
Fit a binomial or multinomial logistic regression model using iteratively reweighted least squares.
Synopsis
#include <imsls.h>
float *imsls_f_logistic_regression (int n_observations, int n_independent, int n_classes, float x[], float y[], ..., 0)
The type double function is imsls_d_logistic_regression.
Required Arguments
int
n_observations (Input)
The number of observations.
int
n_independent (Input)
The number of independent
variables.
int n_classes
(Input)
The number of discrete outcomes, or classes.
float x[]
(Input)
An array of length n_observations × n_independent
containing the values of the independent variables corresponding to the
responses in y.
float y[]
(Input)
An array of length n_observations × n_classes containing
the binomial (n_classes = 2)
or multinomial (n_classes>2) counts
per class. In an alternate format, y is an array of
length n_observations × (n_classes - 1)
containing the counts for all but one class. The missing class is treated
as the reference class. The optional argument GROUP_COUNTS specifies
this format for y. In another
alternative format, y is an array of
length n_observations
containing the class id’s. See optional argument IMSLS_GROUPS.
Return Value
Pointer to an array of length n_coefficients × n_classes containing the estimated coefficients. The function fits a full model, where n_coefficients = 1 + n_independent. The optional arguments IMSLS_NO_INTERCEPT, IMSLS_X_INDICES, and IMSLS_X_INTERACTIONS may be used to specify different models. Note that the last column (column n_classes) represents the reference class and is set to all zeros.
Synopsis with Optional Arguments
#include <imsls.h>
float
*imsls_f_logistic_regression (int
n_observations,
int n_independent,
int n_classes,
float x[],
float y[],
IMSLS_GROUP_COUNTS,
or
IMSLS_GROUPS,
IMSLS_COLUMN_WISE,
IMSLS_FREQUENCIES, int
frequencies[],
IMSLS_REFERENCE_CLASS, int
ref_class,
IMSLS_NO_INTERCEPT,
IMSLS_X_INDICES,
int
n_xin, int
xin[],
IMSLS_X_INTERACTIONS,
int
n_xinteract, int
xinteract[],
IMSLS_TOLERANCE, float
tolerance,
IMSLS_MAX_ITER,
int max_iter,
IMSLS_INIT_INPUT, int
init,
IMSLS_PREV_RESULTS,
Imsls_f_model *prev_model,
IMSLS_NEXT_RESULTS,
Imsls_f_model
**next_model,
IMSLS_COEFFICIENTS, float
coefficients[],
IMSLS_LRSTAT, float
*lrstat,
0)
Optional Arguments
IMSLS_GROUP_COUNTS
or
IMSLS_GROUPS (Input)
These optional arguments specify the
format of the input array y. If IMSLS_GROUP_COUNTS is
present, y is of
length n_observations × (n_classes - 1), and
contains counts for all but one of the classes for each observation. The
missing class is treated as the reference class.
If IMSLS_GROUPS is
present, the input array y is of length n_observations, and
y[i] contains
the group or class number to which the i-th
observation belongs. In this case, frequencies[i] is set
to 1 for all observations.
Default: y is n_observations × (n_classes), and
contains counts for all the classes.
IMSLS_COLUMN_WISE
(Input)
If present, the input arrays are column-oriented.
That is, contiguous elements in x are values of the
same independent variable, or column, except at multiples of n_observations.
Default:
Input arrays are row-oriented.
IMSLS_FREQUENCIES, int frequencies[]
(Input)
An array of length n_observations
containing the number of replications or trials for each of the observations.
This argument is required if IMSLS_GROUP_COUNTS is
specified and any element of y > 1.
Default:
frequencies[i] = 1.
IMSLS_REFERENCE_CLASS, int ref_class
(Input)
Number specifying which class or outcome category to use as the
reference class. See the Description section
for details.
Note that the last column of coefficients always
represents the reference class. So when ref_class < n_classes, columns
ref_class and
n_classes are
swapped for the output coefficients, i.e.
coefficients for class n_classes will be returned
in column ref_class of coefficients. For
example, if ref_class = 1
and n_classes = 3,
the first column of coefficients contains
the coefficients for class 3 ( n_classes), the second
column contains the coefficients for class 2, and the third column contains all
zeros for the reference class.
Default: ref_classes=n_classes
IMSLS_NO_INTERCEPT
(Input)
If present, the model will not include an intercept
term.
Default: The intercept term is included.
