Usage Notes
The regression models in this chaptersection include the simple and multiple linear regression models, the multivariate general linear model, the polynomial model, and the nonlinear regression model. Functions for fitting regression models, computing summary statistics from a fitted regression, computing diagnostics, and computing confidence intervals for individual cases are provided. This chaptersection also provides methods for building a model from a set of candidate variables.
Simple and Multiple Linear Regression
The simple linear regression model is
yi = β0 + β1xi + ɛi i = 1, 2, ..., n
where the observed values of the yi's constitute the responses or values of the dependent variable, the xi's are the settings of the independent (explanatory) variable, β0 and β1 are the intercept and slope parameters (respectively) and the ɛi's are independently distributed normal errors, each with mean 0 and variance σ2.
The multiple linear regression model is
yi = β0 + β1xi1 + β2xi2 + ... + βkxik + ɛi i = 1, 2, ..., n
where the observed values of the yi's constitute the responses or values of the dependent variable; the xi1's, xi2's, ..., xik's are the settings of the k independent (explanatory) variables; β0, β1, ..., β k are the regression coefficients; and the ɛi's are independently distributed normal errors, each with mean 0 and variance σ2.
Function imsls_f_regression fits both the simple and multiple linear regression models using a fast Given's transformation and includes an option for excluding the intercept β0. The responses are input in array y, and the independent variables are input in array x, where the individual cases correspond to the rows and the variables correspond to the columns.
After the model has been fitted using imsls_f_regression, function imsls_f_regression_summary computes summary statistics and imsls_f_regression_prediction computes predicted values, confidence intervals, and case statistics for the fitted model. The information about the fit is communicated from imsls_f_regression to imsls_f_regression_summary and imsls_f_regression_prediction by passing an argument of structure type Imsls_f_regression.
No Intercept Model
Several functions provide the option for excluding the intercept from a model. In most practical applications, the intercept should be included in the model. For functions that use the sums of squares and crossproducts matrix as input, the no-intercept case can be handled by using the raw sums of squares and crossproducts matrix as input in place of the corrected sums of squares and crossproducts. The raw sums of squares and crossproducts matrix can be computed as (x1, x2, ..., xk, y)T (x1, x2, ..., xk, y).
Variable Selection
Variable selection can be performed by imsls_f_regression_selection, which computes all best-subset regressions, or by imsls_f_regression_stepwise, which computes stepwise regression. The method used by imsls_f_regression_selection is generally preferred over that used by imsls_f_regression_stepwise because imsls_f_regression_selection implicitly examines all possible models in the search for a model that optimizes some criterion while stepwise does not examine all possible models. However, the computer time and memory requirements for imsls_f_regression_selection can be much greater than that for imsls_f_regression_stepwise when the number of candidate variables is large.
Polynomial Model
The polynomial model is
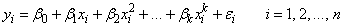
where the observed values of the yi's constitute the responses or values of the dependent variable; the xi's are the settings of the independent (explanatory) variable; β0, β1, ..., βk are the regression coefficients; and the ɛi's are independently distributed normal errors each with mean 0 and variance σ2.
Function imsls_f_poly_regression fits a polynomial regression model with the option of determining the degree of the model and also produces summary information. Function imsls_f_poly_prediction computes predicted values, confidence intervals, and case statistics for the model fit by imsls_f_poly_regression.
The information about the fit is communicated from imsls_f_poly_regression to imsls_f_poly_prediction by passing an argument of structure type Imsls_f_poly_regression.
Specification of X for the General Linear Model
Variables used in the general linear model are either continuous or classification variables. Typically, multiple regression models use continuous variables, whereas analysis of variance models use classification variables. Although the notation used to specify analysis of variance models and multiple regression models may look quite different, the models are essentially the same. The term “general linear model” emphasizes that a common notational scheme is used for specifying a model that may contain both continuous and classification variables.
A general linear model is specified by its effects (sources of variation). An effect is referred to in this text as a single variable or a product of variables. (The term “effect” is often used in a narrower sense, referring only to a single regression coefficient.) In particular, an “effect” is composed of one of the following:
1. a single continuous variable
2. a single classification variable
3. several different classification variables
4. several continuous variables, some of which may be the same
5. continuous variables, some of which may be the same, and classification variables, which must be distinct
Effects of the first type are common in multiple regression models. Effects of the second type appear as main effects in analysis of variance models. Effects of the third type appear as interactions in analysis of variance models. Effects of the fourth type appear in polynomial models and response surface models as powers and crossproducts of some basic variables. Effects of the fifth type appear in one-way analysis of covariance models as regression coefficients that indicate lack of parallelism of a regression function across the groups.
