- java.lang.Object
-
- com.imsl.stat.KaplanMeierEstimates
-
- All Implemented Interfaces:
- Serializable, Cloneable
public class KaplanMeierEstimates extends Object implements Serializable, Cloneable
Computes Kaplan-Meier (or product-limit) estimates of survival probabilities for a sample of failure times that possibly contain right consoring.Class
KaplanMeierEstimatescomputes Kaplan-Meier (or product-limit) estimates of survival probabilities for a sample of failure times that can be right censored or exact times. A survival probability S(t) is defined as 1 - F(t), where F(t) is the cumulative distribution function of the failure times t. Greenwood's estimate of the standard errors of the survival probability estimates are also computed. (See Kalbfleisch and Prentice, 1980, pages 13 and 14.)Let (
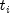 ,
, 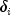 ), for i = 1,..., n
denote the failure censoring times and the censoring codes for the n observations
in a single sample. Here,
), for i = 1,..., n
denote the failure censoring times and the censoring codes for the n observations
in a single sample. Here, 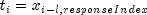 is a failure time if
is a failure time if
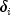 is 0, where
is 0, where 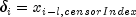 .
Also,
.
Also, 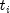 is a right censoring time if
is a right censoring time if 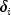 is 1.
Rows in
is 1.
Rows in xcontaining values other than 0 or 1 for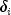 are
ignored. Let the number of observations in the sample that have not failed by time
are
ignored. Let the number of observations in the sample that have not failed by time
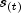 be denoted by
be denoted by 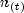 , where
, where 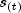 is an ordered (from smallest to largest) listing of the distinct failure times (censoring
times are omitted). Then the Kaplan-Meier estimate of the survival probabilities is
a step function, which in the interval from
is an ordered (from smallest to largest) listing of the distinct failure times (censoring
times are omitted). Then the Kaplan-Meier estimate of the survival probabilities is
a step function, which in the interval from 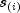 to
to 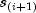 (including the lower endpoint) is given by
(including the lower endpoint) is given by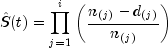
where
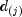 denotes the number of failures occurring at time
denotes the number of failures occurring at time 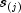 ,
and
,
and 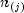 is the number of observations that have not failed
prior to
is the number of observations that have not failed
prior to 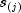 .
.Note that one row of
xmay correspond to more than one failed (or censored) observation when the frequency option is in effect (seesetFrequencyColumn). The Kaplan-Meier estimate of the survival probability prior to time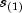 is 1.0, while the Kaplan-Meier estimate of the survival probability after the
last failure time is not defined.
is 1.0, while the Kaplan-Meier estimate of the survival probability after the
last failure time is not defined.Greenwood's estimate of the variance of
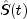
in the interval from
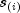 to
to 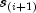 is given as
is given as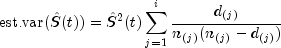
KaplanMeierEstimatescomputes the single sample estimates of the survival probabilities for all samples of data included inxduring a single call. This is accomplished through the stratum column ofx, which if present, must contain a distinct code for each sample of observations (seesetStratumColumn). If a stratum column is not specified, there is no grouping , and all observations are assumed to come from the same sample.When failures and right-censored observations are tied and the data are to be sorted by
KaplanMeierEstimates(setSorted(true)is not used),KaplanMeierEstimatesassumes that the time of censoring for the tied-censored observations is immediately after the tied failure (within the same sample). WhensetSorted(true)is used, the data are assumed to be sorted from smallest to largest according to the response time column ofxwithin each stratum (seesetResponseColumn). Furthermore, a small increment of time is assumed (theoretically) to elapse between the failed and censored observations that are tied (in the same sample). Thus, whensetSorted(true)is used, the user must sort all of the data inxfrom smallest to largest according to the response time column (and the stratum column, if set). By appropriate sorting of the observations, the user can handle censored and failed observations that are tied in any manner desired.- See Also:
- Example , Serialized Form
-
-
Constructor Summary
Constructors Constructor and Description KaplanMeierEstimates(double[][] x)Constructor forKaplanMeierEstimates.
-
Method Summary
Methods Modifier and Type Method and Description intgetCensorColumn()Returns the column index ofxcontaining the optional censoring code for each observation.intgetFrequencyColumn()Returns the column index ofxcontaining the frequency of response for each observation.intgetGroupTotal(double groupValue)Returns the total number in the group for the specified group value.doublegetLogLikelihood(double groupValue)Returns the Kaplan-Meier log-likelihood of the group with the specified group value.int[]getNumberAtRisk()Returns the number of individuals at risk at each failure point.int[]getNumberOfFailures()Returns the number of failures which occurred at each failure point.intgetNumberOfRowsMissing()Returns the number of rows of data inxthat contain missing values in one or more specific columns ofx.intgetResponseColumn()Returns the column index ofxcontaining the response time for each observation.double[]getStandardErrors()Returns Greenwood's estimated standard errors.intgetStratumColumn()Returns the column index ofxcontaining the stratum number for each observation.double[]getSurvivalProbabilities()Returns the estimated survival probabilities.intgetTotalNumberOfFailures(double groupValue)Returns the total number failing in the group for the specified group value.voidsetCensorColumn(int censorIndex)Sets the column index ofxcontaining the optional censoring code for each observation.voidsetFrequencyColumn(int frequencyIndex)Sets the column index ofxcontaining the frequency of response for each observation.voidsetResponseColumn(int responseIndex)Sets the column index ofxcontaining the response time for each observation.voidsetSorted(boolean isSorted)Sets thebooleanto indicate that the column of response times inxare already sorted.voidsetStratumColumn(int stratumIndex)Sets the column index ofxcontaining the stratum number for each observation.
