 com.imsl.stat.CategoricalGenLinModel
com.imsl.stat.CategoricalGenLinModel
|
JMSLTM Numerical Library 5.0.1 | |||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | |||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | |||||||
java.lang.Object
public class CategoricalGenLinModel
Analyzes categorical data using logistic, probit, Poisson, and other linear models.
Reweighted least squares is used to compute (extended) maximum likelihood estimates in some generalized linear models involving categorized data. One of several models, including probit, logistic, Poisson, logarithmic, and negative binomial models, may be fit for input point or interval observations. (In the usual case, only point observations are observed.)
Let
![]()
x. When some of the
CategoricalGenLinModel, observations with potentially infinite
![]()
infin = 0. See below.
The models available in CategoricalGenLinModel are:
| Model Name | Parameterization | Response PDF |
| MODEL0 (Poisson) | ||
| MODEL1 (Negative Binomial) | ||
| MODEL2 (Logarithmic) | ||
| MODEL3 (Logistic) | ||
| MODEL4 (Probit) | ||
| MODEL5 (Log-log) |
Here ![]() denotes the cumulative normal
distribution, N and S are known parameters specified for each
observation via column
denotes the cumulative normal
distribution, N and S are known parameters specified for each
observation via column ipar of x, and w is
an optional fixed parameter specified for each observation via column
ifix of x. (By default N is
taken to be 1 for model = 0, 3, 4 and 5 and S is taken
to be 1 for model = 1. By default w
is taken to be 0.) Since the log-log model (model = 5)
probabilities are not symmetric with respect to 0.5, quantitatively, as well
as qualitatively, different models result when the definitions of "success"
and "failure" are interchanged in this distribution. In this model and all
other models involving ![]() ,
, ![]() is
taken to be the probability of a "success."
is
taken to be the probability of a "success."
Note that each row vector in the data matrix can represent a single
observation; or, through the use of column ifrq of the matrix
x, each vector can represent several observations. Also note
that classification variables and their products are easily incorporated
into the models via the usual regression-type specifications.
For interval observations, the probability of the observation is computed
by summing the probability distribution function over the range of values in
the observation interval. For right-interval observations, ![]() is computed as a sum based upon the equality
is computed as a sum based upon the equality ![]() . Derivatives are computed similarly.
. Derivatives are computed similarly.
CategoricalGenLinModel allows three types of
interval observations. In full interval observations, both the lower and the
upper endpoints of the interval must be specified. For right-interval
observations, only the lower endpoint need be given while for left-interval
observations, only the upper endpoint is given.
The computations proceed as follows:
ifrq of the
data matrix x. In binomial distribution models, the
frequency is taken as the product of n = x[i][ipar]
and x[i][ifrq]. In all cases these values default to 1.
Means are computed as
![]()
init = 0, initial estimates of the coefficients are
obtained (based upon the observation intervals) as multiple
regression estimates relating transformed observation probabilities
to the observation design vector. For example, in the binomial
distribution models, ![]()
model = 3, the linear relationship is given
by
![]()
model = 4,
![]()
x[i][irt]. Right-interval observations are not
used in obtaining initial estimates when the distribution has
unbounded support (since the midpoint of the interval is not
defined). When computing initial estimates, standard modifications
are made to prevent illegal operations such as division by zero.
Regression estimates are obtained at this point, as well as later, by use of linear regression.
![]()
![]()
![]()
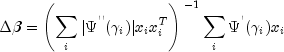
eps or when the relative change in the log-likelihood
from one iteration to the next is less than eps/100.
Convergence is also assumed after maxIterations or when
step halving leads to a step size of less than .0001 with no
increase in the log-likelihood.setInfiniteEstimateMethod set to 0, then the methods
of Clarkson and Jennrich (1991) are used to check for the existence
of infinite estimates in
![]()
x
is is such that ![]()
CategoricalGenLinModel, such estimates may be
"computed."