IMSLS_X_INDICES, int n_xin, int xin[]
(Input)
An array of length n_xin providing the
column indices of x that correspond to
the independent variables the user wishes to be included in the logistic
regression model. For example, suppose there are five independent variables
x0, x1, …, x4. To fit a
model that includes only x2 and x3, set n_xin = 2,
xin[0] = 2,
and xin[1] = 3.
Default:
All n_independent
variables are included.
IMSLS_X_INTERACTIONS, int n_xinteract, int xinteract[]
(Input)
An array of length n_xinteract × 2 providing pairs of
column indices of x that define the
interaction terms in the model. Adjacent indices should be unique.
For example, suppose there are two independent variables x0 and x1. To fit a model
that includes their interaction term, x0x1, set n_xinteract = 1,
xinteract[0] = 0,
and xinteract[1] = 1.
Default:
No interaction terms are included.
IMSLS_TOLERANCE, float tolerance
(Input)
Convergence error criteria. Iteration completes when the
normed difference between successive estimates is less than tolerance or max_iter iterations
are reached.
Default: tolerance = 100.00*imsls_f_machine(4)
IMSLS_MAX_ITER, int max_iter
(Input)
The maximum number of iterations.
Default: max_iter = 20
IMSLS_INIT_INPUT, int init
(Input)
init must be 0 or 1.
If init = 1,
initial values for the coefficient estimates are provided in the user array
coefficients. If
init = 0,
initial values are computed by the function.
Default: init = 0
IMSLS_PREV_RESULTS,
Imsls_f_model
*prev_model
(Input)
Pointer to a structure of type Imsls_f_model containing
information about a previous logistic regression fit. The model is
combined with the fit to new data or to IMSLS_NEXT_RESULTS, if
provided.
IMSLS_NEXT_RESULTS,
Imsls_f_model
**next_model
(Input/Output)
Address of a pointer to a structure of type
Imsls_f_model. If present and NULL, the structure is
internally allocated and on output contains the model information. If
present and not NULL, its contents are
combined with the fit to new data or to IMSLS_PREV_RESULTS, if
provided. The combined results are returned in next_model.
IMSLS_COEFFICIENTS, float coefficients[]
(Input/Output)
Storage for the coefficient array of length n_coefficients × n_classes is provided
by the user. When init = 1,
coefficients
should contain the desired initial values of the estimates.
IMSLS_LRSTAT, float *lrstat
(Output)
The value of the likelihood ratio test statistic.
Description
Function imsls_f_logistic_regression
fits a logistic regression model for discrete dependent variables with two or
more mutually exclusive outcomes or classes. For a binary response y, the
objective is to model the conditional probability of success, π1 (x) = Pr[y = 1| x],
where x = (x1, x2, …, xp)′ is a realization of
p independent variables. Logistic regression models the conditional
probability, 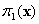 , using the cdf of the logistic
distribution. In particular,
, using the cdf of the logistic
distribution. In particular,
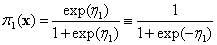
where
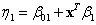
and
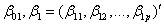
are unknown coefficients that are to be estimated.
Solving for the linear component η1 results in the log-odds or logit transformation of π1 (x):
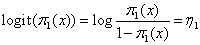
Given a set of N observations (yi, xi), where yi follows a binomial (n, π) distribution with parameters n = 1 and π = π1 (xi), the likelihood and log-likelihood are, respectively,
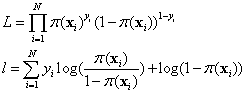
The log-likelihood in terms of the parameters, {β01, β1}, is therefore
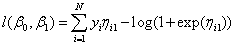
where
With a binary outcome, only one probability needs to be modeled. The second probability can be obtained from the constraint, π1 (x) + π2(x) = 1. If each yi is the number of successes in ni independent trials, the log-likelihood becomes
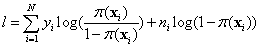
or
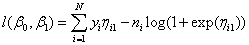
See optional argument IMSLS_FREQUENCIES to set frequencies ni > 1.
To test the significance of the model, the log-likelihood of the fitted model is compared to that of an intercept-only model. In particular, G = -2(l(β01) - l(β01, β1)) is a likelihood-ratio test statistic and under the null hypothesis, H0 : β11 = β12 = … = β1p = 0, G is distributed as chi-squared with p-1 degrees of freedom. A significant result suggests that at least one parameter in the model is non-zero. See Hosmer and Lemeshow (2000) for further discussion.
