mlffClassificationTrainer¶

Trains a multilayered feedforward neural network for classification.
Synopsis¶
mlffClassificationTrainer (network, classification, nominal, continuous)
Required Arguments¶
- Imsls_d_NN_Network
network(Input/Output) - A Imsls_d_NN_Network containing the feedforward network’s architecture,
including network weights and bias values. For more details, see
mlffNetwork. When network training is
successful, the weights and bias values in
networkare replaced with the values calculated for the optimum trained network. - int
classification[](Input) - Array of size
nPatternscontaining the target classifications for the training patterns. These must be numbered sequentially from 0 to nClasses-1, where nClasses is the number of target categories. For binary classification problems, nClasses= 2. For other problems, nClasses=nOutputs=network.n_outputs. For more details, see mlffNetwork. - int
nominal[[]](Input) - Array of size
nPatternsbynNominalcontaining values for the nominal input attributes. The i-th row contains the nominal input attributes for the i-th training pattern. IfnNominal = 0, this argument is ignored. - float
continuous[[]](Input) - Array of size
nPatternsbynContinuouscontaining values for the continuous input attributes. The i-th row contains the continuous input attributes for the i-th training pattern. IfnContinuous = 0, this argument is ignored.
Return Value¶
An array of training statistics, containing six summary statistics from the classification neural network, organized as follows:
| Element | Training Statistics |
|---|---|
| 0 | Minimum Cross-Entropy at the optimum. |
| 1 | Total number of Stage I iterations. |
| 2 | Minimum Cross-Entropy after Stage I training. |
| 3 | Total number of Stage II iterations. |
| 4 | Minimum Cross-Entropy after Stage II training. |
| 5 | Classification error rate from optimum network. |
The classification error rate is calculated using the ratio
nErrors/nPatterns, where nErrors is the number of patterns that
are incorrectly classified using the trained neural network. For each
training pattern, the probability that it belongs to each of the target
classes is calculated from the trained network. A pattern is considered
incorrectly classified if the classification probability for its target
classification is not the largest among that pattern’s classification
probabilities.
A classification error of zero indicates that all training patterns are correctly classified into their target classifications. A value near one indicates that most patterns are not classified into their target classification.
If training is unsuccessful, None is returned.
Optional Arguments¶
stageI, intnEpochs, intepochSize(Input)Argument
nEpochsis the number epochs used for Stage I training and argumentepochSizeis the number of observations used during each epoch. If epoch training is not needed, setepochSize=nPatternsandnEpochs=1. Stage I training is implemented using steepest ascent optimization and backward propagation for gradient calculations.Default:
nEpochs=15,epochSize=nPatterns.noStageII, (Input)Specifies no Stage II training is needed. Stage II training is implemented using Quasi-Newton optimization with numerical gradients.
Default: Stage II training is performed.
maxStep, float (Input)Maximum allowable step size in the optimizer.
Default:
maxStep= 10.maxItn, int (Input)Maximum number of iterations in the optimizer, per epoch.
Default:
maxIterations=1000.maxFcn, int (Input)Maximum number of function evaluations in the optimizer, per epoch.
Default:
maxFcn=1000.relFcnTol, float (Input)Relative function tolerance in the optimizer.
Default:
relFcnTol= max \((10^{-10}\), \(\varepsilon^{2/3}\)), where ɛ is the machine precision.gradTol, float (Input)Scaled gradient tolerance in the optimizer.
Default:
gradTol= \(\varepsilon^{1/2}\), where ɛ is the machine precision.tolerance, float (Input)Absolute accuracy tolerance for the entropy. If the network entropy for an epoch during Stage I training falls below
tolerance, the network is considered optimized, training is halted and the network with the minimum entropy is returned.Default:
tolerance=\(\varepsilon^{1/3}\), where ɛ is the machine precision.t_print(Input)Intermediate results are printed during network training.
Default: No printing is performed.
weightInitializationMethod, int (Input)The method to use for initializing network weights prior to network training. One of the following five values is accepted:
weightInitializationMethodAlgorithm EQUALEqual weights. RANDOMRandom weights. PRINCIPAL_COMPONENTSPrincipal Component Weights. DISCRIMINANTDiscriminant Analysis Weights. NN_NETWORKNo initialization method will be performed. Weights in Imsls_d_NN_Network structure networkwill be used instead.Default: method =
RANDOM.logisticTable, (Input)If this option is selected, during Stage I optimization all logistic activation functions in the hidden layers are calculated using a table lookup approximation to the logistic function. This reduces the time for Stage I training with logistic activation. However, during Stage II optimization this setting is ignored.
Default: All logistic activations are calculated without table lookup.
predictedClass(Output)- An array of size
nPatternscontaining the predicted classification for each training pattern. gradient(Output)- An array of size
network.n_links + network.n_nodes - network.n_inputscontaining the gradients for each weight in the optimum network. predictedClassProb(Output)- An array of size
nPatternsby nClasses, where nClasses is the number of target classes in the network. For binary classification problems, \(nClasses=2\), but for all other problems nClasses= nOutputs, wherenOutputsis the number of outputs in the network,network.n_outputs. The values of the i-th row are the predicted probabilities associated with the target classes. For binary classification,predictedClassProb[i]is the predicted probability that the i-th pattern is associated withclass= 0. For other classification problems values in the i-th row ofpredictedClassProbare the predicted probabilities that this pattern belongs to each of the target classes. classError(Output)- An array with
nPatternscontaining the classification probability errors for each pattern in the training data. The classification error for the i-th training pattern is equal to1-predictedClass[k]wherek=classification[i].
Description¶
Function mlffClassificationTrainer trains a multilayered feedforward
neural network for classifying patterns. It returns training summaries, the
classification probabilities associated with training patterns, their
classification errors, the optimum network weights and gradients. Linkages
among perceptrons allow for skipped layers, including linkages between
inputs and output perceptrons. Except for output perceptrons, the linkages
and activation function for each perceptron can be individually configured.
