the sigmoid kernel type
K(xi , xj) = tanh(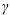 xiTxj + r)
xiTxj + r)
xiTxj + r)is to be used.
float gamma (Input)
Parameter gamma =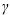 in the equation above.
in the equation above.
Parameter gamma =
in the equation above.float coef0 (Input)
Parameter coef0 corresponds to r in the equation above.
Parameter coef0 corresponds to r in the equation above.
or
IMSLS_SVM_KERNEL_PRECOMPUTED, float kernel_values[] (Input)
Use of this argument indicates that the kernel function values have been precomputed for the training and testing data sets. If IMSLS_SVM_KERNEL_PRECOMPUTED is used, the required argument x is ignored.
Use of this argument indicates that the kernel function values have been precomputed for the training and testing data sets. If IMSLS_SVM_KERNEL_PRECOMPUTED is used, the required argument x is ignored.
float kernel_values[] (Input)
An array of length n_patterns by n_patterns containing the precomputed kernel function values. Assume there are L training instances x1, x2, …, xL and let K(x,y) be the kernel function value of two instances x and y. Row i of the testing or training data set would be represented by K(xi,x1) K(xi,x2)…K(xi,xL). All kernel function values, including zeros, must be provided.
An array of length n_patterns by n_patterns containing the precomputed kernel function values. Assume there are L training instances x1, x2, …, xL and let K(x,y) be the kernel function value of two instances x and y. Row i of the testing or training data set would be represented by K(xi,x1) K(xi,x2)…K(xi,xL). All kernel function values, including zeros, must be provided.
Default: IMSLS_SVM_KERNEL_RADIAL_BASIS, gamma = 1.0/n_attributes
IMSLS_SVM_CROSS_VALIDATION, int n_folds, float **target, float *result (Input/Output)
Conducts cross validation on n_folds folds of the data. imsls_f_random_uniform_discrete is used during the cross validation step. See the Description section for more information on cross validation. See the Usage Notes in Chapter 12, “Random Number Generation” for instructions on setting the seed to the random number generator if different seeds are desired.
Conducts cross validation on n_folds folds of the data. imsls_f_random_uniform_discrete is used during the cross validation step. See the Description section for more information on cross validation. See the Usage Notes in Chapter 12, “Random Number Generation” for instructions on setting the seed to the random number generator if different seeds are desired.
int n_folds (Input)
The number of folds of the data to be used in cross validation. n_folds must be greater than 1 and less than n_patterns.
The number of folds of the data to be used in cross validation. n_folds must be greater than 1 and less than n_patterns.
float **target (Output)
The address of a pointer to an array of length n_patterns containing the predicted labels
The address of a pointer to an array of length n_patterns containing the predicted labels
float *result (Output)
If the SVM type used is SVR, result contains the mean squared error. For all other SVM types result contains the accuracy percentage.
Default: Cross validation is not performed.
If the SVM type used is SVR, result contains the mean squared error. For all other SVM types result contains the accuracy percentage.
Default: Cross validation is not performed.
IMSLS_SVM_CROSS_VALIDATION_USER, int n_folds, float target[], float *result (Input/Output)
Storage for array target is provided by the user. See IMSLS_SVM_CROSS_VALIDATION for a description.
Storage for array target is provided by the user. See IMSLS_SVM_CROSS_VALIDATION for a description.
Description
Function imsls_f_support_vector_trainer trains an SVM classifier for classifying data into one of n_classes target classes. There are several SVM formulations that are supported through the optional arguments for classification, regression, and distribution estimation. The C-support vector classification (C-SVC) is the fundamental algorithm for the SVM optimization problem and its primal form is given as
Where (xi, yi) are the instance-label pairs for a given training set, where l is the number of training examples, and xi ∈ Rn and yi ∈ {1,-1}. ξi are the slack variables in optimization and is an upper bound on the number of errors. The regularization parameter C > 0 acts as a tradeoff parameter between error and margin. This is the default algorithm used and can be controlled through the use of the IMSLS_SVM_C_SVC_TYPE optional argument.