In the multinomial case, the response vector is yi = (yi1, yi2, …, yiK)′, where yik = 1 when the i-th observation belongs to class k and yik = 0, otherwise. Furthermore, because the outcomes are mutually exclusive,
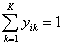
and π1 (x) + π2 (x) +--- + πK (x) = 1. The last class K serves as the baseline or reference class in the sense that it is not modeled directly but found from
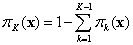
If there are multiple trials, ni > 1, then the constraint on the responses is
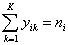
The log-likelihood in the multinomial case becomes
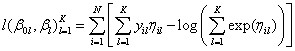
or
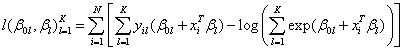
The constraint
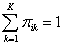
is handled by setting ηK = 0 for the K-th class, and then the log-likelihood is
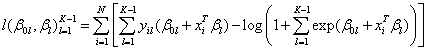
Note that for the multinomial case, the log-odds (or logit) is
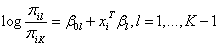
Note that each of the logits involve the odds ratio of being in class l versus class K, the reference class. Maximimum likelihood estimates can be obtained by solving the score equation for each parameter:
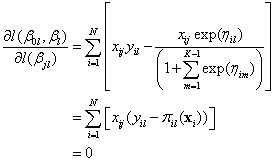
To solve the score equations, the function employs a method known as iteratively re-weighted least squares or IRLS. In this case the IRLS is equivalent to the Newton-Raphson algorithm (Hastie, et. al., 2009, Thisted, 1988).
Consider the full vector of parameters
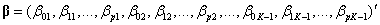
the Newton-Raphson iteration is
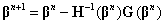
where H denotes the Hessian matrix, i.e., the matrix of second partial derivatives defined by
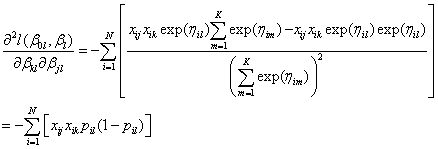
and
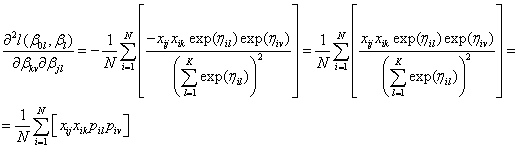
and G denotes the gradient vector, the vector of first partial derivatives,
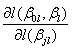
Both the gradient and the Hessian are evaluated at the most recent estimate of the parameters, βn. The iteration continues until convergence or until maximum iterations are reached. Following the theory of maximum likelihood estimation (Kendall and Stuart, 1979), standard errors are obtained from Fisher’s information matrix (-H)-1 evaluated at the final estimates.
When the IMSLS_NEXT_RESULTS option is specified, the function combines estimates of the same model from separate fits using the method presented in Xi, Lin, and Chen (2008). To illustrate, let β1 and β2 be the MLE’s from separate fits to two different sets of data, and let H1 and H2 be the associated Hessian matrices. Then the combined estimate,
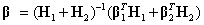
approximates the MLE of the combined data set. The model structure, Imsls_f_model **next_model contains the combined estimates as well as other elements. See Table 1: Imsls_f_model Data Structure below.
|
Parameter
|
Data Type |
Description |
|
n_obs |
int |
Total number of observations. If the model structure has been updated three times, first with 100 observations, next with 50, and third with 50, then n_obs = 200. |
|
n_updates |
int |
Total number of times the model structure has been updated. In the above scenario, n_updates = 3. |
|
n_coefs |
int |
Number of coefficients in the model. This parameter must be the same for each model update. |
|
coefs |
float[] |
An array of length n_coefs*n_classes containing the coefficients. |
|
meany |
float[] |
An array of length n_classes containing the overall means for each class variable. |
|
stderrs |
float[] |
An array of length n_coefs*(n_classes - 1) containing the estimated standard errors for the estimated coefficients. |
|
grad |
float[] |
An array of length n_coefs*(n_classes - 1) containing the estimated gradient at the coefficient estimates. |
|
hess |
float[] |
An array of length n_coefs*(n_classes - 1)*n_coefs*(n_classes - 1) containing the estimated hessian matrix at the coefficient estimates. |
Table 1 - The Imsls_f_model Data Structure
Remarks
Iteration stops when the estimates converge within tolerance, when maximum iterations are reached, or when the gradient becomes within tolerance of 0, whichever event occurs first. When the gradient converges before the coefficient estimate converges, a condition in the data known as complete or quasi-complete separation may be present. Separation in the data means that one or more independent variable perfectly predicts the response. When detected, the function stops the iteration, issues a warning, and returns the current values of the model estimates. Some of the coefficient estimates and standard errors may not be reliable. Furthermore, overflow issues may occur before the gradient converges. In such cases the program issues a fatal error.