The analysis of a general linear model occurs in two stages. The first stage calls function imsls_f_regressors_for_glm to specify all regressors except the intercept. The second stage calls imsls_f_regression, at which point the model will be specified as either having (default) or not having an intercept.
For this discussion, define a variable INTCEP as follows:
|
Option |
INTCEP |
Action |
|
IMSLS_NO_INTERCEPT IMSLS_INTERCEPT (default) |
0 1 |
An intercept is not in the model. An intercept is in the model. |
The remaining variables (n_continuous,
n_class,
x_class_columns,
n_effects,
n_var_effects,
and indices_effects)
are defined for function imsls_f_regressors_for_glm. All these
variables have defaults except for n_continuous
and n_class,
both of which must be specified.
(See the documentation for imsls_f_regressors_for_glm for a
discussion of the defaults.) The meaning of each of these arguments is as
follows:
n_continuous
(Input)
Number of continuous variables.
n_class
(Input)
Number of classification variables.
x_class_columns
(Input)
Index vector of length n_class containing the
column numbers of
x that are the
classification variables.
n_effects
(Input)
Number of effects (sources of variation) in the model, excluding
error.
n_var_effects
(Input)
Vector of length n_effects containing
the number of variables associated with each effect in the model.
indices_effects
(Input)
Index vector of length n_var_effects(0) +
n_var_effects(1)
+ ... + n_var_effects (n_effects – 1).
The first n_var_effects(0)
elements give the column numbers of x for each variable in
the first effect; the next n_var_effects(1)
elements give the column numbers for each variable in the second effect; and
finally, the last n_var_effects (n_effects – 1)
elements give the column numbers for each variable in the last effect.
Suppose the data matrix has as its first four columns two continuous variables in Columns 0 and 1 and two classification variables in Columns 2 and 3. The data might appear as follows:
|
Column 0 |
Column 1 |
Column 2 |
Column 3 |
|
11.23 |
1.23 |
1.0 |
5.0 |
|
12.12 |
2.34 |
1.0 |
4.0 |
|
12.34 |
1.23 |
1.0 |
4.0 |
|
4.34 |
2.21 |
1.0 |
5.0 |
|
5.67 |
4.31 |
2.0 |
4.0 |
|
4.12 |
5.34 |
2.0 |
1.0 |
|
4.89 |
9.31 |
2.0 |
1.0 |
|
9.12 |
3.71 |
2.0 |
1.0 |
Each distinct value of a classification variable determines a level. The classification variable in Column 2 has two levels. The classification variable in Column 3 has three levels. (Integer values are recommended, but not required, for values of the classification variables. The values of the classification variables corresponding to the same level must be identical.) Some examples of regression functions and their specifications are as follows:
|
|
INTCEP |
n_class |
x_class_columns |
|
β0 + β1x1 |
1 |
0 |
|
|
β0+β1x1+β2x12 |
1 |
0 |
|
|
μ+αi |
1 |
1 |
2 |
|
μ+αi+βj+γij |
1 |
2 |
2, 3 |
|
μij |
0 |
2 |
2, 3 |
|
Β0+β1x1+β2x2+β3x1x2 |
1 |
0 |
|
|
μ+αi+βx1i+βix1i |
1 |
1 |
2 |
|
|
n_effects |
n_var_effects |
Indices_effects |
|
β0+β1x1 |
1 |
1 |
0 |
|
β0+β1x1+β2x12 |
2 |
1, 2 |
0, 0, 0 |
|
μ+αi |
1 |
1 |
2 |
|
μ+αi+βj+γij |
3 |
1, 1, 2 |
2, 3, 2, 3 |
|
μij |
1 |
2 |
2, 3 |
|
β0+β1x1+β2x2+β3x1x2 |
3 |
1, 1, 2 |
0, 1, 0, 1 |
|
μ+αi+βx1i+βix1i |
3 |
1, 1, 2 |
2, 0, 0, 2 |
Functions for Fitting the Model
Function imsls_f_regression fits a multivariate general linear model, where regressors for the general linear model have been generated using function imsls_f_regressors_for_glm.
Linear Dependence and the R Matrix
Linear dependence of the regressors frequently arises in regression models—sometimes by design and sometimes by accident. The functions in this chaptersection are designed to handle linear dependence of the regressors; i.e., the n × p matrix X (the matrix of regressors) in the general linear model can have rank less than p. Often, the models are referred to as non-full rank models.