In all models fit by CategoricalGenLinModel
, infinite estimates can only occur when the optimal
estimated probability associated with the left- or right-censored
observation is 1. If setInfiniteEstimateMethod set to 0,
left- or right- censored observations that have estimated probability
greater than 0.995 at some point during the iterations are excluded
from the log-likelihood, and the iterations proceed with a log-likelihood
based upon the remaining observations. This allows convergence of
the algorithm when the maximum relative change in the estimated
coefficients is small and also allows for the determination of
observations with infinite
![]()
When setInfiniteEstimateMethod is set to 1, no
observations are eliminated during the iterations. In this case, when
infinite estimates occur, some (or all) of the coefficient estimates
![]() will become large, and it is likely
that the Hessian will become (numerically) singular prior to convergence.
will become large, and it is likely
that the Hessian will become (numerically) singular prior to convergence.
When infinite estimates for the ![]() are detected, linear regression (see Chapter 2, Regression;)
is used at the convergence of the algorithm to obtain unique
estimates
are detected, linear regression (see Chapter 2, Regression;)
is used at the convergence of the algorithm to obtain unique
estimates ![]() . This is accomplished by
regressing the optimal
. This is accomplished by
regressing the optimal ![]() or the
observations with finite
or the
observations with finite ![]() against
against
![]() , yielding a unique
, yielding a unique ![]() (by setting coefficients
(by setting coefficients ![]() that are linearly related to previous coefficients in
the model to zero). All of the final statistics relating to
that are linearly related to previous coefficients in
the model to zero). All of the final statistics relating to
![]() are based upon these estimates.
are based upon these estimates.
![]()
Following Cook and Weisberg (1982), we take the influence of the i-th observation to be
![]()
setClassificationVariableColumn. Indicator or dummy
variables are created for the classification variables.setModelIntercept is set to 1 and
(number of observations) - (number of rows in x missing
one or more values) > 1. In doing so, the sample means of the design
variables are subtracted from each observation prior to its inclusion in
the model. On convergence the intercept, its variance and its covariance
with the remaining estimates are transformed to the uncentered estimate
values.x[i][ifrq] contains the
frequency of the observation while x[i][irt] is 0 or 1
depending upon whether the observation is a success or failure. In
this case, N = x[i][ipar] is always 1. The model
is treated as repeated Bernoulli trials, and interval observations
are not possible.A second method for specifying binomial models is to use x[i][irt]
to represent the number of successes in the x[i][ipar]
trials. In this case, x[i][ifrq] will usually be 1, but it may
be greater than 1, in which case interval observations are possible.
Note that the solve method must be called prior to calling
the "get" member functions, otherwise a null is returned.
| Nested Class Summary | |
|---|---|
static class |
CategoricalGenLinModel.ClassificationVariableException
The ClassificationVariable vector has not been initialized. |
static class |
CategoricalGenLinModel.ClassificationVariableLimitException
The Classification Variable limit set by the user through
setUpperBound has been exceeded. |
static class |
CategoricalGenLinModel.ClassificationVariableValueException
The number of distinct values for each Classification Variable must be greater than 1. |
static class |
CategoricalGenLinModel.DeleteObservationsException
The number of observations to be deleted (set by setObservationMax)
has grown too large. |
| Field Summary | |
|---|---|
static int |
MODEL0
Indicates an exponential function is used to model the distribution parameter. |
static int |
MODEL1
Indicates a logistic function is used to model the distribution parameter. |
static int |
MODEL2
Indicates a logistic function is used to model the distribution parameter. |
static int |
MODEL3
Indicates a logistic function is used to model the distribution parameter. |