Examples
Example 1
The first example is from Prentice (1976) and involves the mortality of beetles after five hours exposure to eight different concentrations of carbon disulphide. The table below lists the number of beetles exposed (N) to each concentration level of carbon disulphide (x, given as log dosage) and the number of deaths which result (y):
|
Log Dosage |
Number of Beetles Exposed |
Number of Deaths |
|
1.690 |
59 |
6 |
|
1.724 |
60 |
13 |
|
1.755 |
62 |
18 |
|
1.784 |
56 |
28 |
|
1.811 |
63 |
52 |
|
1.836 |
59 |
53 |
|
1.861 |
62 |
61 |
|
1.883 |
60 |
60 |
The number of deaths at each concentration level is the binomial response (n_classes = 2) and the log-dosage is the single independent variable. Note that this example illustrates the GROUP_COUNTS format for y and the optional argument IMSLS_FREQUENCIES.
#include <imsls.h>
int main(){
float y1[8]={6,13,18,28,52,53,61,60};
float x1[8]={1.69,1.724,1.755,1.784,1.811,1.836,1.861,1.883};
float freqs[8]={59,60,62,56,63,59,62,60};
float *coefs;
int n_classes=2,n_observations=8,n_independent=1,n_coefs=2;
coefs=imsls_f_logistic_regression(n_observations,
n_independent,n_classes,x1,y1,
IMSLS_GROUP_COUNTS,
IMSLS_FREQUENCIES,freqs,
0);
imsls_f_write_matrix("Coefficient Estimates",
(n_coefs)*(n_classes-1),1,coefs,0);
}
Output
Coefficient Estimates
1 -60.76
2 34.30
Example 2
In this example, the response is a multinomial random variable with 4 outcome classes. The 5 independent variables are simulated standard normal random variables. A subset of 2 independent variables along with the intercept defines the logistic regression model. A test of significance is performed.
#include <imsls.h>
#include <stdio.h>
int main(){
float x[50*3]={
3, 2, 2, 1, 3, 3, 3, 2, 3, 3, 3, 3, 3, 3, 2, 3, 2, 1, 3, 2,
2, 1, 2, 1, 3, 2, 1, 2, 1, 2, 3, 2, 1, 2, 1, 1, 2, 3, 1, 2,
1, 1, 1, 3, 1, 3, 2, 3, 3, 1,
25.92869, 51.63245, 25.78432, 39.37948, 24.65058, 45.20084,
52.6796, 44.28342, 40.63523, 51.76094, 26.30368, 20.70230,
38.74273, 19.47333, 26.42211, 37.05986, 51.67043, 42.40156,
33.90027, 35.43282, 44.30369, 46.72387, 46.99262, 36.05923,
36.83197, 61.66257, 25.67714, 39.08567, 48.84341, 39.34391,
24.73522, 50.55251, 31.34263, 27.15795, 31.72685, 25.00408,
26.35457, 38.12343, 49.9403, 42.45779, 38.80948, 43.22799,
41.87624, 48.0782, 43.23673, 39.41294, 23.93346,
42.8413, 30.40669, 37.77389,
1, 2, 1, 1, 1, 1, 2, 2, 2, 1, 1, 2, 2, 1, 1, 2, 2, 1, 2, 1,
1, 1, 1, 1, 2, 2, 1, 2, 2, 1, 1, 2, 2, 2, 1, 1, 2, 1, 1, 2,
2, 2, 1, 1, 2, 1, 1, 2, 1, 1
};
float y[50]={
1, 2, 3, 4, 3, 3, 4, 4, 4, 4, 2, 1, 4, 1, 1, 1, 4, 4, 3, 1,
2, 3, 3, 4, 2, 3, 4, 1, 2, 4, 3, 4, 4, 1, 3, 4, 4, 2, 3, 4,
2, 2, 4, 3, 1, 4, 3, 4, 2, 3
};
float *coefs,*preds,model_pval,lrstat;
int xindices[2],dof,n_classes=4,n_observations=50,
n_independent=3,n_coefs=3;
Imsls_f_model *model=NULL;
xindices[0]=0;
xindices[1]=1;