-
-
-
Constructor Detail
-
KaplanMeierEstimates
public KaplanMeierEstimates(double[][] x)
Constructor forKaplanMeierEstimates.- Parameters:
x- adoublematrix containing the data, including optional data. By default it is assumed the response times are in column 0.
-
-
Method Detail
-
getCensorColumn
public int getCensorColumn()
Returns the column index ofxcontaining the optional censoring code for each observation.- Returns:
- an
intspecifying the column index ofxcontaining the optional censoring code for each observation.
-
getFrequencyColumn
public int getFrequencyColumn()
Returns the column index ofxcontaining the frequency of response for each observation.- Returns:
- an
intspecifying the column index ofxcontaining the frequency of response for each observation.
-
getGroupTotal
public int getGroupTotal(double groupValue)
Returns the total number in the group for the specified group value.- Parameters:
groupValue- adoublespecifying the group value.- Returns:
- an
intrepresenting the total number in the group which has valuegroupValue.
-
getLogLikelihood
public double getLogLikelihood(double groupValue)
Returns the Kaplan-Meier log-likelihood of the group with the specified group value.The Kaplan-Meier log-likelihood is computed as:
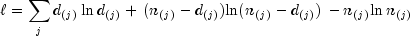
where the sum is with respect to the distinct failure times
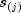 .
.- Parameters:
groupValue- adoublespecifying the group value.- Returns:
- a
doublerepresenting the Kaplan-Meier log-likelihood of the group which has valuegroupValue.
-
getNumberAtRisk
public int[] getNumberAtRisk()
Returns the number of individuals at risk at each failure point.- Returns:
- an
intarray containing the number of individuals at risk at each failure point.
-
getNumberOfFailures
public int[] getNumberOfFailures()
Returns the number of failures which occurred at each failure point.- Returns:
- an
intarray containing the number of failures which occurred at each failure point.
-
getNumberOfRowsMissing
public int getNumberOfRowsMissing()
Returns the number of rows of data inxthat contain missing values in one or more specific columns ofx.- Returns:
- an
intscalar representing the number of rows of data inxthat contain missing values in one or more specific columns ofx.
-
getResponseColumn
public int getResponseColumn()
Returns the column index ofxcontaining the response time for each observation.- Returns:
- an
intspecifying the column index ofxcontaining the response time for each observation.
-
getStandardErrors
public double[] getStandardErrors()
Returns Greenwood's estimated standard errors.- Returns:
- a
doublearray containing Greenwood's estimate of the standard errors for the survival probabilities.
-
getStratumColumn
public int getStratumColumn()
Returns the column index ofxcontaining the stratum number for each observation.- Returns:
- an
intspecifying the column index ofxcontaining the stratum number for each observation.
-
getSurvivalProbabilities
public double[] getSurvivalProbabilities()
Returns the estimated survival probabilities.- Returns:
- a
doublearray containing the estimated survival probabilities.
-
getTotalNumberOfFailures
public int getTotalNumberOfFailures(double groupValue)
Returns the total number failing in the group for the specified group value.- Parameters:
groupValue- adoublespecifying the group value.- Returns:
- an
intrepresenting the total number failing in the group which has valuegroupValue.
-
setCensorColumn
public void setCensorColumn(int censorIndex)
Sets the column index ofxcontaining the optional censoring code for each observation.- Parameters:
censorIndex- anintspecifying the column index ofxcontaining the optional censoring code for each observation. Ifx[i][censorIndex]equals 0, the failure timex[i][responseIndex]is treated as an exact time of failure. Otherwise, it is treated as right-censored time. Default: It is assumed that there is no censor code column inx. All observations are assumed to be exact failure times.
-
setFrequencyColumn
public void setFrequencyColumn(int frequencyIndex)
Sets the column index ofxcontaining the frequency of response for each observation.- Parameters:
frequencyIndex- anintspecifying the column index ofxcontaining the frequency of response for each observation. Default: It is assumed that there is no frequency response column recorded inx. Each observation in the data array is assumed to be for a single failure.
-
setResponseColumn
public void setResponseColumn(int responseIndex)
Sets the column index ofxcontaining the response time for each observation.- Parameters:
responseIndex- anintspecifying the column index ofxcontaining the response time for each observation. The interpretation of these times as either right-consored or exact failure times depends on the setting of the censor codes in the censor code column. See methodsetCensorColumn. Default:responseIndex = 0.
-
setSorted
public void setSorted(boolean isSorted)
Sets thebooleanto indicate that the column of response times inxare already sorted.- Parameters:
isSorted- abooleanindicating whether or not columnresponseIndexofxis already sorted.isSortedequal totrueindicates that columnresponseIndexofxis already sorted. Otherwise, a detached sort is performed prior to analysis. If sorting is performed, all censored individuals are assumed to follow tied failures. Default: It is assumed that columnresponseIndexofxis not sorted, so a detached sort is performed.
-
setStratumColumn
public void setStratumColumn(int stratumIndex)
Sets the column index ofxcontaining the stratum number for each observation.- Parameters:
stratumIndex- anintspecifying the column index ofxcontaining the stratum number for each observation. ColumnstratumIndexofxcontains a unique value for each stratum in the data. Kaplan-Meier estimates are computed within each stratum. Default: It is assumed that there is no stratum number column recordedx. The data is assumed to come from one statum.
-
-