static int |
MODEL4
Indicates a probit function is used to model the distribution parameter. |
static int |
MODEL5
Indicates a log-log function is used to model the distribution parameter. |
| Constructor Summary | |
|---|---|
CategoricalGenLinModel(double[][] x,
int model)
Constructs a new CategoricalGenLinModel. |
|
| Method Summary | |
|---|---|
double[][] |
getCaseAnalysis()
Returns the case analysis. |
int[] |
getClassificationVariableCounts()
Returns the number of values taken by each classification variable. |
double[] |
getClassificationVariableValues()
Returns the distinct values of the classification variables in ascending order. |
double[][] |
getCovarianceMatrix()
Returns the estimated asymptotic covariance matrix of the coefficients. |
double[] |
getDesignVariableMeans()
Returns the means of the design variables. |
int[] |
getExtendedLikelihoodObservations()
Returns a vector indicating which observations are included in the extended likelihood. |
double[][] |
getHessian()
Returns the Hessian computed at the initial parameter estimates. |
double[] |
getLastParameterUpdates()
Returns the last parameter updates (excluding step halvings). |
int |
getNRowsMissing()
Returns the number of rows of data in x that contain
missing values in one or more specific columns of x. |
double |
getOptimizedCriterion()
Returns the optimized criterion. |
double[][] |
getParameters()
Returns the parameter estimates and associated statistics. |
double[] |
getProduct()
Returns the inverse of the Hessian times the gradient vector computed at the input parameter estimates. |
void |
setCensorColumn(int icen)
Sets the column number in x which contains the interval
type for each observation. |
void |
setClassificationVariableColumn(int[] indcl)
Initializes an index vector to contain the column numbers in x
that are classification variables. |
void |
setConvergenceTolerance(double eps)
Set the convergence criterion. |
void |
setEffects(int[] indef,
int[] nvef)
Initializes an index vector to contain the column numbers in x
associated with each effect. |
void |
setExtendedLikelihoodObservations(int[] iadds)
Initializes a vector indicating which observations are to be included in the extended likelihood. |
void |
setFixedParameterColumn(int ifix)
Sets the column number in x that contains a fixed parameter
for each observation that is added to the linear response prior to
computing the model parameter. |
void |
setFrequencyColumn(int ifrq)
Sets the column number in x that contains the frequency of
response for each observation. |
void |
setInfiniteEstimateMethod(int infin)
Sets the method to be used for handling infinite estimates. |
void |
setInitialEstimates(int init,
double[] estimates)
Sets the initial parameter estimates option. |
void |
setLowerEndpointColumn(int irt)
Sets the column number in x that contains the lower
endpoint of the observation interval for full interval and right
interval observations. |
void |
setMaxIterations(int maxIterations)
Set the maximum number of iterations allowed. |
void |
setModelIntercept(int intcep)
Sets the intercept option. |
void |
setObservationMax(int nmax)
Sets the maximum number of observations that can be handled in the linear programming. |
void |
setOptionalDistributionParameterColumn(int ipar)
Sets the column number in x that contains an optional
distribution parameter for each observation. |
void |
setUpperBound(int maxcl)
Sets the upper bound on the sum of the number of distinct values taken on by each classification variable. |
void |
setUpperEndpointColumn(int ilt)
Sets the column number in x that contains the upper
endpoint of the observation interval for full interval and left interval
observations. |
double[][] |
solve()
Returns the parameter estimates and associated statistics for a CategoricalGenLinModel object. |
| Methods inherited from class java.lang.Object |
|---|
clone, equals, finalize, getClass, hashCode, notify, notifyAll, toString, wait, wait, wait |
| Field Detail |
|---|
public static final int MODEL0
public static final int MODEL1
public static final int MODEL2
public static final int MODEL3
public static final int MODEL4
public static final int MODEL5
| Constructor Detail |
|---|
public CategoricalGenLinModel(double[][] x,
int model)
CategoricalGenLinModel.