coefs=imsls_f_logistic_regression(n_observations,
n_independent,n_classes,x,y,
IMSLS_GROUPS,
IMSLS_X_INDICES,2,xindices,
IMSLS_LRSTAT,&lrstat,
IMSLS_NEXT_RESULTS,&model,0);
dof = n_coefs*(n_classes-1) - (n_classes-1);
model_pval = 1.0 - imsls_f_chi_squared_cdf(lrstat,dof);
imsls_f_write_matrix("Coefficients",(n_coefs)*(n_classes-1),
1,coefs,0);
imsls_f_write_matrix("Std Errs",n_coefs*(n_classes-1),1,
model->stderrs,0);
printf("\nLog-likelihood: %5.2f\n",model->loglike);
printf("LR test statistic: %5.2f\n%d deg. freedom, "
"p-value: %5.4f\n",lrstat,dof,model_pval,0);
}
Output
Coefficients
1 -0.6835
2 0.0715
3 -0.0971
4 -0.6228
5 0.0318
6 -0.0456
7 -0.4457
8 0.0145
9 -0.0105
Std Errs
1 0.5167
2 0.0454
3 0.0605
4 0.5040
5 0.0479
6 0.0555
7 0.4704
8 0.0415
9 0.0438
Log-likelihood: -64.76
LR test statistic: 4.00
6 deg.freedom,p-value: 0.6773
Example 3
Example 3 uses the same data as in Example 2 and an additional set of 50 observations using the same data generating process. The model structure includes all 3 independent variables and an intercept, and a single model fit is approximated from two separate model fits. Example 3 also includes a fit on the full data set for comparison purposes.
#include "imsls.h"
#include "stdio.h"
int main(){
float x1[50*3]={
3,2,2,1,3,3,3,2,3,3,3,3,3,3,2,3,2,1,3,2,2,1,2,1,3,2,
1,2,1,2,3,2,1,2,1,1,2,3,1,2,1,1,1,3,1,3,2,3,3,1,
25.92869,51.63245,25.78432,39.37948,24.65058,45.20084,
52.6796,44.28342,40.63523,51.76094,26.30368,20.70230,
38.74273,19.47333,26.42211,37.05986,51.67043,42.40156,
33.90027,35.43282,44.30369,46.72387,46.99262,36.05923,
36.83197,61.66257,25.67714,39.08567,48.84341,39.34391,
24.73522,50.55251,31.34263,27.15795,31.72685,25.00408,
26.35457,38.12343,49.9403,42.45779,38.80948,43.22799,
41.87624,48.0782,43.23673,39.41294,23.93346,
42.8413,30.40669,37.77389,
1,2,1,1,1,1,2,2,2,1,1,2,2,1,1,2,2,1,2,1,1,1,1,1,2,2,1,
2,2,1,1,2,2,2,1,1,2,1,1,2,2,2,1,1,2,1,1,2,1,1
};
float x2[50*3]={
1,1,3,3,2,3,3,3,2,1,1,1,1,3,3,2,2,3,3,2,3,2,1,3,3,2,2,
3,3,2,1,2,1,2,3,3,1,1,2,2,3,1,1,2,2,1,1,2,3,1,
35.66064,26.68771,23.11251,58.14765,44.95038,42.45634,
34.97379,53.54269,32.57257,46.91201,30.93306,51.63743,
34.67712,53.84584,14.97474,44.4485,47.10448,43.96467,
55.55741,36.63123,32.35164,55.75668,36.83637,46.7913,
44.24153,49.94011,41.91916,24.78584,50.79019,39.97886,
34.42149,41.93271,28.59433,38.47255,32.11676,37.19347,
52.89337,34.64874,48.61935,33.99104,38.32489,35.53967,
29.59645,21.14665,51.11257,34.20155,44.40374,49.67626,
58.35377,28.03744,
1,1,2,1,1,1,2,2,2,1,1,2,2,1,1,2,1,1,2,2,2,1,2,1,2,1,1,
2,2,2,2,2,2,2,2,1,1,1,2,1,2,2,1,1,2,1,1,2,1,1
};
float y1[50]={
1,2,3,4,3,3,4,4,4,4,2,1,4,1,1,1,4,4,3,1,2,3,3,4,2,
3,4,1,2,4,3,4,4,1,3,4,4,2,3,4,2,2,4,3,1,4,3,4,2,3
};
float y2[50]={
1,4,1,4,1,1,3,1,2,4,3,1,3,2,4,4,4,2,3,2,1,4,4,4,4,
3,1,1,3,1,4,2,4,2,1,2,3,1,1,4,1,2,4,3,4,2,4,3,2,4
};