The ν-support vector classification (ν-SVC) algorithm presents a new parameter ν ∈ (0,1] which acts as an upper bound on the fraction of training errors and a lower bound on the fraction of support vectors. The use of this algorithm is triggered through the use of the IMSLS_SVM_NU_SVC_TYPE optional arguement. The primal optimization problem for the binary variable y ∈ {1,-1} is
The one-class SVM algorithm estimates the support of a high-dimensional distribution without any class information. Control of this algorithm is through the use of the IMSLS_SVM_ONE_CLASS_TYPE optional argument. The primal problem of one-class SVM is
If zi is the target output and given the parameters C > 0, ɛ > 0, the standard form of ɛ-support vector regression (ɛ-SVR) is
where the two slack variables ξi and ξi* are introduced, one for exceeding the target value by more than ɛ and the other for being more than ɛ below the target. The use of this algorithm is triggered through the use of the IMSLS_SVM_EPSILON_SVR_TYPE optional argument.
Similar to ν-SVC, in ν-support vector regression (ν-SVR) the parameter ν ∈ (0,1] controls the number of support vectors. Use IMSLS_SVM_NU_SVR_TYPE to trigger this algorithm. The ν-SVR primal problem is
The decomposition method used to solve the dual formulation of these primal problems is an SMO-type (sequential minimal optimization) decomposition method proposed by Fan et. al. (2005).
The IMSLS_SVM_CROSS_VALIDATION optional argument allows one to estimate how accurately the resulting training model will perform in practice. The cross validation technique partitions the training data into n_folds complementary subsets. Each of the subsets is subsequently used in training and validated against the remaining subsets. The validation results of the rounds are then averaged. The result is usually a good indicator of how the trained model will perform on unclassified data.
Function imsls_f_support_vector_trainer is based on LIBSVM, Copyright (c) 2000-2013, with permission from the authors, Chih-Chung Chang and Chih-Jen Lin, with the following disclaimer:
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
Examples
Example 1
In this example, we use a subset of the Fisher Iris data to train the classifier. The default values of imsls_f_support_vector_trainer are used in the training. The resultant classifier model, stored in svm_classifier, is then used as input to imsls_f_support_vector_classification to classify all of the patterns in the Fisher Iris data set. Results of the classification are then printed. In the Fisher Iris data set, the first column is the target classification value, 1=Setosa, 2=Versicolour, and 3=Virginica. Columns 2 through 5 contain the attributes sepal length, sepal width, petal length, and petal width.
#include <imsls.h>
#include <stdio.h>
int main()
{
int i, ii, j, jj, k, kk, method=1;
int n_patterns =150; /* 150 total patterns */
int n_patterns_train =30; /* 30 training patterns */
int n_attributes =4; /* four attributes */
int n_classes =3; /* three classification categories */
int *class_errors=NULL;
float classification[150], *predictedClass=NULL, *xx=NULL;
float x[150*4], training_data[30*4], training_classification[150];
float *irisData=NULL; /* Fishers Iris Data */
float real_min=0.0, real_max=10.0, target_min=0.0, target_max=1.0;
char *classLabel[] = {"Setosa ", "Versicolour", "Virginica "};
char dashes[] = {
"--------------------------------------------------------------"
};
char wspace[] = {" "};
Imsls_f_svm_model *svm_classifier=NULL;