For more details, see optional arguments linkAll, linkLayer, and
linkNode in mlffNetwork.
Binary classification is handled differently from classification problems
involving more than two classes. Binary classification problems only have
two target classes, which must be coded as either zero or one. This is
represented using a single network output with logistic activation. The
output is an estimate of the probability that the pattern belongs to class
= 0. The probability associated with class = 1 can be calculated
from the relationship P(class = 1) = 1-
P(class = 0).
Networks designed to classify patterns into more than two categories use one
output for each target class, i.e., nClasses = nOutputs. The first
output predicts P(class = 0), the second
P(class = 1), etc. All output perceptrons are normalized
using softmax activation. This ensures that the estimated class
probabilities are between zero and one, and that they always sum to one.
Training Patterns¶
Neural network training patterns consist of the following three types of data:
- nominal input attributes
- continuous input attributes, including encoded ordinal attributes,
- pattern classifications numbered 0, 1, …,
nClasses-1
The first data type, nominal data, contains the encoding of nominal input attributes, if any. Nominal input attributes must be encoded into multiple columns for network input. Although not required, binary encoding is typically used to create these input columns. Binary encoding consists of creating columns of zeros and ones for each class value associated with every nominal attribute. If only one attribute is used for input, then the number of columns is equal to the number of classes for that attribute. If several nominal attributes appear in the data, then each attribute is associated with several columns, one for each of its classes.
The unsupervisedNominalFilter can be used to generate these columns. For
a nominal attribute with m classes, unsupervisedNominalFilter returns
an nPatterns by m matrix. Each column of this matrix consists of zeros
and ones. The column value is set to zero if the pattern is not associated
with this classification; otherwise, the value is set to one indicating that
this pattern is associated with this classification.
Consider an example with one nominal variable that has two classes: male and female and five training patterns: male, male, female, male, female. With binary encoding, the following matrix is used as nominal network input to represent these patterns:
Continuous input attribute data, including ordinal data encoded to
cumulative percentages, are passed to this routine in a separate floating
point array, continuous. The number of rows in this array is
nPatterns. The number of columns is nContinuous. If the continuous
input attributes have widely different ranges, then typically it is
advantageous to scale these attributes before using them in network
training. The routine scaleFilter can be used for
scaling continuous input attributes before using it in network training.
Ordinal attributes can be encoded using
unsupervisedOrdinalFilter.
It is important to note that if input attributes are encoded or scaled for network training, then the network weights are calculated for that encoding and scaling. Subsequent pattern classifications using these weights must also use the identical encoding and scaling used during training.
Training pattern classification targets are stored in the one-dimensional
integer array classification. The i-th value in this array is the
class assignment for the i-th training pattern. Class assignments must
be represented using the integers 0, 1, …, nClasses - 1. This encoding is
arbitrary, but it should be consistent. For example, if the class
assignments correspond to the colors red, white and blue, then they must be
encoded as zero, one, and two. However, it is arbitrary whether red gets
assigned to class = 0, 1 or 2 provided that assignment is used for every
pattern.
Network Configuration¶
The network configuration consists of the following:
- number of inputs and outputs,
- number of hidden layers,
- description of the number of perceptrons in each layer,
- description of the linkages among the perceptrons, and
- initial values for network weights, including bias weights.
This description is passed into mlffClassificationTrainer using the
structure Imsls_d_NN_Network. See mlffNetwork.
Training Efficiency¶
INITIAL NETWORK WEIGHTS: The training efficiency determines the speed of
network training. This is controlled by several factors. One of the most
important factors is the initial weights used by the optimization algorithm.
By default, these are set randomly. Other options can be specified through
the optional argument weightInitializationMethod. See
mlffInitializeWeights for a detailed description of
the available initialization methods.
Initial weights are scaled to reduce the possibility of perceptron saturation during the initial phases of network training. Saturation occurs when initial perceptron potential calculations are so large, or so small, that the activation calculation for a potential is driven to the largest or smallest possible values that can be represented on the computer. If saturation occurs, warning messages may appear indicating that network training did not converge to an optimum solution.
The scaled initial weights are modified prior to every epoch by adding noise to these base values. The noise component is uniformly distributed over the interval [-0.5,+0.5].
SCALING INPUTS: Although automatic scaling of network weights protects against saturation during initial training iterations, the training algorithm can push the weights into regions that may cause saturation. Typically this occurs when input attributes have widely different scaling. For that reason, it is recommended to also scale all continuous input attributes to z-scores or a common interval, such as [-1, +1]. The routine scaleFilter can be used to scale continuous input attributes to z-scores or a common interval.
LOGISTIC CALCULATIONS: If Stage I training is slow, the optional argument
logisticTable can reduce this time by using a table lookup for
calculating the logistic activation function in hidden layer perceptrons.
This option is ignored during Stage II training. If Stage II training is
used, then weights for the optimum network will be calculated using exact
calculations for any logistic activation functions. If Stage II training is
not used and the logisticTable option is invoked, care must be taken to
ensure that this option is also used for any network classification
predictions using mlffPatternClassification.
NUMBER OF EPOCHS AND EPOCH SIZE: To ensure that a globally optimum network results from the training, several training sessions are conducted and compared. Each session is referred to as an epoch. The training for each epoch is conducted using all of the training patterns or a random sample of all available patterns.
Both the number of epochs and epoch size can be set using the stageI
option. By default the number of epochs during Stage I training is 15 and
the epoch size is equal to the total number of training patterns. Increasing
the number of epochs increases the training time, but it can result in a
more accurate classification network.
During Stage I training, the network entropy is calculated after each epoch.
If that value is smaller than tolerance Stage I training will stop since
it is assumed that a network with entropy that low is acceptably accurate,
and it is not necessary to continue training. The value for tolerance
can be set using the tolerance option. Setting this to a larger value,
such as 0.001, is useful for initially evaluating alternate network
architectures.