As discussed in Searle (1971, Chapter 5), be careful to correctly use the results of the fitted non-full rank regression model for estimation and hypothesis testing. In the non-full rank case, not all linear combinations of the regression coefficients can be estimated. Those linear combinations that can be estimated are called “estimable functions.” If the functions are used to attempt to estimate linear combinations that cannot be estimated, error messages are issued. A good general discussion of estimable functions is given by Searle (1971, pp. 180–188).
The check used by functions in this chaptersection for linear dependence is sequential. The j-th regressor is declared linearly dependent on the preceding j − 1 regressors if
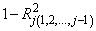
is less than or equal to tolerance. Here,
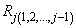
is the multiple correlation coefficient of the j-th regressor with the first j − 1 regressors. When a function declares the j-th regressor to be linearly dependent on the first j − 1, the j-th regression coefficient is set to 0. Essentially, this removes the j-th regressor from the model.
The reason a sequential check is used is that practitioners frequently include the preferred variables to remain in the model first. Also, the sequential check is based on many of the computations already performed as this does not degrade the overall efficiency of the functions. There is no perfect test for linear dependence when finite precision arithmetic is used. The optional argument IMSLS_TOLERANCE allows the user some control over the check for linear dependence. If a model is full rank, input tolerance = 0.0. However, tolerance should be input as approximately 100 times the machine epsilon. The machine epsilon is imsls_f_machine(4) in single precision and imsls_d_machine(4) in double precision. (See functions imsls_f_machine and imsls_d_machine in Chapter 15, “Utilities”.)
Functions performing least squares are based on QR
decomposition of X or on a Cholesky factorization RTR of
XTX. Maindonald
(1984, Chapters 1−5)
discusses these methods extensively. The R matrix used by the regression
function is a
p × p
upper-triangular matrix, i.e., all elements below the diagonal are 0. The signs
of the diagonal elements of R are used as indicators of linearly
dependent regressors and as indicators of parameter restrictions imposed by
fitting a restricted model. The rows of R can be partitioned into three
classes by the sign of the corresponding diagonal element:
1. A positive diagonal element means the row corresponds to data.
2. A negative diagonal element means the row corresponds to a linearly independent restriction imposed on the regression parameters by AB = Z in a restricted model.
3. A zero
diagonal element means a linear dependence of the regressors was declared. The
regression coefficients in the corresponding row of 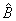 are set to 0. This
represents an arbitrary restriction that is imposed to obtain a solution for the
regression coefficients. The elements of the corresponding row of R also
are set to 0.
are set to 0. This
represents an arbitrary restriction that is imposed to obtain a solution for the
regression coefficients. The elements of the corresponding row of R also
are set to 0.
Nonlinear Regression Model
The nonlinear regression model is
yi = f(xi;θ) + ɛi i = 1, 2, …, n
where the observed values of the yi's constitute the responses or values of the dependent variable, the xi's are the known vectors of values of the independent (explanatory) variables, f is a known function of an unknown regression parameter vector θ, and the ɛi's are independently distributed normal errors each with mean 0 and variance σ2.
Function imsls_f_nonlinear_regression performs the least-squares fit to the data for this model.
Weighted Least Squares
Functions throughout the chapter generally allow weights to be assigned to the observations. The vector weights is used throughout to specify the weighting for each row of X.
Computations that relate to statistical inference—e.g., t tests, F tests, and confidence intervals—are based on the multiple regression model except that the variance of ɛi is assumed to equal σ2 times the reciprocal of the corresponding weight.
If a single row of the data matrix corresponds to ni observations, the vector frequencies can be used to specify the frequency for each row of X. Degrees of freedom for error are affected by frequencies but are unaffected by weights.
Summary Statistics
Function imsls_f_regression_summary can be used to compute and print statistics related to a regression for each of the q dependent variables fitted by imsls_f_regression. The summary statistics include the model analysis of variance table, sequential sums of squares and F-statistics, coefficient estimates, estimated standard errors, t-statistics, variance inflation factors, and estimated variance-covariance matrix of the estimated regression coefficients. Function imsls_f_poly_regression includes most of the same functionality for polynomial regressions.
The summary statistics are computed under the model y = Xβ + ɛ, where y is the n × 1 vector of responses, X is the n × p matrix of regressors with rank (X) = r, β is the p × 1 vector of regression coefficients, and ɛ is the n × 1 vector of errors whose elements are independently normally distributed with mean 0 and variance σ2∕wi.