/* irisData[]: The raw data matrix. This is a 2-D matrix with 150 */
/* rows and 5 columns. The first column is the target */
/* classification value (1-3), and the last 4 columns */
/* are the continuous input attributes. These data */
/* contain no categorical input attributes. */
irisData = imsls_f_data_sets(3,0);
/* Data corrections described in the KDD data mining archive */
irisData[5*34+4] = 0.1;
irisData[5*37+2] = 3.1;
irisData[5*37+3] = 1.5;
/* Set up the required input arrays from the data matrix */
for(i=0; i<n_patterns; i++){
classification[i] = irisData[i*5];
for(j=1; j<=n_attributes; j++) {
x[i*n_attributes+j-1] = irisData[i*5+j];
}
}
/* Scale the data */
xx = imsls_f_scale_filter(n_attributes*n_patterns, x, method,
IMSLS_SCALE_LIMITS, real_min, real_max, target_min, target_max,
0);
/* Use a subset of the data for training */
ii = 0;
jj = 0;
printf(" The Input Classification and Training Data \n\n\n");
printf("Classification Sepal Sepal Petal Petal\n");
printf(" Value Length Width Length Width\n\n");
for(i=0;i<3;i++){
kk = 0;
for(j=0;j<10;j++){
training_classification[ii] = classification[(i*50)+j];
printf(" %8.4f ", training_classification[ii]);
ii++;
for(k=0; k<4; k++){
training_data[jj] = xx[(i*200)+kk++];
printf("%8.4f ", training_data[jj]);
jj++;
}
printf("\n");
}
}
/* Train with the training data */
svm_classifier = imsls_f_support_vector_trainer(
n_patterns_train, n_classes, n_attributes,
training_classification, training_data, 0);
/* Classify the entire test set */
predictedClass = imsls_f_support_vector_classification(
svm_classifier, n_patterns, xx,
IMSLS_CLASS_ERROR, classification, &class_errors,
0);
printf("\n\n\n Some Output Classifications\n\n");
printf("Pattern Predicted Actual\n");
printf("Number Classification Classification\n\n");
for (i = 0; i < 10; i++) {
printf("%2s%d%10s%8.4f%11s%8.4f\n\n",wspace,i,wspace,
predictedClass[i],wspace,classification[i]);
}
printf("\n\n Iris Classification Error Rates\n");
printf("%s\n",dashes);
printf(" Setosa Versicolour Virginica | TOTAL\n");
printf(" %d/%d %d/%d %d/%d | %d/%d\n",
class_errors[0], class_errors[1],
class_errors[2], class_errors[3], class_errors[4],
class_errors[5], class_errors[6], class_errors[7]);
printf("%s\n\n", dashes);
if (svm_classifier) imsls_f_svm_classifier_free(svm_classifier);
if (predictedClass) imsls_free(predictedClass);
if (class_errors) imsls_free(class_errors);
if (irisData) imsls_free(irisData);
if (xx) imsls_free(xx);
}
Output
The Input Classification and Training Data
Classification Sepal Sepal Petal Petal
Value Length Width Length Width
1.0000 0.5100 0.3500 0.1400 0.0200
1.0000 0.4900 0.3000 0.1400 0.0200
1.0000 0.4700 0.3200 0.1300 0.0200
1.0000 0.4600 0.3100 0.1500 0.0200
1.0000 0.5000 0.3600 0.1400 0.0200
1.0000 0.5400 0.3900 0.1700 0.0400
1.0000 0.4600 0.3400 0.1400 0.0300
1.0000 0.5000 0.3400 0.1500 0.0200
1.0000 0.4400 0.2900 0.1400 0.0200
1.0000 0.4900 0.3100 0.1500 0.0100
2.0000 0.7000 0.3200 0.4700 0.1400
2.0000 0.6400 0.3200 0.4500 0.1500
2.0000 0.6900 0.3100 0.4900 0.1500
2.0000 0.5500 0.2300 0.4000 0.1300
2.0000 0.6500 0.2800 0.4600 0.1500
2.0000 0.5700 0.2800 0.4500 0.1300
2.0000 0.6300 0.3300 0.4700 0.1600
2.0000 0.4900 0.2400 0.3300 0.1000
2.0000 0.6600 0.2900 0.4600 0.1300
2.0000 0.5200 0.2700 0.3900 0.1400
3.0000 0.6300 0.3300 0.6000 0.2500
3.0000 0.5800 0.2700 0.5100 0.1900
3.0000 0.7100 0.3000 0.5900 0.2100
3.0000 0.6300 0.2900 0.5600 0.1800
3.0000 0.6500 0.3000 0.5800 0.2200
3.0000 0.7600 0.3000 0.6600 0.2100
3.0000 0.4900 0.2500 0.4500 0.1700
3.0000 0.7300 0.2900 0.6300 0.1800