x - A double input matrix containing the data where
the number of rows in the matrix is equal to the number of
observations.model - An int scalar which specifies the
distribution of the response variable and the function
used to model the distribution parameter. Use one of the
class members from the following table. The lower bound
given in the table is the minimum possible value of the
response variable:
| Model | Distribution | Function | Lower-bound |
| 0 | Poisson | Exponential | 0 |
| 1 | Negative Binomial | Logistic | 0 |
| 2 | Logarithmic | Logistic | 1 |
| 3 | Binomial | Logistic | 0 |
| 4 | Binomial | Probit | 0 |
| 5 | Binomial | Log-log | 0 |
| Name | Function |
| Exponential |
|
| Logistic | |
| Probit |
|
| Log-log |
| Method Detail |
|---|
public double[][] getCaseAnalysis()
double matrix containing the case analysis or
null if solve has not been called. The
matrix is | Column | Statistic |
| 0 | Prediction. |
| 1 | The residual. |
| 2 | The estimated standard error of the residual. |
| 3 | The estimated influence of the observation. |
| 4 | The standardized residual. |
| Model | Prediction |
| 0 | The predicted mean for the observation. |
| 1-4 | The probability of a success on a single trial. |
public int[] getClassificationVariableCounts()
throws CategoricalGenLinModel.ClassificationVariableException
int array of length nclvar containing the
number of values taken by each classification variable where
nclvar is the number of classification variables or
null if solve has not been called.
CategoricalGenLinModel.ClassificationVariableException - is thrown when the number of
values taken by each classification variable has been
set by the user to be less than or equal to 1
public double[] getClassificationVariableValues()
throws CategoricalGenLinModel.ClassificationVariableException
double array of length null is
returned if solve has not been called prior to calling
this method.
CategoricalGenLinModel.ClassificationVariableException - is thrown when the number of
values taken by each classification variable has been
set by the user to be less than or equal to 1public double[][] getCovarianceMatrix()
double matrix containing the estimated asymptotic
covariance matrix of the coefficients or null if solve
has not been called. The covariance matrix is
nCoef by nCoef where nCoef is the number of
coefficients in the model.public double[] getDesignVariableMeans()
double array of length nCoef containing
the means of the design variables where nCoef is the
number of coefficients in the model or null if solve
has not been called.public int[] getExtendedLikelihoodObservations()
int array of length nobs indicating which
observations are included in the extended likelihood where
nobs is the number of observations. The values within the
array are interpreted as:
| Value | Status of observation |
|---|---|
| 0 | Observation i is in the likelihood. |
| 1 | Observation i cannot
be in the likelihood because it contains at least one
missing value in x. |
| 2 | Observation i is not in the likelihood. Its estimated parameter is infinite. |
null is returned if solve has not been called
prior to calling this method.
public double[][] getHessian()
throws CategoricalGenLinModel.ClassificationVariableException,
CategoricalGenLinModel.ClassificationVariableLimitException,
CategoricalGenLinModel.ClassificationVariableValueException,
CategoricalGenLinModel.DeleteObservationsException
double matrix containing the Hessian computed at
the input parameter estimates. The Hessian matrix is nCoef
by nCoef where nCoef is the number of
coefficients in the model. This member function will call solve
to get the Hessian if the Hessian has not already been computed.
CategoricalGenLinModel.ClassificationVariableException - is thrown when the number of
values taken by each classification variable has been
set by the user to be less than or equal to 1
CategoricalGenLinModel.ClassificationVariableLimitException - is thrown when the
sum of the number of distinct values taken on by each
classification variable exceeds the maximum allowed,
maxcl
CategoricalGenLinModel.DeleteObservationsException - is thrown if the number of
observations to be deleted has grown too large
CategoricalGenLinModel.ClassificationVariableValueExceptionpublic double[] getLastParameterUpdates()
double array of length nCoef containing
the last parameter updates (excluding step halvings) or null
if solve has not been called.public int getNRowsMissing()
x that contain
missing values in one or more specific columns of x.
int scalar representing the number of rows of
data in x that contain missing values in one or
more specific columns of x or null if
solve has not been called. The columns of x
included in the count are the columns containing the
upper or lower endpoints of full interval, left interval, or
right interval observations. Also included are the columns
containing the frequency responses, fixed parameters, optional
distribution parameters, and interval type for each observation.