Given the results of a weighted least-squares fit of this model (with the wi's as the weights), most of the computed summary statistics are output in the following variables:
anova_table
One-dimensional
array usually of length 15. In imsls_f_regression_stepwise, anova_table is of
length 13 because the last two elements of the array cannot be computed from the
input. The array contains statistics related to the analysis of variance. The
sources of variation examined are the regression, error, and total. The first 10
elements of anova_table and the
notation frequently used for these is described in the following table (here,
AOV replaces
anova_table):
|
Model Analysis of Variance Table | |||||
|
Source of Variation |
Degrees of Freedom |
Sum of Squares |
|
|
|
|
Regression |
DFR = AOV[0] |
SSR = AOV[3] |
MSR = AOV[6] |
AOV[8] |
AOV[9] |
|
Error |
DFE = AOV[1] |
SSE = AOV[4] |
s2 = AOV[7] |
|
|
|
Total |
DFT = AOV[2] |
SST = AOV[5] |
|
|
|
If the model has an intercept (default), the total sum of squares is the sum of
squares of the deviations of yi from its (weighted) mean
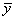 —the so-called
corrected total sum of squares, denoted by the following:
—the so-called
corrected total sum of squares, denoted by the following:
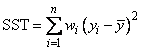
If the model does not have an intercept (IMSLS_NO_INTERCEPT), the total sum of squares is the sum of squares of yi—the so-called uncorrected total sum of squares, denoted by the following:
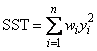
The error sum of squares is given as follows:
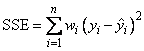
The error degrees of freedom is defined by DFE = n – r.
The estimate of σ2 is given by s2 = SSE∕DFE, which is the error mean square.
The computed F statistic for the null hypothesis, H0: β1 = β2 = ... = βk = 0, versus the alternative that at least one coefficient is nonzero is given by F = MSR∕s2. The p-value associated with the test is the probability of an F larger than that computed under the assumption of the model and the null hypothesis. A small p-value (less than 0.05) is customarily used to indicate there is sufficient evidence from the data to reject the null hypothesis.
The remaining five elements in anova_table frequently
are displayed together with the actual analysis of variance table. The
quantities
R-squared (R2 = anova_table[10]) and
adjusted R-squared
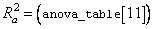
are expressed as a percentage and are defined as follows:
R2 = 100(SSR∕SST) = 100(1 – SSE∕SST)
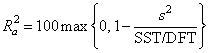
The square root of s2(s = anova_table[12]) is frequently referred to as the estimated standard deviation of the model error.
The overall mean of the responses is output in anova_table[13].
The coefficient of variation (CV = anova_table[14]) is
expressed as a percentage and defined by CV = 100s/.
coef_t_tests
Two-dimensional
matrix containing the regression coefficient vector 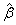 as one column and
associated statistics (estimated standard error, t statistic and
p-value) in the remaining columns.
as one column and
associated statistics (estimated standard error, t statistic and
p-value) in the remaining columns.
coef_covariances
Estimated
variance-covariance matrix of the estimated regression coefficients.
Tests for Lack-of-Fit
Tests for lack-of-fit are computed for the polynomial regression by the function imsls_f_poly_regression. The output array ssq_lof contains the lack-of-fit F tests for each degree polynomial 1, 2, ..., k, that is fit to the data. These tests are used to indicate the degree of the polynomial required to fit the data well.
Diagnostics for Individual Cases
Diagnostics for individual cases (observations) are computed by two functions: imsls_f_regression_prediction for linear and nonlinear regressions and imsls_f_poly_prediction for polynomial regressions.
Statistics computed include predicted values, confidence intervals, and diagnostics for detecting outliers and cases that greatly influence the fitted regression.
The diagnostics are computed under the model y = Xβ + ɛ, where y is the n × 1 vector of responses, X is the n × p matrix of regressors with rank (X) = r, β is the p × 1 vector of regression coefficients, and ɛ is the n × 1 vector of errors whose elements are independently normally distributed with mean 0 and variance σ2∕wi.
Given the results of a weighted least-squares fit of this model (with the wi's as the weights), the following five diagnostics are computed:
1. leverage
2. standardized residual
3. jackknife residual
4. Cook's distance
5. DFFITS
The definition of these terms is given in the discussion that follows:
Let xi be a column vector containing the
elements of the i-th row of X. A case can be unusual either
because of xi or because of the response yi.
The leverage
hi is a measure of uniqueness of the
xi. The leverage is defined by
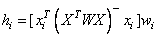
where W = diag(w1,
w2, …,
wn) and (XTWX)- denotes a generalized
inverse of XTWX. The average
value of the hi's is r∕n. Regression
functions declare
xi unusual if
hi > 2r∕n.