3.0000 0.6700 0.2500 0.5800 0.1800
3.0000 0.7200 0.3600 0.6100 0.2500
Some Output Classifications
Pattern Predicted Actual
Number Classification Classification
0 1.0000 1.0000
1 1.0000 1.0000
2 1.0000 1.0000
3 1.0000 1.0000
4 1.0000 1.0000
5 1.0000 1.0000
6 1.0000 1.0000
7 1.0000 1.0000
8 1.0000 1.0000
9 1.0000 1.0000
Iris Classification Error Rates
--------------------------------------------------------------
Setosa Versicolour Virginica | TOTAL
0/50 4/50 5/50 | 9/150
--------------------------------------------------------------
Example 2
In this example we use a subset of the Fisher Iris data to train the classifier and use the cross-validation option with various combinations of C and gamma to find a combination which yields the best results on the training data. The best combination of C and gamma are then used to get the classification model, stored in svm_classifier. This model is then used as input to imsls_f_support_vector_classification to classify all of the patterns in the Fisher Iris data set. Results of the classification are then printed.
#include <imsls.h>
#include <stdio.h>
int main()
{
int i, ii, j, jj, k, kk, method=1;
int n_patterns_train =30; /* 30 training patterns */
int n_patterns =150; /* 150 total patterns */
int n_attributes =4; /* four attributes */
int n_classes =3; /* three classification categories */
int nr_weight =0;
int n_folds =3;
int degree=0;
int *class_errors=NULL;
float C, gamma, coef0=0.0, best_accuracy, best_C, best_gamma, result;
float *weight_class=NULL;
float *weight=NULL;
float classification[150], *predictedClass=NULL, *xx=NULL;
float x[150*4], training_data[150*4];
float training_classification[30];
float *irisData=NULL; /* Fishers Iris Data */
float *target=NULL;
float real_min=0.0, real_max=10.0, target_min=0.0, target_max=1.0;
char *classLabel[] = {"Setosa ", "Versicolour", "Virginica "};
char dashes[] = {
"--------------------------------------------------------------"
};
Imsls_f_svm_model *svm_classifier=NULL;
/* irisData[]: The raw data matrix. This is a 2-D matrix with 150 */
/* rows and 5 columns. The first column is the target */
/* classification value (1-3), and the last 4 columns */
/* are the continuous input attributes. These data */
/* contain no categorical input attributes. */
irisData = imsls_f_data_sets(3,0);
/* Data corrections described in the KDD data mining archive */
irisData[5*34+4] = 0.1;
irisData[5*37+2] = 3.1;
irisData[5*37+3] = 1.5;
/* Set up the required input arrays from the data matrix */
for(i=0; i<n_patterns; i++){
classification[i] = irisData[i*5];
for(j=1; j<=n_attributes; j++) {
x[i*n_attributes+j-1] = irisData[i*5+j];
}
}
/* Scale the data */
xx = imsls_f_scale_filter(n_attributes*n_patterns, x, method,
IMSLS_SCALE_LIMITS, real_min, real_max, target_min, target_max,
0);
/* Use a subset of the data for training */
ii = 0;
jj = 0;
for(i=0;i<3;i++){
kk = 0;
for(j=0;j<10;j++){
training_classification[ii++] = classification[(i*50)+j];
for(k=0; k<4; k++){
training_data[jj] = xx[(i*200)+kk];
kk++;
jj++;
}
}
}
C = 2.0;
/* Try different combinations of C and gamma to settle on model parameters */
best_accuracy = 0.0;
best_C = 0.0;
best_gamma = 0.0;
for(i=0;i<10;i++){
gamma = .1;
for(j=0;j<5;j++){
svm_classifier = imsls_f_support_vector_trainer(
n_patterns_train, n_classes, n_attributes, training_classification,
training_data,
IMSLS_SVM_C_SVC_TYPE, C, nr_weight, weight_class, weight,
IMSLS_SVM_KERNEL_RADIAL_BASIS, gamma,
IMSLS_SVM_CROSS_VALIDATION, n_folds, &target, &result,
0);
if(result > best_accuracy){
best_accuracy = result;
best_C = C;