NETWORK SIZE AND VALIDATION: The network architecture, the number of perceptrons and network layers, also play a key role in network training. Larger networks with many inputs and perceptrons have a larger number of weights. Large networks can provide very accurate classifications, driving the misclassification error rate for the training patterns to zero. However networks with too many weights can take too long to train, and can be inaccurate for classifying patterns not adequately represented among the training patterns.
A starting point is to ensure the total number of network weights is approximately equal to the number of training patterns. A trained network of this size typically has a low misclassification error rate when calculated for the training patterns. That is, it is able to accurately reproduce the training data. However, it might be inaccurate for classifying other patterns.
One approach to this validation is to split the total number of training patterns into two or more subsets then train the network using only one of the subsets and classify the remaining data using the trained network. The misclassification error rate for the data not used in training will be a better estimate of the true classification error rate for this network.
However, this approach to validation is only possible when the number of training patterns is large.
Output¶
Output from mlffClassificationTrainer consists of classification
probabilities calculated for each training pattern, a classification error
array for these patterns, predicted classifications, weights and their
associated gradients for the trained network, and the training statistics.
The Imsls_d_NN_Network structure is automatically updated with the
weights, gradients and bias values for use as input to
mlffPatternClassification.
The trained network can be saved and retrieved using mlffNetworkWrite and mlffNetworkRead. For more details about the weights and bias values, see Table 13.8. These functions allow the functions of network training and classification to be implemented in different languages.
Examples¶
Example 1¶
This example trains a three-layer network using 48 training patterns with two nominal and two continuous input attributes. The first nominal attribute has three classifications and the second has four. Classifications for the nominal attributes are encoded using unsupervisedNominalFilter. This function uses binary encoding, generating a total of 7 input attributes to represent the two nominal attributes. The two additional continuous attributes increase the total number of network inputs to 9.
In this example, the target classification is binary, either zero or one. The continuous input attribute was scaled to the interval [0,1].
The structure of the network consists of nine input attributes in the input layer and three other layers. There are three perceptrons in the \(1^{st}\) hidden layer, and two in the \(2^{nd}\). Since the classification target in this example is binary, there is only one perceptron in the output layer.
All perceptrons use the logistic function for activation, including the output perceptron. Since logistic activation values are always between 0 and 1, the output from this network can be interpreted directly as the estimated probability, P(0), that a pattern belongs to target classification 0.
The following figure illustrates this structure:
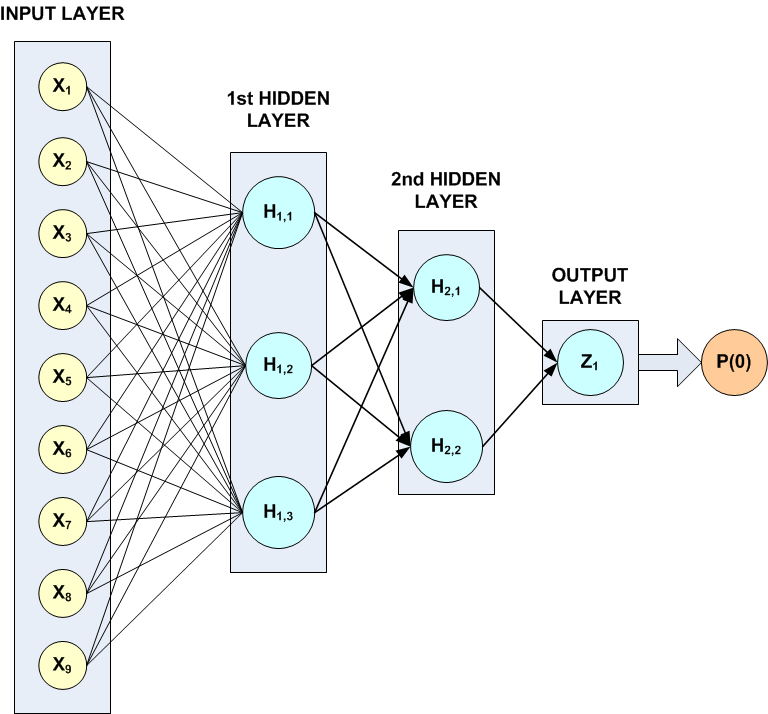
Figure 13.15 — A Binary 3-layer, Classification Network with 7 Inputs and 6 Perceptrons
There are a total of 41 weights in this network. Six are bias weights and the remaining 35 are the weights for the input links to every perceptron, e.g. \(35=9*3+3*2+2\).
Printing is turned on to show progress during the training session.