float x3[100*3], y3[100], *coefs;
int i,j,n_classes=4,n_observations=50,
n_independent=3,n_coefs=4;
Imsls_f_model *model1=NULL,*model12=NULL,*model3=NULL;
/* first call with x1, y1 */
coefs=imsls_f_logistic_regression(n_observations,
n_independent,n_classes,x1,y1,
IMSLS_GROUPS,
IMSLS_COLUMN_WISE,
IMSLS_NEXT_RESULTS,&model1,0);
imsls_f_write_matrix("First Model Coefficients:",
n_coefs*(n_classes-1),1,model1->coefs,0);
imsls_f_write_matrix("First Model Standard Errors:",
n_coefs*(n_classes-1),1,model1->stderrs,0);
imsls_free(coefs);
/* second call with x2,y2 */
coefs=imsls_f_logistic_regression(n_observations,
n_independent,n_classes,x2,y2,
IMSLS_GROUPS,
IMSLS_COLUMN_WISE,
IMSLS_PREV_RESULTS,model1,
IMSLS_NEXT_RESULTS,&model12,0);
imsls_f_write_matrix("Combined Model Coefficients:",
n_coefs*(n_classes-1),1,model12->coefs,0);
imsls_f_write_matrix("Combined Model Standard Errors:",
n_coefs*(n_classes-1),1,model12->stderrs,0);
/* combine data */
for(j=0;j<n_independent;j++){
for(i=0;i<n_observations;i++){
y3[i]=y1[i];
y3[i+n_observations]=y2[i];
x3[i+j*2*n_observations]=x1[i+j*n_observations];
x3[i+j*2*n_observations+n_observations]=
x2[i+j*n_observations];
}
}
imsls_free(coefs);
coefs=imsls_f_logistic_regression(2*n_observations,
n_independent,n_classes,x3,y3,
IMSLS_GROUPS,
IMSLS_COLUMN_WISE,
IMSLS_NEXT_RESULTS,&model3,0);
imsls_f_write_matrix("Full Data Model Coefficients:",
n_coefs*(n_classes-1),1,model3->coefs,0);
imsls_f_write_matrix("Full Data Model Standard Errors:",
n_coefs*(n_classes-1),1,model3->stderrs,0);
}
Output
First Model Coefficients:
1 1.691
2 0.350
3 -0.137
4 1.057
5 -1.254
6 0.242
7 -0.004
8 0.115
9 1.032
10 0.278
11 0.016
12 -1.954
First Model Standard Errors:
1 2.389
2 0.565
3 0.061
4 1.025
5 2.197
6 0.509
7 0.047
8 0.885
9 2.007
10 0.461
11 0.043
12 0.958
Combined Model Coefficients:
1 -1.169
2 0.649
3 -0.038
4 0.608
5 -1.935
6 0.435
7 0.002
8 0.215
9 -0.193
10 0.282
11 0.002
12 -0.630
Combined Model Standard Errors:
1 1.489
2 0.359
3 0.029
4 0.588
5 1.523
6 0.358
7 0.030
8 0.584
9 1.461
10 0.344
11 0.030
12 0.596
Full Data Model Coefficients:
1 -1.009
2 0.640
3 -0.051
4 0.764
5 -2.008
6 0.436
7 0.003
8 0.263
9 -0.413
10 0.299
11 0.004
12 -0.593
Full Data Model Standard Errors:
1 1.466
2 0.350
3 0.029
4 0.579
5 1.520
6 0.357
7 0.029
8 0.581
9 1.389
10 0.336
11 0.028
12 0.577
Warning Errors
|
IMSLS_NO_CONV_SEP |
Convergence did not occur in # iterations. “tolerance” = #, the error between estimates = #, and the gradient has norm = #. Adjust “tolerance” or “max_iter”, or there may be a separation problem in the data. |
|
IMSLS_EMPTY_INT_RESULTS |
Intermediate results given to the function are empty and may be expected to be non-empty in this scenario. |
Fatal Errors
|
IMSLS_NO_CONV_OVERFLOW |
The linear predictor = # is too large and will lead to overflow when exponentiated. The algorithm fails to converge. |