best_gamma = gamma;
}
gamma = gamma*2.0;
imsls_f_svm_classifier_free(svm_classifier);
if(target) imsls_free(target);
}
C = C*2.0;
}
/* Train with the best resultant parameters */
svm_classifier = imsls_f_support_vector_trainer(
n_patterns_train, n_classes, n_attributes, training_classification,
training_data,
IMSLS_SVM_C_SVC_TYPE, best_C, nr_weight, weight_class, weight,
IMSLS_SVM_KERNEL_RADIAL_BASIS, best_gamma,
0);
/* Call SUPPORT_VECTOR_CLASSIFICATION on the entire test set */
predictedClass = imsls_f_support_vector_classification(
svm_classifier, n_patterns, xx,
IMSLS_CLASS_ERROR, classification, &class_errors,
0);
printf(" Iris Classification Error Rates\n");
printf("%s\n",dashes);
printf(" Setosa Versicolour Virginica | TOTAL\n");
printf(" %d/%d %d/%d %d/%d | %d/%d\n",
class_errors[0], class_errors[1],
class_errors[2], class_errors[3], class_errors[4],
class_errors[5], class_errors[6], class_errors[7]);
printf("%s\n\n", dashes);
if (svm_classifier) imsls_f_svm_classifier_free(svm_classifier);
if (predictedClass) imsls_free(predictedClass);
if (class_errors) imsls_free(class_errors);
if (irisData) imsls_free(irisData);
if (xx) imsls_free(xx);
}
Output
Iris Classification Error Rates
--------------------------------------------------------------
Setosa Versicolour Virginica | TOTAL
0/50 1/50 3/50 | 4/150
Example 3
One thousand uniform deviates from a uniform distribution are used in the training data set of this example. IMSLS_SVM_ONE_CLASS_TYPE is used to produce the model during training. A test data set of one hundred uniform deviates is produced and contaminated with ten normal deviates. imsls_f_support_vector_classification is then called in an attempt to pick out the contaminated data in the test data set. The suspect observations are printed.
#include <stdio.h>
#include <imsls.h>
#define N_PATTERNS_TRAIN 1000
#define N_PATTERNS_TEST 100
#define N_PATTERNS_TEN 10
#define N_CLASSES 1
#define N_ATTRIBUTES 1
int main()
{
int i;
float *target=NULL;
float classification_train[N_PATTERNS_TRAIN];
float classification_test[N_PATTERNS_TEST];
float *x_train;
float *x_test;
float *x_test_contaminant;
Imsls_f_svm_model *svm_classifier=NULL;
/* Create the training set from a uniform distribution */
imsls_random_seed_set(123457);
x_train = imsls_f_random_uniform(N_PATTERNS_TRAIN, 0);
for(i=0;i<N_PATTERNS_TRAIN;i++)
classification_train[i] = 1.0;
svm_classifier = imsls_f_support_vector_trainer(N_PATTERNS_TRAIN, N_CLASSES,
N_ATTRIBUTES, classification_train, x_train,
IMSLS_SVM_ONE_CLASS_TYPE, .001,
0);
/* Create a testing set from a uniform distribution */
x_test = imsls_f_random_uniform(N_PATTERNS_TEST, 0);
for(i=0;i<N_PATTERNS_TEST;i++)
classification_test[i] = 1.0;
/* Contaminate the testing set with deviates from a normal distribution */
x_test_contaminant = imsls_f_random_normal(N_PATTERNS_TEN,
IMSLS_MEAN, .1,
IMSLS_VARIANCE, .2,
0);
for(i=0;i<N_PATTERNS_TEN;i++)
x_test[i*10] = x_test_contaminant[i];
target = imsls_f_support_vector_classification(svm_classifier,
N_PATTERNS_TEST, x_test, 0);
printf("\n\n\n Classification Results \n\n");
for(i=0; i<N_PATTERNS_TEST; i++){
if (target[i]!=1.0){
printf("The %d-th observation may not to belong to the",i);
printf(" target distribution.\n");
}
}
if (svm_classifier) imsls_f_svm_classifier_free(svm_classifier);
if (target) imsls_free(target);
if (x_train) imsls_free(x_train);
if (x_test) imsls_free(x_test);
if (x_test_contaminant) imsls_free(x_test_contaminant);
}
Output
Classification Results
The 0-th observation may not belong to the target distribution.