from __future__ import print_function
from numpy import *
from pyimsl.stat.ompOptions import ompOptions
from pyimsl.stat.unsupervisedNominalFilter import unsupervisedNominalFilter
from pyimsl.stat.mlffNetworkInit import mlffNetworkInit
from pyimsl.stat.mlffNetwork import mlffNetwork
from pyimsl.stat.mlffClassificationTrainer import mlffClassificationTrainer
from pyimsl.stat.randomSeedSet import randomSeedSet
from pyimsl.stat.writeMatrix import writeMatrix
n_patterns = 48 # number of training patterns
n_inputs = 9 # 2 nominal (7 classes) and 2 continuous
n_nominal = 7 # 2 attributes with 3 and 4 classes each
n_continuous = 2 # 2 continuous input attributes
n_outputs = 1 # binary classification
classification = empty(48, dtype=int)
nominalAtt = empty([48, 7], dtype=int)
n_cat = 2
nomTempIn = empty(48, dtype=int)
inputData = array(
[[0.00, 0.00, 0, 0, 0], [0.02, 0.02, 0, 1, 0], [0.04, 0.04, 0, 2, 0],
[0.06, 0.06, 0, 3, 0], [0.08, 0.08, 1, 0, 0], [0.10, 0.10, 1, 1, 0],
[0.12, 0.12, 1, 2, 0], [0.14, 0.14, 1, 3, 0], [0.16, 0.16, 2, 0, 0],
[0.18, 0.18, 2, 1, 0], [0.20, 0.20, 2, 2, 0], [0.22, 0.22, 2, 3, 0],
[0.24, 0.28, 0, 0, 0], [0.26, 0.30, 0, 1, 0], [0.28, 0.32, 0, 2, 0],
[0.30, 0.34, 0, 3, 0], [0.32, 0.36, 1, 0, 0], [0.34, 0.38, 1, 1, 0],
[0.36, 0.40, 1, 2, 0], [0.38, 0.42, 1, 3, 0], [0.40, 0.44, 2, 0, 0],
[0.42, 0.46, 2, 1, 0], [0.44, 0.48, 2, 2, 0], [0.46, 0.50, 2, 3, 0],
[0.52, 0.48, 0, 0, 0], [0.54, 0.50, 0, 1, 1], [0.56, 0.52, 0, 2, 1],
[0.58, 0.54, 0, 3, 1], [0.60, 0.56, 1, 0, 1], [0.62, 0.58, 1, 1, 1],
[0.64, 0.60, 1, 2, 1], [0.66, 0.62, 1, 3, 1], [0.68, 0.64, 2, 0, 0],
[0.70, 0.66, 2, 1, 0], [0.72, 0.68, 2, 2, 0], [0.74, 0.70, 2, 3, 0],
[0.76, 0.76, 0, 0, 1], [0.78, 0.78, 0, 1, 1], [0.80, 0.80, 0, 2, 1],
[0.82, 0.82, 0, 3, 1], [0.84, 0.84, 1, 0, 1], [0.86, 0.86, 1, 1, 1],
[0.88, 0.88, 1, 2, 1], [0.90, 0.90, 1, 3, 1], [0.92, 0.92, 2, 0, 0],
[0.94, 0.94, 2, 1, 0], [0.96, 0.96, 2, 2, 0], [0.98, 0.98, 2, 3, 0]])
contAtt = empty([48, 2])
colLabels = ["Pattern", "Class=0", "Class=1"]
network = []
print("***********************************")
print("* BINARY CLASSIFICATION EXAMPLE *")
print("***********************************\n")
ompOptions(setFunctionsThreadSafe=True)
# Setup Continuous Input Attributes and
# Classification Target Arrays
for i in range(0, n_patterns):
# Assign input to array for continuous input attributes
contAtt[i, 0] = inputData[i, 0]
contAtt[i, 1] = inputData[i, 1]
# Assign input to classification target array
classification[i] = inputData[i, 4]
# Setup Nominal Input Attributes Using Binary Encoding
m = 0
for i in range(0, n_cat):
for j in range(0, n_patterns):
nomTempIn[j] = inputData[j, n_continuous + i] + 1
nClass = []
nomTempOut = unsupervisedNominalFilter(nClass, nomTempIn)
for k in range(0, nClass[0]):
for j in range(0, n_patterns):
nominalAtt[j, k + m] = nomTempOut[j, k]
m = m + nClass[0]
print("\t TRAINING PATTERNS")
print("\tY N1 N2 Z1 Z2")
for i in range(0, n_patterns):
j = int(inputData[i, 2])
k = int(inputData[i, 3])
print("\t%d %d %d %g %g" % (classification[i], j, k,
contAtt[i, 0], contAtt[i, 1]))
print()
network = mlffNetworkInit(n_inputs, n_outputs)
mlffNetwork(network, createHiddenLayer=3)
mlffNetwork(network, createHiddenLayer=2, linkAll=True)
# Note the following statement is for repeatable output
randomSeedSet(5555)
# Train Classification Network
print("STARTING NETWORK TRAINING")
classProb = []
trainStats = mlffClassificationTrainer(network,
classification, nominalAtt, contAtt,
t_print=True, predictedClassProb=classProb)
# Print class predictions*/
writeMatrix("Predicted Classification Probabilities", classProb,
rowNumber=True, transpose=True, colLabels=colLabels)
Output¶
Notice that although by default the maximum number of epoch iterations in Stage I training is 15, in this case Stage I optimization is halted after the first epoch. This occurs because the minimum entropy for that epoch is less than the default tolerance.