Columns containing classification variables and columns
associated with each effect in the model are also included.public double getOptimizedCriterion()
double scalar representing the optimized
criterion or null if solve has not been
called. The criterion to be maximized is a constant plus the
log-likelihood.public double[][] getParameters()
nCoef row by 4 column double matrix containing the parameter
estimates and associated statistics or null if
solve has not been called. Here, nCoef is
the number of coefficients in the model. The statistics returned
are as follows:
| Column | Statistic |
| 0 | Coefficient estimate. |
| 1 | Estimated standard deviation of the estimated coefficient. |
| 2 | Asymptotic normal score for testing that the coefficient is zero. |
| 3 |
public double[] getProduct()
throws CategoricalGenLinModel.ClassificationVariableException,
CategoricalGenLinModel.ClassificationVariableLimitException,
CategoricalGenLinModel.ClassificationVariableValueException,
CategoricalGenLinModel.DeleteObservationsException
double array of length nCoef containing
the inverse of the Hessian times the gradient vector computed at
the input parameter estimates. nCoef is the number of
coefficients in the model. This member function will call solve
to get the product if the product has not already been computed.
CategoricalGenLinModel.ClassificationVariableException - is thrown when the number of
values taken by each classification variable has been
set by the user to be less than or equal to 1
CategoricalGenLinModel.ClassificationVariableLimitException - is thrown when the
sum of the number of distinct values taken on by each
classification variable exceeds the maximum allowed,
maxcl
CategoricalGenLinModel.DeleteObservationsException - is thrown if the number of
observations to be deleted has grown too large
CategoricalGenLinModel.ClassificationVariableValueExceptionpublic void setCensorColumn(int icen)
x which contains the interval
type for each observation.
icen - An int scalar which indicates the column
number x which contains the interval
type code for each observation. The valid codes are
interpreted as:
x[i][icen] |
Censoring |
| 0 | Point observation.
The response is unique and is given by
x[i][irt]. |
| 1 | Right interval. The
response is greater than or equal to
x[i][irt] and less than or equal to the
upper bound, if any, of the distribution. |
| 2 | Left interval. The
response is less than or equal to
x[i][ilt] and greater than or equal to
the lower bound of the distribution. |
| 3 | Full interval. The
response is greater than or equal to
x[i][irt] but less than or equal to
x[i][ilt]. |
IllegalArgumentException - is thrown when icen
is less than 0 or greater than or equal to the number of
columns of xpublic void setClassificationVariableColumn(int[] indcl)
x
that are classification variables.
indcl - An int vector which contains the column
numbers in x that are classification
variables. By default this vector is not referenced.
IllegalArgumentException - is thrown when an element of
indcl is less than 0 or greater than or
equal to the number of columns of xpublic void setConvergenceTolerance(double eps)
eps - A double scalar specifying the convergence
criterion. Convergence is assumed when the maximum relative
change in any coefficient estimate is less than eps
from one iteration to the next or when the relative
change in the log-likelihood, getOptimizedCriterion, from one
iteration to the next is less than eps/100. eps
must be greater than 0. If this member function is not called,
eps = .001 is assumed.
IllegalArgumentException - is thrown if eps is
or equal to 0
public void setEffects(int[] indef,
int[] nvef)
x
associated with each effect.
indef - An int vector of length indef contains the column numbers in
x that are associated with each effect.
Member function setEffects(int [], nvef [])
sets the number of variables associated with each effect
in the model. The first nvef[0]
elements of indef give the column numbers
of the variables in the first effect. The next
nvef[0] elements give the column numbers of the
variables in the second effect, etc. By default this
vector is not referenced.nvef - An int vector of length nef
where nef is the number of effects in the
model. nvef contains the number of
variables associated with each effect in the model. By
default this vector is not referenced.