The 20-th observation may not belong to the target distribution.
The 30-th observation may not belong to the target distribution.
The 40-th observation may not belong to the target distribution.
The 60-th observation may not belong to the target distribution.
The 70-th observation may not belong to the target distribution.
Example 4
This example uses IMSLS_SVM_NU_SVR_TYPE to create a regression model which is used by imsls_f_support_vector_classification in an attempt to predict values in the test data set. The predicted values are printed.
#include <stdio.h>
#include <imsls.h>
#define N_PATTERNS_TRAIN 10
#define N_PATTERNS_TEST 4
#define N_CLASSES 2
#define N_ATTRIBUTES 2
int main()
{
int i;
float C=50., nu=.01, diff, mse=0.0, *target=NULL;
float classification_train[] = {1.0,1.0,1.0,1.0,1.0,2.0,2.0,2.0,2.0,2.0};
float classification_test[] = {1.0,1.0,2.0,2.0};
float x_train[] = { 0.19, 0.61,
0.156, 0.564,
0.224, 0.528,
0.178, 0.51,
0.234, 0.578,
0.394, 0.296,
0.478, 0.254,
0.454, 0.294,
0.48, 0.358,
0.398, 0.336};
float x_test[] = {
0.316, 0.556,
0.278, 0.622,
0.562, 0.336,
0.522, 0.412};
Imsls_f_svm_model *svm_classifier=NULL;
svm_classifier = imsls_f_support_vector_trainer(N_PATTERNS_TRAIN,
N_CLASSES, N_ATTRIBUTES, classification_train, x_train,
IMSLS_SVM_NU_SVR_TYPE, C, nu,
0);
target = imsls_f_support_vector_classification(svm_classifier,
N_PATTERNS_TEST, x_test, 0);
mse = 0.0;
printf("Predicted Actual Difference \n");
for(i=0;i<N_PATTERNS_TEST;i++){
diff = (target[i] - classification_test[i]);
printf("%f %f %f \n",target[i], classification_test[i], diff);
mse = mse + (diff*diff);
}
mse = mse/N_PATTERNS_TEST;
printf("\n The Mean squared error for the predicted values is %f \n",
mse);
if (svm_classifier) imsls_f_svm_classifier_free(svm_classifier);
if (target) imsls_free(target);
}
Output
Predicted Actual Difference
1.443569 1.000000 0.443569
1.397248 1.000000 0.397248
1.648531 2.000000 -0.351469
1.598311 2.000000 -0.401689
The Mean squared error for the predicted values is 0.159861
Warning Errors
IMSLS_OPTION_NOT_SUPPORTED | The optional argument # is not supported for #. |
IMSLS_LABEL_NOT_FOUND | The class label # specified in “weight” not found. |
IMSLS_INADEQUATE_MODEL | The model used contains inadequate information to compute the requested probability. |
IMSLS_TWO_CLASS_LINE_SEARCH | The line search failed in a two-class probability estimation while performing cross validation. |
IMSLS_VALIDATION_MAX_ITERATIONS | The maximum number of iterations was reached in a #-class probability estimation while performing cross validation. |