TRAINING PARAMETERS:
Stage II Opt. = 1
n_epochs = 15
epoch_size = 48
maxIterations = 1000
maxFunctionEval = 1000
maxStep = 10.000000
functionTol = 3.66685e-11
gradientTol = 6.05545e-06
accuracy = 6.05545e-06
n_inputs = 9
n_continuous = 2
n_nominal = 7
n_classes = 2
n_outputs = 1
n_patterns = 48
n_layers = 3
n_perceptrons = 6
n_weights = 41
STAGE I TRAINING STARTING
Stage I: Epoch 1 - Cross-Entropy Error = 1.0803e-07 (Iterations=53)
(CPU Min.=0.000148)
Stage I Training Converged at Epoch = 1
STAGE I FINAL CROSS-ENTROPY ERROR = 0.000000 (CPU Min.=0.000150)
OPTIMUM WEIGHTS AFTER STAGE I TRAINING:
weight[0] = -1.34582 weight[1] = 3.64697
weight[2] = 0.482355 weight[3] = 3.78736
weight[4] = 0.572288 weight[5] = 0.234748
weight[6] = 0.24567 weight[7] = 2.48225
weight[8] = 2.41875 weight[9] = 5.11205
weight[10] = 3.57095 weight[11] = -14.733
weight[12] = -1.95642 weight[13] = 0.665544
weight[14] = -1.74797 weight[15] = -1.21224
weight[16] = 14.6843 weight[17] = 11.5164
weight[18] = 1.97324 weight[19] = 1.74357
weight[20] = -11.2846 weight[21] = -4.68242
weight[22] = -0.678394 weight[23] = 0.320807
weight[24] = -0.820023 weight[25] = 18.1349
weight[26] = 15.5616 weight[27] = -6.52965
weight[28] = -24.8296 weight[29] = -11.4105
weight[30] = -9.29376 weight[31] = -19.2789
weight[32] = -22.93 weight[33] = 30.8298
weight[34] = 15.1028 weight[35] = -7.19716
weight[36] = -15.8721 weight[37] = -17.223
weight[38] = 23.2718 weight[39] = 28.6847
weight[40] = -26.3842
STAGE I TRAINING CONVERGED
STAGE I CROSS-ENTROPY ERROR = 0.000000
0 PATTERNS OUT OF 48 INCORRECTLY CLASSIFIED
GRADIENT AT THE OPTIMUM WEIGHTS
-->g[0] = 0.000000 weight[0] = -1.345817
-->g[1] = -0.000000 weight[1] = 3.646967
-->g[2] = 0.000000 weight[2] = 0.482355
-->g[3] = 0.000000 weight[3] = 3.787364
-->g[4] = 0.000000 weight[4] = 0.572288
-->g[5] = 0.000000 weight[5] = 0.234748
-->g[6] = 0.000000 weight[6] = 0.245670
-->g[7] = 0.000000 weight[7] = 2.482253
-->g[8] = 0.000000 weight[8] = 2.418746
-->g[9] = 0.000000 weight[9] = 5.112054
-->g[10] = -0.000000 weight[10] = 3.570948
-->g[11] = 0.000000 weight[11] = -14.733006
-->g[12] = 0.000000 weight[12] = -1.956424
-->g[13] = 0.000000 weight[13] = 0.665544
-->g[14] = 0.000000 weight[14] = -1.747970
-->g[15] = 0.000000 weight[15] = -1.212241
-->g[16] = 0.000000 weight[16] = 14.684348
-->g[17] = 0.000000 weight[17] = 11.516433
-->g[18] = 0.000000 weight[18] = 1.973238
-->g[19] = -0.000000 weight[19] = 1.743570
-->g[20] = 0.000000 weight[20] = -11.284564
-->g[21] = -0.000000 weight[21] = -4.682422
-->g[22] = 0.000000 weight[22] = -0.678394
-->g[23] = 0.000000 weight[23] = 0.320807
-->g[24] = 0.000000 weight[24] = -0.820023
-->g[25] = 0.000000 weight[25] = 18.134880
-->g[26] = 0.000000 weight[26] = 15.561558
-->g[27] = -0.000000 weight[27] = -6.529653
-->g[28] = -0.000000 weight[28] = -24.829595
-->g[29] = -0.000000 weight[29] = -11.410472
-->g[30] = -0.000000 weight[30] = -9.293756
-->g[31] = 0.000000 weight[31] = -19.278897
-->g[32] = -0.000000 weight[32] = -22.930025
-->g[33] = -0.000000 weight[33] = 30.829818
-->g[34] = -0.000000 weight[34] = 15.102822
-->g[35] = 0.000000 weight[35] = -7.197161
-->g[36] = 0.000000 weight[36] = -15.872122
-->g[37] = 0.000000 weight[37] = -17.223002
-->g[38] = -0.000000 weight[38] = 23.271811
-->g[39] = -0.000000 weight[39] = 28.684695
-->g[40] = -0.000000 weight[40] = -26.384197
Training Completed - leaving training engine (CPU Min.=0.000154)
Predicted Classification Probabilities
Pattern Class=0
1 1
2 1
3 1
4 1
***********************************
* BINARY CLASSIFICATION EXAMPLE *
***********************************
TRAINING PATTERNS
Y N1 N2 Z1 Z2
0 0 0 0 0
0 0 1 0.02 0.02
0 0 2 0.04 0.04
0 0 3 0.06 0.06
0 1 0 0.08 0.08
0 1 1 0.1 0.1
0 1 2 0.12 0.12
0 1 3 0.14 0.14
0 2 0 0.16 0.16
0 2 1 0.18 0.18
0 2 2 0.2 0.2
0 2 3 0.22 0.22
0 0 0 0.24 0.28
0 0 1 0.26 0.3
0 0 2 0.28 0.32
0 0 3 0.3 0.34
0 1 0 0.32 0.36
0 1 1 0.34 0.38
0 1 2 0.36 0.4
0 1 3 0.38 0.42
0 2 0 0.4 0.44
0 2 1 0.42 0.46
0 2 2 0.44 0.48
0 2 3 0.46 0.5
0 0 0 0.52 0.48
1 0 1 0.54 0.5
1 0 2 0.56 0.52
1 0 3 0.58 0.54
1 1 0 0.6 0.56
1 1 1 0.62 0.58
1 1 2 0.64 0.6
1 1 3 0.66 0.62
0 2 0 0.68 0.64
0 2 1 0.7 0.66
0 2 2 0.72 0.68
0 2 3 0.74 0.7
1 0 0 0.76 0.76
1 0 1 0.78 0.78
1 0 2 0.8 0.8
1 0 3 0.82 0.82
1 1 0 0.84 0.84
1 1 1 0.86 0.86
1 1 2 0.88 0.88
1 1 3 0.9 0.9
0 2 0 0.92 0.92
0 2 1 0.94 0.94
0 2 2 0.96 0.96
0 2 3 0.98 0.98
STARTING NETWORK TRAINING
5 1
6 1
7 1
8 1
9 1
10 1
11 1
12 1
13 1
14 1
15 1
16 1
17 1
18 1
19 1
20 1
21 1
22 1
23 1
24 1
25 1
26 0
27 0
28 0
29 0
30 0
31 0
32 0
33 1
34 1
35 1
36 1
37 0
38 0
39 0
40 0
41 0
42 0
43 0
44 0
45 1
46 1
47 1
48 1
Example 2¶
Fisher’s (1936) Iris data is often used for benchmarking discriminant analysis and classification solutions. It is part of the IMSL data sets and consists of the following continuous input attributes and classification target:
Continuous Attributes – \(X_1\)(sepal length), \(X_2\)(sepal width), \(X_3\)(petal length), and \(X_4\)(petal width)
Classification Target (Iris Type) – Setosa, Versicolour or Virginica.