IllegalArgumentException - is thrown when an element of
indef is less than 0 or greater than or
equal to the number of columns of x or if
an element of nvef is less than or equal to
0public void setExtendedLikelihoodObservations(int[] iadds)
iadds - An int array of length nobs
indicating which observations are included in the
extended likelihood where nobs is the number of
observations. The values within the array are
interpreted as:
| Value | Status of observation |
|---|---|
| 0 | Observation i is in the likelihood. |
| 1 | Observation i
cannot be in the likelihood because it
contains at least one missing value in x
. |
| 2 | Observation i is not in the likelihood. Its estimated parameter is infinite. |
iadds
is set to all zeroes.
IllegalArgumentException - is thrown when an element of
iadds is not in the range [0,2]public void setFixedParameterColumn(int ifix)
x that contains a fixed parameter
for each observation that is added to the linear response prior to
computing the model parameter.
ifix - An int scalar which indicates the column
number in x that contains a fixed parameter
for each observation that is added to the linear
response prior to computing the model parameter. The
"fixed" parameter allows one to test hypothesis about
the parameters via the log-likelihoods. By default the
fixed parameter is assumed to be zero.
IllegalArgumentException - is thrown when ifix
is less than 0 or greater than or equal to the number of
columns of xpublic void setFrequencyColumn(int ifrq)
x that contains the frequency of
response for each observation.
ifrq - An int scalar which indicates the column
number in x that contains the frequency of
response for each observation. By default a frequency of
1 for each observation is assumed.
IllegalArgumentException - is thrown when ifrq
is less than 0 or greater than or equal to the number of
columns of xpublic void setInfiniteEstimateMethod(int infin)
infin - An int scalar which indicates the method to
be used for handling infinite estimates. The method
value is interpreted as follows:
infin | Method |
| 0 | Remove a right or
left-censored observation from the
log-likelihood whenever the probability of the
observation exceeds 0.995. At convergence, use
linear programming to check that all removed
observations actually have an estimated linear
response that is infinite. Set iadds[i]
for observation i to 2 if the
linear response is infinite. If not all removed
observations have infinite linear response,
recompute the estimates based upon the
observations with estimated linear response that
is finite. This option is valid only for
censoring codes 1 and 2. |
| 1 | Iterate without checking for infinite estimates. |
infin = 1.
IllegalArgumentException - is thrown when infin
is less than 0 or greater than 1
public void setInitialEstimates(int init,
double[] estimates)
init - An input int indicating the desired
initialization method for the initial estimates of the
parameters. If this method is not called, init
is set to 0.
init | Action |
| 0 | Unweighted linear regression is used to obtain initial estimates. |
| 1 | The nCoef,
number of coefficients, elements of estimates contain
initial estimates of the parameters. Use of this
option requires that the user know nCoef
beforehand. |
estimates - An input double array of length
nCoef containing the initial estimates of the
parameters where nCoef is the number of
estimated coefficients in the model. (Used if
init = 1.) If this member function is not
called, unweighted linear regression is used to
obtain the initial estimates.
IllegalArgumentException - is thrown when init
is not in the range [0,1]public void setLowerEndpointColumn(int irt)
x that contains the lower
endpoint of the observation interval for full interval and right
interval observations.
irt - An int scalar which indicates the column number
in x that contains the lower endpoint of the
observation interval for full interval and right interval
observations. By default all observations are treated as
"point" observations and x[i][irt] contains the
observation point. If this member function is not called,
the last column of x is assumed to contain the
"point" observations.
IllegalArgumentException - is thrown when irt
is less than 0 or greater than or equal to the number of
columns of xpublic void setMaxIterations(int maxIterations)
maxIterations - An int specifying the maximum
number of iterations allowed. maxIterations
must be greater than 0. If this member function is
not called, the maximum number of iterations is set to 30.