Hoaglin and Welsch (1978) call a data point highly influential (i.e.,
a leverage point) when this occurs.
Let ei denote the residual
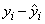
for the i-th case. The estimated variance of ei is (1 – hi)s2∕wi, where s2 is the residual mean square from the fitted regression. The i-th standardized residual (also called the internally studentized residual) is by definition
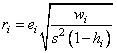
and ri follows an approximate standard normal distribution in large samples.
The i-th jackknife residual or deleted
residual involves the difference between
yi and its
predicted value, based on the data set in which the i-th case is deleted.
This difference equals ei∕(1 − hi).
The jackknife residual is obtained by standardizing this difference. The
residual mean square for the regression in which the i-th case is deleted
is as follows:
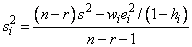
The jackknife residual is defined as
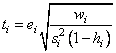
and ti follows a t distribution with n – r − 1 degrees of freedom.
Cook's distance for the i-th case is a measure of how much an individual case affects the estimated regression coefficients. It is given as follows:
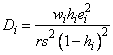
Weisberg (1985) states that if Di exceeds the 50-th percentile of the F(r, n − r ) distribution, it should be considered large. (This value is about 1. This statistic does not have an F distribution.)
DFFITS, like Cook's distance, is also a measure of influence. For the i-th case, DFFITS is computed by the formula below.
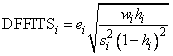
Hoaglin and Welsch (1978) suggest that DFFITS greater than
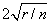
is large.
Transformations
Transformations of the independent variables are sometimes useful in order to satisfy the regression model. The inclusion of squares and crossproducts of the variables
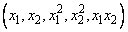
is often needed. Logarithms of the independent variables are used also. (See Draper and Smith 1981, pp. 218−222; Box and Tidwell 1962; Atkinson 1985, pp. 177−180; Cook and Weisberg 1982, pp. 78−86.)
When the responses are described by a nonlinear function of the parameters, a transformation of the model equation often can be selected so that the transformed model is linear in the regression parameters. For example, by taking natural logarithms on both sides of the equation, the exponential model
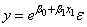
can be transformed to a model that satisfies the linear regression model provided the ɛi's have a log-normal distribution (Draper and Smith, pp. 222−225).
When the responses are nonnormal and their distribution is known, a transformation of the responses can often be selected so that the transformed responses closely satisfy the regression model, assumptions. The square-root transformation for counts with a Poisson distribution and the arc-sine transformation for binomial proportions are common examples (Snedecor and Cochran 1967, pp. 325−330; Draper and Smith, pp. 237−239).
Alternatives to Least Squares
The method of least squares has desirable characteristics when the errors are normally distributed, e.g., a least-squares solution produces maximum likelihood estimates of the regression parameters. However, when errors are not normally distributed, least squares may yield poor estimators. Function imsls_f_lnorm_regression offers three alternatives to least squares methodology, Least Absolute Value , Lp Norm , and Least Maximum Value.
The least absolute value (LAV, L1) criterion yields the maximum likelihood estimate when the errors follow a Laplace distribution. Option IMSLS_METHOD_LAV is often used when the errors have a heavy tailed distribution or when a fit is needed that is resistant to outliers.
A more general approach, minimizing the Lp norm
(p £ 1), is given by option
IMSLS_METHOD_LLP. Although the routine
requires about 30 times the CPU
time for the case p = 1 than would the use of IMSLS_METHOD_LAV, the generality of
IMSLS_METHOD_LLP allows the user to
try several choices for
p ³
1 by simply changing the input value of p in the calling program. The
CPU
time decreases as p gets larger. Generally, choices of p between 1
and 2 are of interest. However, the Lp norm solution for values of
p larger than 2 can also be computed.
The minimax (LMV, L∞, Chebyshev) criterion is used by IMSLS_METHOD_LMV. Its estimates are very sensitive to outliers, however, the minimax estimators are quite efficient if the errors are uniformly distributed.
Missing Values
NaN (Not a Number) is the missing value code used by the regression functions. Use function imsls_f_machine(6), Chapter 15 , “Ultilities”; (or function imsls_d_machine(6) with double-precision regression functions) to retrieve NaN. Any element of the data matrix that is missing must be set to imsls_f_machine(6) (or imsls_d_machine(6) for double precision). In fitting regression models, any observation containing NaN for the independent, dependent, weight, or frequency variables is omitted from the computation of the regression parameters.
|
Visual Numerics, Inc. PHONE: 713.784.3131 FAX:713.781.9260 |