These data consist of 150 patterns. Since all pattern input attributes are
continuous, linear discriminant analysis can be used for classifying these
patterns, see Example 1 of
discriminantAnalysis. Linear discriminant analysis is able to correctly
classify 98% of the training patterns. In this example, the simple neural
network illustrated in the following figure is able to achieve 100%
accuracy.
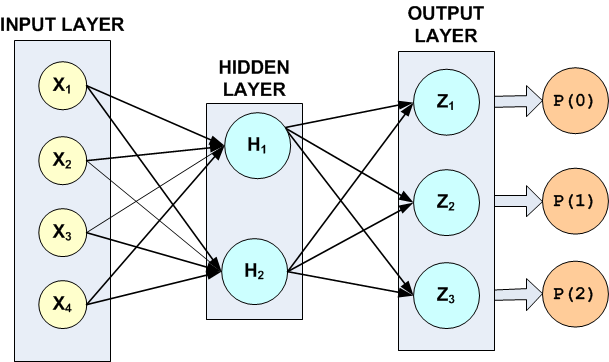
Figure 13.16 — A 2-layer, Classification Network with 4 Inputs 5 Perceptrons and a Target Classification with 3 Classes
The hidden layer in this example consists of only two perceptrons with logistic activation. Since the target attribute in this example has three classes, the network output layer consists of three perceptrons, one for each class.
There are a total of 19 weights in this network. Fourteen of the weights are
assigned to the input links, i.e., \(4\times 2+2\times 3=14\). The last
five weights are the bias weights for each of the five network perceptrons.
All weights were initialized using principal components, i.e., method =
PRINCIPAL_COMPONENTS.
Although in these data the continuous attributes have similar ranges, they were scaled using z‑score scaling to make network training more efficient. For more details, see scaleFilter.
For non-binary classification problems, mlffClassificationTrainer uses
softmax activation for output perceptrons. This ensures that the estimates
of the classification probabilities sum to one, i.e.,
Note that the default setting for maxStep was changed from 10 to 1000.
The default setting converged to a network with 100% classification
accuracy. However, the following warning message appeared:
WARNING Error IMSLS_UNBOUNDED from mlffClassificationTrainer.
Five consecutive steps of length "maxStep" have been taken;
either the function is unbounded below, or has a finite
asymptote in some direction or the maximum allowable step size
"maxStep" is too small.
In addition, the number of iterations used for each epoch were well below the default maximum (1000), and the gradients at the optimum solution for this network were not zero.
STAGE I TRAINING STARTING
Stage I: Epoch 1 - Cross-Entropy Error = 5.50552 (Iterations=40) (CPU Min.=0.000260)
Stage I: Epoch 2 - Cross-Entropy Error = 5.65875 (Iterations=69) (CPU Min.=0.000260)
Stage I: Epoch 3 - Cross-Entropy Error = 4.83886 (Iterations=81) (CPU Min.=0.000260)
Stage I: Epoch 4 - Cross-Entropy Error = 5.94979 (Iterations=108) (CPU Min.=0.000521)
Stage I: Epoch 5 - Cross-Entropy Error = 5.54461 (Iterations=47) (CPU Min.=0.000260)
Stage I: Epoch 6 - Cross-Entropy Error = 6.04163 (Iterations=51) (CPU Min.=0.000260)
Stage I: Epoch 7 - Cross-Entropy Error = 5.95148 (Iterations=151) (CPU Min.=0.000521)
Stage I: Epoch 8 - Cross-Entropy Error = 5.5646 (Iterations=55) (CPU Min.=0.000260)
Stage I: Epoch 9 - Cross-Entropy Error = 5.94914 (Iterations=442) (CPU Min.=0.001563)
Stage I: Epoch 10 - Cross-Entropy Error = 5.94381 (Iterations=271) (CPU Min.=0.001302)
Stage I: Epoch 11 - Cross-Entropy Error = 5.41955 (Iterations=35) (CPU Min.=0.000000)
Stage I: Epoch 12 - Cross-Entropy Error = 6.01766 (Iterations=48) (CPU Min.=0.000260)
Stage I: Epoch 13 - Cross-Entropy Error = 4.20551 (Iterations=112) (CPU Min.=0.000521)
Stage I: Epoch 14 - Cross-Entropy Error = 5.95085 (Iterations=103) (CPU Min.=0.000260)
Stage I: Epoch 15 - Cross-Entropy Error = 5.9596 (Iterations=55) (CPU Min.=0.000260)
Stage I: Epoch 16 - Cross-Entropy Error = 5.96131 (Iterations=59) (CPU Min.=0.000260)
Stage I: Epoch 17 - Cross-Entropy Error = 4.83231 (Iterations=74) (CPU Min.=0.000260)
Stage I: Epoch 18 - Cross-Entropy Error = 17.1345 (Iterations=30) (CPU Min.=0.000260)
Stage I: Epoch 19 - Cross-Entropy Error = 5.95569 (Iterations=92) (CPU Min.=0.000260)
Stage I: Epoch 20 - Cross-Entropy Error = 3.15336 (Iterations=46) (CPU Min.=0.000260)
GRADIENT AT THE OPTIMUM WEIGHTS
-->g[0] = 0.675632 weight[0] = 0.075861
-->g[1] = -0.953480 weight[1] = -0.078585
-->g[2] = 1.065184 weight[2] = 2.841074
-->g[3] = 0.535531 weight[3] = -0.941049
-->g[4] = -0.019011 weight[4] = -10.638772
-->g[5] = 0.001459 weight[5] = -14.573394
-->g[6] = -0.031098 weight[6] = 6.037813
-->g[7] = -0.035305 weight[7] = 72.382073
-->g[8] = 0.011015 weight[8] = -73.564433
-->g[9] = 0.000000 weight[9] = -14.853988
-->g[10] = -0.074332 weight[10] = 2.057743
-->g[11] = 0.000522 weight[11] = -39.952435
-->g[12] = 0.063316 weight[12] = 73.164141
-->g[13] = -0.000522 weight[13] = 57.065975
-->g[14] = 1.279914 weight[14] = -0.661036
-->g[15] = -0.043097 weight[15] = -61.171894
-->g[16] = 0.003227 weight[16] = 24.236722
-->g[17] = -0.108146 weight[17] = 14.968424
-->g[18] = 0.104919 weight[18] = -39.079343
Combined, this information suggests that either the default tolerances were too high or the maximum step size was too small. As shown in the output below, when the maximum step size was changed to 1000, the number of iterations increased, the gradients went to zero and the warning message for step size disappeared.