IllegalArgumentException - is thrown if maxIterations is
less than or equal to 0public void setModelIntercept(int intcep)
intcep - An int scalar which indicates whether or
not the model has an intercept. Input intcep
is interpreted as follows:
| Value | Action |
| 0 | No intercept is in the model (unless otherwise provided for by the user). |
| 1 | Intercept is automatically included in the model. |
intcep = 1.
IllegalArgumentException - is thrown when intcep
is less than 0 or greater than 1public void setObservationMax(int nmax)
nmax - An int scalar which sets the maximum number
of observations that can be handled in the linear
programming. An illegal argument exception is thrown if
nmax is less than 0. If this member
function is not called, nmax is set to the
number of observations.
IllegalArgumentException - is thrown when nmax
is less than 0public void setOptionalDistributionParameterColumn(int ipar)
x that contains an optional
distribution parameter for each observation.
ipar - An int scalar which indicates the column
number in x that contains an optional
distribution parameter for each observation. The
distribution parameter values are interpreted as follows
depending on the model chosen:
| Model | Meaning of x[i][ipar]
|
|---|---|
| 0 | The Poisson
parameter is given by |
| 1 | The number of
successes required in the negative binomial is
given by x[i][ipar]. |
| 2 | x[i][ipar] is
not used. |
| 3-5 | The number of
trials in the binomial distribution is given by
x[i][ipar]. |
IllegalArgumentException - is thrown when ipar is
less than 0 or greater than or equal to the number of
columns of xpublic void setUpperBound(int maxcl)
maxcl - An int scalar specifying the upper bound on
the sum of the number of distinct values taken on by
each classification variable. If this member function is
not called, an upper bound of 1 is used if method
setClassificationVariableColumn has not been
referenced. Otherwise, the default upper bound is set to
nobs * nclvar where nobs is the
number of observations and nclvar is the number
of classification variables.
IllegalArgumentException - is thrown when maxcl
is less than 1 and the number of classification
variables is greater than 0public void setUpperEndpointColumn(int ilt)
x that contains the upper
endpoint of the observation interval for full interval and left interval
observations.
ilt - An int scalar which indicates the column number
in x that contains the upper endpoint of the
observation interval for full interval and left interval
observations. By default all observations are treated as
"point" observations.
IllegalArgumentException - is thrown when ilt is less than
0 or greater than or equal to the number of columns of
x
public double[][] solve()
throws CategoricalGenLinModel.ClassificationVariableException,
CategoricalGenLinModel.ClassificationVariableLimitException,
CategoricalGenLinModel.ClassificationVariableValueException,
CategoricalGenLinModel.DeleteObservationsException
nCoef row by 4 column double matrix containing the parameter
estimates and associated statistics. Here, nCoef is the number of coefficients
in the model. The statistics returned are as follows:
| Column | Statistic |
| 0 | Coefficient estimate. |
| 1 | Estimated standard deviation of the estimated coefficient. |
| 2 | Asymptotic normal score for testing that the coefficient is zero. |
| 3 |
CategoricalGenLinModel.ClassificationVariableException - is thrown when the number of
values taken by each classification variable has been
set by the user to be less than or equal to 1
CategoricalGenLinModel.ClassificationVariableLimitException - is thrown when the
sum of the number of distinct values taken on by each
classification variable exceeds the maximum allowed,
maxcl
CategoricalGenLinModel.DeleteObservationsException - is thrown if the number of
observations to be deleted has grown too large
CategoricalGenLinModel.ClassificationVariableValueException
|
JMSLTM Numerical Library 5.0.1 | |||||||
| PREV CLASS NEXT CLASS | FRAMES NO FRAMES | |||||||
| SUMMARY: NESTED | FIELD | CONSTR | METHOD | DETAIL: FIELD | CONSTR | METHOD | |||||||