from __future__ import print_function
from numpy import *
from pyimsl.stat.ompOptions import ompOptions
from pyimsl.stat.dataSets import dataSets
from pyimsl.stat.ctime import ctime
from pyimsl.stat.scaleFilter import scaleFilter
from pyimsl.stat.mlffNetworkInit import mlffNetworkInit
from pyimsl.stat.mlffNetwork import mlffNetwork
from pyimsl.stat.mlffClassificationTrainer import mlffClassificationTrainer
from pyimsl.stat.mlffClassificationTrainer import PRINCIPAL_COMPONENTS
from pyimsl.stat.randomSeedSet import randomSeedSet
from pyimsl.stat.mlffNetworkWrite import mlffNetworkWrite
# Two Layer Feed-Forward Network with 4 inputs, all
# continuous, and 3 classification categories.
#
# This is a well known database to be found in the pattern
# recognition literature. Fisher's paper is often cited.
# The data set contains 3 classes of 50 instances each,
# where each class refers to a type of iris plant. One class is
# linearly separable from the other 2; the latter are NOT linearly
# separable from each other.
#
# Predicted attribute: class of iris plant.
# 1=Iris Setosa, 2=Iris Versicolour, and 3=Iris Virginica
#
# Input Attributes (4 Continuous Attributes)
# X1: Sepal length,
# X2: Sepal width,
# X3: Petal length,
# and X4: Petal width
n_patterns = 150
n_inputs = 4 # all continuous inputs
n_nominal = 0 # no nominal
n_continuous = 4
n_outputs = 3
act_fcn = [1, 1, 1]
classification = empty(150, dtype=int)
unscaledX = empty(150)
scaledX = empty(150)
contAtt = empty([150, 4])
dmean = empty(4)
s = empty(4)
colLabels = ["Pattern", "Class=0", "Class=1", "Class=2"]
prtLabel = "Predicted_Class | P(0) P(1) P(2) | Class_Error"
dashes = "-------------------------------------------------------------"
filename = "iris_classification.txt"
print("*******************************************************")
print("* IRIS CLASSIFICATION EXAMPLE *")
print("*******************************************************")
ompOptions(setFunctionsThreadSafe=True)
# irisData[]: The raw data matrix. This is a 2-D matrix with 150
# rows and 5 columns. The last 4 columns are the
# continuous input attributes and the 1st column is
# the classification category (1-3). These data
# contain no nominal input attributes.
irisData = dataSets(3)
# Setup the continuous attribute input array, contAtt[], and the
# network target classification array, classification[], using the
# above raw data matrix.
for i in range(0, n_patterns):
classification[i] = irisData[i, 0] - 1
for j in range(1, 5):
contAtt[i, j - 1] = irisData[i, j]
# Scale continuous input attributes using z-score method
center_spread = {}
for j in range(0, n_continuous):
for i in range(0, n_patterns):
unscaledX[i] = contAtt[i, j]
scaledX = scaleFilter(unscaledX, 2, returnCenterSpread=center_spread)
for i in range(0, n_patterns):
contAtt[i, j] = scaledX[i]
dmean[j] = center_spread['center']
s[j] = center_spread['spread']
print("Scale Parameters:")
for j in range(0, n_continuous):
print("Var %d Mean = %f S = %f" % (j + 1, dmean[j], s[j]))
network = mlffNetworkInit(n_inputs, n_outputs)
mlffNetwork(network, createHiddenLayer=2, linkAll=True)
# Note the following statement is for repeatable output
randomSeedSet(5555)
# Train Classification Network
predicted_class = []
predicted_class_prob = []
class_error = []
startTime = ctime()
trainStats = mlffClassificationTrainer(network, classification, None, contAtt,
t_print=True,
stageI={'nEpochs': 20,
'epochSize': 150},
weightInitializationMethod=PRINCIPAL_COMPONENTS,
maxStep=1000.0,
predictedClass=predicted_class,
predictedClassProb=predicted_class_prob,
classError=class_error)
endTime = ctime()
print(dashes)
print("Minimum Cross-Entropy Error: %g" % trainStats[0])
print("Classification Error Rate: %f" % trainStats[5])
print("Execution Time (Sec.): %f\n" % (endTime - startTime))
print(prtLabel)
print(dashes)
for i in range(0, n_patterns):
print(" %d " % predicted_class[i], end=' ')
print(" | %f %f %f | %f" %
(predicted_class_prob[i][0],
predicted_class_prob[i][1],
predicted_class_prob[i][2],
class_error[i]))
if (i == 49) | (i == 99):
print(prtLabel)
print(dashes)
mlffNetworkWrite(network, filename)
Output¶
Note that the misclassification error rate is zero and Stage I training halts automatically at the \(16^{th}\) epoch because the cross-entropy error after the \(16^{th}\) epoch is below the default tolerance.
*******************************************************
* IRIS CLASSIFICATION EXAMPLE *
*******************************************************
Scale Parameters:
Var 1 Mean = 5.843333 S = 0.828066
Var 2 Mean = 3.057333 S = 0.435866
Var 3 Mean = 3.758000 S = 1.765298
Var 4 Mean = 1.199333 S = 0.762238
-------------------------------------------------------------
Minimum Cross-Entropy Error: 3.50183e-10
Classification Error Rate: 0.000000
Execution Time (Sec.): 0.806169
Predicted_Class | P(0) P(1) P(2) | Class_Error
-------------------------------------------------------------
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
0 | 1.000000 0.000000 0.000000 | 0.000000
Predicted_Class | P(0) P(1) P(2) | Class_Error
-------------------------------------------------------------
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
1 | 0.000000 1.000000 0.000000 | 0.000000
Predicted_Class | P(0) P(1) P(2) | Class_Error
-------------------------------------------------------------
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
2 | 0.000000 0.000000 1.000000 | 0.000000
TRAINING PARAMETERS:
Stage II Opt. = 1
n_epochs = 20
epoch_size = 150
maxIterations = 1000
maxFunctionEval = 1000
maxStep = 1000.000000
functionTol = 3.66685e-11
gradientTol = 6.05545e-06
accuracy = 6.05545e-06
n_inputs = 4
n_continuous = 4
n_nominal = 0
n_classes = 3
n_outputs = 3
n_patterns = 150
n_layers = 2
n_perceptrons = 5
n_weights = 19
STAGE I TRAINING STARTING
Stage I: Epoch 1 - Cross-Entropy Error = 4.92196 (Iterations=85)
(CPU Min.=0.000267)
Stage I: Epoch 2 - Cross-Entropy Error = 5.94939 (Iterations=500)
(CPU Min.=0.001363)
Stage I: Epoch 3 - Cross-Entropy Error = 5.94936 (Iterations=500)
(CPU Min.=0.001332)
Stage I: Epoch 4 - Cross-Entropy Error = 4.90196 (Iterations=225)
(CPU Min.=0.000635)
Stage I: Epoch 5 - Cross-Entropy Error = 4.92196 (Iterations=116)
(CPU Min.=0.000337)
Stage I: Epoch 6 - Cross-Entropy Error = 5.94948 (Iterations=501)
(CPU Min.=0.001339)
Stage I: Epoch 7 - Cross-Entropy Error = 5.94938 (Iterations=500)
(CPU Min.=0.001288)
Stage I: Epoch 8 - Cross-Entropy Error = 4.92196 (Iterations=92)
(CPU Min.=0.000251)
Stage I: Epoch 9 - Cross-Entropy Error = 5.92509 (Iterations=500)
(CPU Min.=0.001441)
Stage I: Epoch 10 - Cross-Entropy Error = 5.92346 (Iterations=501)
(CPU Min.=0.001383)
Stage I: Epoch 11 - Cross-Entropy Error = 4.92196 (Iterations=83)
(CPU Min.=0.000225)
Stage I: Epoch 12 - Cross-Entropy Error = 4.92196 (Iterations=102)
(CPU Min.=0.000265)
Stage I: Epoch 13 - Cross-Entropy Error = 4.92196 (Iterations=86)
(CPU Min.=0.000237)
Stage I: Epoch 14 - Cross-Entropy Error = 5.94933 (Iterations=500)
(CPU Min.=0.001310)
Stage I: Epoch 15 - Cross-Entropy Error = 5.94835 (Iterations=500)
(CPU Min.=0.001332)
Stage I: Epoch 16 - Cross-Entropy Error = 3.50183e-10 (Iterations=147)
(CPU Min.=0.000395)
Stage I Training Converged at Epoch = 16
STAGE I FINAL CROSS-ENTROPY ERROR = 0.000000 (CPU Min.=0.013406)
OPTIMUM WEIGHTS AFTER STAGE I TRAINING:
weight[0] = -0.166269 weight[1] = -0.0601452
weight[2] = 5.05817 weight[3] = -2.03579
weight[4] = 12.9718 weight[5] = -1815.62
weight[6] = 4050.37 weight[7] = 8952.1
weight[8] = -11100 weight[9] = 58.9269
weight[10] = 292.009 weight[11] = -4111.14
weight[12] = 10810 weight[13] = 4054
weight[14] = 0.781056 weight[15] = -9686.52
weight[16] = 5567.41 weight[17] = 2345.55
weight[18] = -7912.98
STAGE I TRAINING CONVERGED
STAGE I CROSS-ENTROPY ERROR = 0.000000
0 PATTERNS OUT OF 150 INCORRECTLY CLASSIFIED
GRADIENT AT THE OPTIMUM WEIGHTS
-->g[0] = -0.000000 weight[0] = -0.166269
-->g[1] = 0.000000 weight[1] = -0.060145
-->g[2] = -0.000000 weight[2] = 5.058172
-->g[3] = -0.000000 weight[3] = -2.035791
-->g[4] = -0.000000 weight[4] = 12.971772
-->g[5] = 0.000000 weight[5] = -1815.617834
-->g[6] = -0.000000 weight[6] = 4050.366015
-->g[7] = -0.000000 weight[7] = 8952.101381
-->g[8] = 0.000000 weight[8] = -11099.966822
-->g[9] = 0.000000 weight[9] = 58.926926
-->g[10] = 0.000000 weight[10] = 292.009234
-->g[11] = 0.000000 weight[11] = -4111.135126
-->g[12] = -0.000000 weight[12] = 10809.980483
-->g[13] = 0.000000 weight[13] = 4053.998430
-->g[14] = -0.000000 weight[14] = 0.781056
-->g[15] = -0.000000 weight[15] = -9686.516577
-->g[16] = 0.000000 weight[16] = 5567.410972
-->g[17] = 0.000000 weight[17] = 2345.547326
-->g[18] = -0.000000 weight[18] = -7912.984006
Training Completed - leaving training engine (CPU Min.=0.013410)